In der objektorientierten Programmierung stehen nicht mehr die Funktionen, sondern die Objekte im Vordergrund. Dennoch sind Funktionen immer noch unerläßlicher Bestandteil eines jeden Programms. Heute lernen Sie,
Eine Funktion ist praktisch ein Unterprogramm, das Daten verarbeitet und einen Wert
zurückgibt. Jedes C++-Programm hat zumindest eine Funktion: main(). Beim Start
des Programms wird main() automatisch aufgerufen. In main() können andere Funktionsaufrufe
stehen, die wiederum andere Funktionen aufrufen können.
Jede Funktion hat einen eigenen Namen. Gelangt die Programmausführung zu einer Anweisung mit diesem Namen, verzweigt das Programm in den Rumpf der betreffenden Funktion. Man spricht dann davon, daß die Funktion aufgerufen wird. Bei der Rückkehr aus der Funktion wird das Programm mit der nächsten Zeile nach dem Funktionsaufruf fortgesetzt. Abbildung 5.1 verdeutlicht diesen Ablauf.
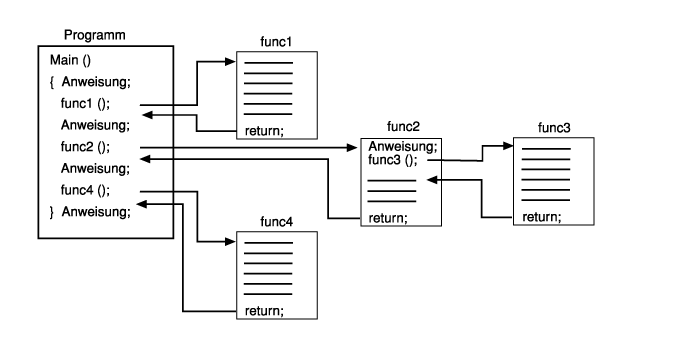
Abbildung 5.1: Ruft ein Programm eine Funktion auf, springt die Ausführung zur Funktion und fährt nach Rückkehr aus der Funktion mit der Zeile nach dem Funktionsaufruf fort.
Eine gut konzipierte Funktion führt eine klar abgegrenzte Aufgabe aus - nicht mehr und nicht weniger - und kehrt dann zurück. Komplexere Aufgaben sollte man auf mehrere Funktionen aufteilen und diese Funktionen dann jeweils aufrufen.
Dabei gibt es zwei Arten von Funktionen: benutzerdefinierte und mitgelieferte. Mitgelieferte Funktionen sind Teil Ihres Compiler-Pakets, die Ihnen vom Hersteller zur Verfügung gestellt werden. Benutzerdefinierte Funktionen sind Funktionen, die Sie selbst aufsetzen.
Funktionen können einen Wert zurückgeben. Wenn Sie eine Funktion aufrufen, kann sie eine Aufgabe abarbeiten und dann als Ergebnis einen Wert zurückliefern. Dieser Wert wird auch Rückgabewert genannt. Der Typ dieses Rückgabewertes muß deklariert werden. Wenn Sie also schreiben:
int meineFunktion();
deklarieren Sie den Rückgabewert dieser Funktion als Integer-Wert.
Sie können auch Werte an Funktionen übergeben. Die Beschreibung der Werte, die übergeben werden, nennt man Parameterliste.
in meineFunktion (in EinWert, float EineFliesskommazahl);
Die Deklaration besagt, daß meineFunktion() nicht nur einen Integer zurückliefert,
sondern auch einen Integer und eine Fließkommazahl als Parameter übernimmt.
Ein Parameter beschreibt den Typ des Wertes, der der Funktion bei Aufruf übergeben wird. Die eigentlichen Werte, die der Funktion übergeben werden, nennt man auch Argumente.
int derRückgabewert = meineFunktion(5,6,7);
In diesem Beispiel sehen wir, wie die Integer-Variable derRückgabewert mit dem Rückgabewert
der Funktion meineFunktion() initialisiert wird und wie die Werte 5, 6 und 7
als Argumente übergeben werden. Die Typen der Argumente müssen mit den deklarierten
Parametertypen übereinstimmen.
Bevor man eine Funktion verwenden kann, muß man sie zuerst deklarieren und dann definieren. Die Deklaration teilt dem Compiler den Namen, den Rückgabetyp und die Parameter der Funktion mit. Die Definition teilt dem Compiler die Arbeitsweise der Funktion mit. Keine Funktion läßt sich von irgendeiner anderen Funktion aufrufen, wenn sie nicht zuerst deklariert wurde. Die Deklaration einer Funktion bezeichnet man als Prototyp.
Es gibt drei Möglichkeiten, eine Funktion zu deklarieren:
#include-Direktive in Ihr Programm auf.
Sie können zwar eine Funktion vor ihrer Verwendung definieren und so die unerläßliche Erzeugung eines Funktionsprototypen umgehen, aber guter Programmierstil ist dies aus drei Gründen nicht.
Erstens ist es nicht gerade empfehlenswert, Funktionen in einer Datei in einer bestimmten Reihenfolge anzuordnen. Damit wird die Wartung des Programms als Folge sich ändernder Anforderungen wesentlich erschwert.
Zweitens kann es vorkommen, daß Funktion A die Funktion B aufrufen muß, Funktion
B aber wiederum unter bestimmten Bedingungen in der Lage sein muß, Funktion A
aufzurufen. Es ist nicht möglich, Funktion A vor Funktion B zu definieren und Funktion
B vor Funktion A zu definieren. Eine der Funktionen muß auf alle Fälle deklariert werden.
Drittens sind Funktionsprototypen eine gute und mächtige Debugging-Technik. Wenn die Deklaration Ihres Prototyps vorsieht, daß Ihre Funktion einen bestimmten Parametersatz übernimmt oder einen bestimmten Typ als Rückgabewert zurückliefert und dann Ihre Funktion nicht mit dem Prototyp übereinstimmt, kann der Compiler eine Fehlermeldung ausgeben, und Sie müssen nicht warten, bis der Fehler bei der Programmausführung auftaucht.
Viele der zum Lieferumfang des Compilers gehörenden Funktionen besitzen bereits
einen Prototyp in den Dateien, die Sie mit der #include-Anweisung in Ihr Programm
einbinden. Für Funktionen, die Sie selbst schreiben, müssen Sie den Prototyp auch
selbst mit aufnehmen.
Der Prototyp einer Funktion ist eine Anweisung, die demzufolge auch mit einem Semikolon endet. Er besteht aus dem Rückgabetyp und der Signatur der Funktion. Unter einer Signatur versteht man den Namen und die Parameterliste der Funktion.
Die Parameterliste führt - durch Komma getrennt - alle Parameter mit deren Typen auf. Abbildung 5.2 zeigt die verschiedenen Teile eines Funktionsprototyps.
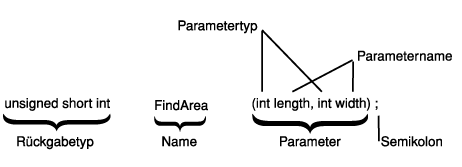
Abbildung 5.2: Teile eines Funktionsprototypen
Der Prototyp und die Definition einer Funktion müssen hinsichtlich Rückgabetyp und Signatur genau übereinstimmen. Andernfalls erhält man einen Compiler-Fehler. Allerdings müssen im Prototyp der Funktion nur die Typen und nicht die Namen der Parameter erscheinen. Das folgende Beispiel zeigt einen zulässigen Prototypen:
long Area(int, int);
Dieser Prototyp deklariert eine Funktion namens Area (Fläche), die einen Wert vom
Typ long zurückgibt und zwei ganzzahlige Parameter aufweist. Diese Anweisung ist
zwar zulässig, aber nicht empfehlenswert. Mit hinzugefügten Parameternamen ist der
Prototyp verständlicher. Dieselbe Funktion könnte mit benannten Parametern folgendes
Aussehen haben:
long Area(int laenge, int breite);
Daraus läßt sich ohne weiteres erkennen, welche Aufgabe die Funktion hat und welche Parameter zu übergeben sind.
Beachten Sie, daß alle Funktionen einen Rückgabetyp haben. Wird kein spezieller
Rückgabetyp angegeben, geht man standardmäßig von einem Integer aus. Ihre Programme
sind jedoch leichter zu verstehen, wenn Sie generell für alle Funktionen, einschließlich
main() den Rückgabetyp explizit angeben. Listing 5.1 zeigt ein Programm,
das den Funktionsprototyp für die Funktion Area() verwendet.
Listing 5.1: Deklaration, Definition und Verwendung einer Funktion
1: // Listing 5.1 - Zeigt die Verwendung von Funktionsprototypen
2:
3: #include <iostream.h>
4: int Area(int length, int width); // Funktionsprototyp
5:
6: int main()
7: {
8: int lengthOfYard;
9: int widthOfYard;
10: int areaOfYard;
11:
12: cout << "\nWie breit ist Ihr Garten? ";
13: cin >> widthOfYard;
14: cout << "\nWie lang ist Ihr Garten? ";
15: cin >> lengthOfYard;
16:
17: areaOfYard= Area(lengthOfYard,widthOfYard);
18:
19: cout << "\nDie Flaeche Ihres Gartens betraegt ";
20: cout << areaOfYard;
21: cout << " Quadratmeter\n\n";
22: return 0;
23: }
24:
25: int Area(int l, int w)
26: {
27: return yardLength * yardWidth;
28: }
Wie breit ist Ihr Garten? 100
Wie lang ist Ihr Garten? 200
Die Flaeche Ihres Gartens betraegt 20000 Quadratmeter
Der Prototyp für die Funktion Area() steht in Zeile 4. Vergleichen Sie den Prototypen
mit der Definition der Funktion in Zeile 25. Beachten Sie, daß Name, Rückgabetyp
und die Parametertypen identisch sind. Andernfalls erhält man einen Compiler-Fehler.
Praktisch besteht der einzige Unterschied darin, daß der Prototyp einer Funktion mit
einem Semikolon endet und keinen Rumpf aufweist.
Weiterhin fällt auf, daß die Parameternamen im Prototypen mit length und width angegeben
sind, während die Definition yardLength und yardWidth verwendet. Die Namen
im Prototyp sind nicht erforderlich und dienen nur als Information für den Programmierer.
Es ist zwar nicht zwingend notwendig, aber guter Programmierstil, die
Parameternamen im Prototyp in Übereinstimmung mit den Parameternamen der
Funktionsdefinition zu wählen.
Die Argumente übergibt man an die Funktion in der Reihenfolge, in der sie deklariert
und definiert sind. Es wird kein Abgleich der Namen vorgenommen! Hätten Sie zuerst
widthOfYard und dann lengthOfYard übergeben, hätte die Funktion Area() den Wert
von widthOfYard für YardLength und von lengthOfYard für yardWidth verwendet. Der
Rumpf der Funktion ist immer von geschweiften Klammern eingeschlossen, auch
wenn er, wie in diesem Fall, nur aus einer Anweisung besteht.
Die Definition einer Funktion besteht aus dem Funktionskopf und ihrem Rumpf. Der Kopf entspricht genau dem Prototypen der Funktion, außer daß die Parameter benannt sein müssen und kein abschließendes Semikolon angehängt wird.
Der Rumpf der Funktion ist eine Gruppe von Anweisungen, die in geschweifte Klammern eingeschlossen sind. Abbildung 5.3 zeigt den Kopf und Rumpf einer Funktion.
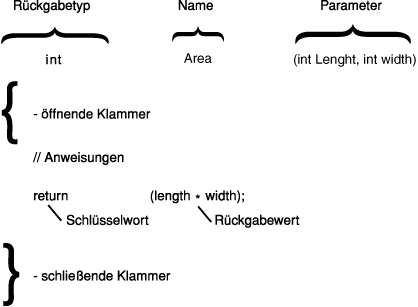
Abbildung 5.3: Kopf und Rumpf einer Funktion
Syntax des Funktionsprototypen:
rueckgabetyp funktionsname ( [typ parameterName]...)
{
Anweisungen;
}Ein Funktionsprototyp gibt dem Compiler den Namen, den Rückgabewert und die Parameterliste der Funktion an. Funktionen müssen keine Parameter aufweisen. Falls Parameter vorkommen, müssen sie nicht als Namen im Prototyp erscheinen, sondern nur als Typ. Ein Prototyp endet immer mit einem Semikolon (;).
Eine Funktionsdefinition muß hinsichtlich Rückgabetyp und Parameterliste mit ihrem Prototypen übereinstimmen. Sie muß die Namen für alle Parameter bereitstellen, und der Rumpf der Funktionsdefinition ist in geschweifte Klammern einzuschließen. Alle Anweisungen innerhalb des Rumpfes der Funktion müssen mit Semikolon abgeschlossen sein, wohingegen die Funktion selbst nicht mit einem Semikolon, sondern mit einer schließenden geschweiften Klammer beendet wird.
Wenn die Funktion einen Rückgabewert liefert, sollte sie mit einer
return-Anweisung enden.return-Anweisungen sind aber auch an beliebigen Stellen innerhalb des Funktionsrumpfes zulässig.Jede Funktion hat einen Rückgabetyp. Gibt man keinen Typ explizit an, wird
intangenommen. Man sollte für jede Funktion explizit einen Rückgabetyp festlegen. Gibt eine Funktion keinen Wert zurück, lautet der Rückgabetypvoid.Beispiele für Funktionsprototypen:
long FindArea(long length, long width); // gibt long zurück, hat zwei Parameter
void PrintMessage(int messageNumber); // gibt void zurück, hat einen Parameter
int GetChoice(); // gibt int zurück, hat keine Parameter
BadFunction(); // gibt int zurück, hat keine ParameterBeispiele für Funktionsdefinitionen:
long FindArea(long l, long w)
{
return l * w;
}
void PrintMessage(int whichMsg)
{
if (whichMsg == 0)
cout << "Hallo.\n";
if (whichMsg == 1)
cout << "Auf Wiedersehen.\n";
if (whichMsg > 1)
cout << "Was ist los?\n";
}
Bei Aufruf einer Funktion beginnt die Ausführung der Funktion mit der ersten Anweisung
nach der öffnenden geschweiften Klammer({). Innerhalb der Funktion kann mit
der if-Anweisung (und weiteren, verwandten Anweisungen, auf die wir am Tag 7
»Mehr zur Programmsteuerung« noch näher eingehen werden) verzweigt werden.
Funktionen können andere Funktionen und sogar sich selbst aufrufen (dazu im Abschnitt
»Rekursion« weiter hinten in diesem Kapitel mehr).
Man kann an eine Funktion nicht nur Variablen übergeben, sondern auch Variablen innerhalb des Funktionsrumpfes deklarieren. Diese sogenannten lokalen Variablen existieren nur innerhalb der Funktion selbst. Wenn die Funktion zurückkehrt, sind die lokalen Variablen nicht mehr verfügbar.
Lokale Variablen definiert man wie jede andere Variable auch. Die an eine Funktion übergebenen Parameter gelten ebenfalls als lokale Variablen und lassen sich genauso verwenden, als hätte man sie innerhalb des Funktionsrumpfes definiert. Listing 5.2 zeigt ein Beispiel für die Verwendung von Parametern und lokal definierten Variablen innerhalb einer Funktion.
Listing 5.2: Lokale Variablen und Parameter
1: #include <iostream.h>
2:
3: float Convert(float);
4: int main()
5: {
6: float TempFer;
7: float TempCel;
8:
9: cout << "Bitte Temperatur in Fahrenheit eingeben: ";
10: cin >> TempFer;
11: TempCel = Convert(TempFer);
12: cout << "\nDie Temperatur in Grad Celsius ist: ";
13: cout << TempCel << endl;
14: return 0;
15: }
16:
17: float Convert(float TempFer)
18: {
19: float TempCel;
20: TempCel = ((TempFer - 32) * 5) / 9;
21: return TempCel;
22: }
Bitte Temperatur in Fahrenheit eingeben: 212
Die Temperatur in Grad Celsius ist: 100
Bitte Temperatur in Fahrenheit eingeben: 32
Die Temperatur in Grad Celsius ist: 0
Bitte Temperatur in Fahrenheit eingeben: 85
Die Temperatur in Grad Celsius ist: 29.4444
Die Zeilen 6 und 7 deklarieren zwei Variablen vom Typ float. Eine nimmt die Temperatur
in Fahrenheit auf und eine die Temperatur in Grad Celsius. Die Anweisung in
Zeile 9 fordert den Benutzer auf, eine Temperatur in Fahrenheit einzugeben. Dieser
Wert wird an die Funktion Convert()übergeben.
Die Ausführung springt zur ersten Zeile der Funktion Convert() in Zeile 19, wo eine
lokale Variable, die ebenfalls TempCel genannt wurde, deklariert wird. Beachten Sie,
daß diese lokale Variable nichts mit der in Zeile 7 deklarierten Variablen TempCel zu
tun hat. Diese Variable existiert nur innerhalb der Funktion Convert(). Der als Parameter
TempFer übergebene Wert ist ebenfalls lediglich eine lokale Kopie der durch
main() übergebenen Variablen.
Man könnte den Parameter der Funktion mit FerTemp und die lokale Variable mit CelTemp
benennen, ohne daß sich an der Arbeitsweise des Programms irgend etwas ändern
würde. Überzeugen Sie sich davon, indem Sie diese Namen eingeben und das
Programm erneut kompilieren.
Der lokalen Variablen TempCel der Funktion wird der Wert zugewiesen, der aus der
Subtraktion des Wertes 32 vom Parameter TempFer, der Multiplikation mit 5 und der
Division durch 9 resultiert. Diesen Wert liefert die Funktion als Rückgabewert zurück,
und Zeile 11 weist ihn der Variablen TempCel der Funktion main() zu. Die Ausgabe erfolgt
in Zeile 13.
Das Programm wird dreimal ausgeführt. Beim ersten Mal übergibt man den Wert 212,
um zu prüfen, daß der Siedepunkt des Wassers in Grad Fahrenheit (212) die korrekte
Antwort in Grad Celsius (100) generiert. Der zweite Test bezieht sich auf den Gefrierpunkt
des Wassers. Der dritte Test verwendet eine willkürliche Zahl, um ein gebrochenes
Ergebnis zu erzeugen.
Zur Übung können Sie das Programm wie im folgenden Beispiel mit anderen Namen erneut eingeben:
1: #include <iostream.h>
2:
3: float Convert(float);
4: int main()
5: {
6: float TempFer;
7: float TempCel;
8:
9: cout << " Bitte Temperatur in Fahrenheit eingeben: ";
10: cin >> TempFer;
11: TempCel = Convert(TempFer);
12: cout << "\nDie Temperatur in Grad Celsius ist: ";
13: cout << TempCel << endl;
14: return 0;
15: }
16:
17: float Convert(float Fer)
18: {
19: float Cel;
20: Cel = ((Fer - 32) * 5) / 9;
21: return Cel;
22: }
Die Ergebnisse sollten dieselben sein.
Zu einer Variablen gehört ein Gültigkeitsbereich. Dieser bestimmt, wie lange eine Variable in einem Programm zugänglich ist und wo man auf sie zugreifen kann. Der Gültigkeitsbereich einer in einem Block deklarierten Variablen beschränkt sich auf diesen Block. Nur innerhalb dieses Blocks kann man auf die Variable zugreifen, außerhalb des Blocks »verschwindet« sie. Globale Variablen besitzen einen globalen Gültigkeitsbereich und sind an allen Stellen eines Programms zugänglich.
Normalerweise ist der Gültigkeitsbereich ohne weiteres erkennbar. Allerdings gibt es
einige verzwickte Ausnahmen. Doch dazu werden Sie mehr erfahren, wenn wir am
Tag 7 die for-Schleifen besprechen. Solange Sie darauf achten, in Ihren Funktionen
keine bereits gebrauchten Variablennamen zu verwenden, spielen obige Betrachtungen
allerdings keine besondere Rolle.
Variablen, die außerhalb aller Funktionen definiert sind, gehören dem globalen Gültigkeitsbereich
an und sind daher für jede Funktion im Programm einschließlich der
Funktion main() verfügbar.
Lokale Variablen mit gleichem Namen wie globale Variablen ändern diese nicht - vielmehr verstecken sie die globalen Variablen. Wurde in einer Funktion eine Variable mit dem Namen einer globalen Variablen deklariert, bezieht sich der Name - innerhalb der Funktion - nur auf die lokale und nicht auf die globale Variable. Listing 5.3 soll dieses illustrieren:
Listing 5.3: Globale und lokale Variablen
1: #include <iostream.h>
2: void myFunction(); // Prototyp
3:
4: int x = 5, y = 7; // globale Variablen
5: int main()
6: {
7:
8: cout << "x von main: " << x << "\n";
9: cout << "y von main: " << y << "\n\n";
10: myFunction();
11: cout << "Zurück aus myFunction!\n\n";
12: cout << "x von main: " << x << "\n";
13: cout << "y von main: " << y << "\n";
14: return 0;
15: }
16:
17: void myFunction()
18: {
19: int y = 10;
20:
21: cout << "x von myFunction: " << x << "\n";
22: cout << "y von myFunction: " << y << "\n\n";
23: }
x von main: 5
y von main: 7
x von myFunction: 5
y von myFunction: 10
Zurück aus myFunction!
x von main: 5
y von main: 7
Dieses einfache Programm verdeutlicht einige wesentliche und vielleicht verwirrende
Eigenheiten von lokalen und globalen Variablen. Zeile 4 deklariert zwei globale Variablen,
x und y. Die globale Variable x wird mit dem Wert 5 und die globale Variable y
mit dem Wert 7 initialisiert.
Zeile 8 und 9 geben in der Funktion main() diese Werte auf dem Bildschirm aus.
Wichtig ist, daß die Funktion main() keine der beiden Variablen definiert, da sie global
und somit bereits für main() verfügbar sind.
Mit dem Aufruf von myFunction() in Zeile 10 springt die Programmausführung in Zeile
18, wo im folgenden eine lokale Variable y definiert und mit dem Wert 10 initialisiert
wird. In Zeile 21 gibt die Funktion myFunction() den Wert der Variablen x aus,
das heißt, den Wert der globalen Variablen x, die auch in main() gültig war. Zeile 22
hingegen verwendet den Variablennamen y, der sich auf die lokale Variable y bezieht.
Dabei bleibt die gleichlautende globale Variable verborgen.
Der Funktionsaufruf ist beendet und die Programmkontrolle kehrt wieder zu main()
zurück. Die main()-Funktion gibt erneut die Werte der globalen Variablen aus. Ich
möchte Sie darauf hinweisen, daß die globale Variable y von dem Wert, der der lokalen
y-Variablen von myFunction() zugewiesen wurde, vollkommen unberührt geblieben
ist.
In C++ sind globale Variablen zwar zulässig, werden jedoch äußerst selten verwendet. C++ basiert auf C, und in C sind globale Variablen ein gefährliches, jedoch notwendiges Übel. Notwendig sind sie insofern, als es immer mal wieder vorkommt, daß ein Programmierer Daten vielen Funktionen verfügbar machen muß und er diese Daten nicht als Parameter von Funktion zu Funktion weitergeben möchte.
Gefährlich sind globale Variablen deshalb, weil es sich bei ihnen um allgemein zugängliche Daten handelt und weil globale Variablen durch eine Funktion geändert werden können, ohne daß die anderen Funktion dies kontrollieren können. Dies kann zu Fehlern führen, die nur sehr schwer aufzuspüren sind.
Am Tag 14 »Spezielle Themen zu Klassen und Funktionen« werde ich Ihnen eine mächtige Alternative zu globalen Variablen vorstellen, die nur in C++, jedoch nicht in C zur Verfügung steht.
Variablen, die innerhalb einer Funktion deklariert werden, haben einen lokalen Gültigkeitsbereich. Das bedeutet, wie bereits oben angesprochen, daß lokale Variablen nur innerhalb der Funktion, in der sie definiert wurden, sichtbar sind und verwendet werden können. In C++ können Sie Variablen praktisch überall in der Funktion, nicht nur am Anfang, definieren. Der Gültigkeitsbereich der Variablen ist der Block, in dem sie definiert ist. Wenn Sie also eine Variable innerhalb geschweifter Klammern in dieser Funktion definieren, ist diese Variable auch nur innerhalb dieses Blocks gültig. In Listing 5.4 sehen Sie, was ich meine.
Listing 5.4: Variablen innerhalb eines Blocks
1: // Listing 5.4 - Variablen, die in
2: // einem Block gültig sind
3:
4: #include <iostream.h>
5:
6: void myFunc();
7:
8: int main()
9: {
10: int x = 5;
11: cout << "\nIn main ist die Variable x: " << x;
12:
13: myFunc();
14:
15: cout << "\nZurück in main, ist die Variable x: " << x;
16: return 0;
17: }
18:
19: void myFunc()
20: {
21:
22: int x = 8;
23: cout << "\nIn myFunc ist die lokale Variable x: " << x << endl;
24:
25: {
26: cout << "\nIm Block in myFunc ist die lokale Variable x: " << x;
27:
28: int x = 9;
29:
30: cout << "\nNur blockbezogen ist die lokale Variable x: " << x;
31: }
32:
33: cout << "\nAußerhalb des Blocks in myFunc ist x: " << x << endl;
34: }
In main ist die Variable x: 5
In myFunc ist die lokale Variable x: 8
Im Block in myFunc ist die lokale Variable x: 8
Nur blockbezogen ist die lokale Variable x: 9
Außerhalb des Blocks in myFunc ist x: 8
Zurück in main, ist die Variable x: 5
Dieses Programm beginnt mit der Initialisierung einer lokalen Variablen x in main() in
Zeile 10. Zeile 11 gibt x aus und beweist, daß die Variable mit dem Wert 5 initialisiert
wurde.
Die Funktion myFunc() wird aufgerufen und in Zeile 22 wird eine lokale Variable mit
gleichem Namen x mit dem Wert 8 initialisiert. Zeile 23 gibt diesen Wert aus.
In Zeile 25 beginnt ein Block, in dem die Variable x der Funktion erneut ausgegeben
wird (Zeile 26). Weiter unten in Zeile 28 wird eine neue lokale Variable, wiederum mit
dem Namen x, deklariert, deren Gültigkeitsbereich der Block ist. Die Variable wird mit
dem Wert 9 initialisiert.
Der Wert der neuen Variable x wird in Zeile 30 ausgegeben. Der lokale Block endet in
Zeile 31, und die Variable, die in Zeile 28 erzeugt wurde, verliert ihren Gültigkeitsbereich
und ist nicht länger sichtbar.
Das x, das in Zeile 33 ausgegeben wird, wurde in Zeile 22 deklariert. Es ist von dem x
aus Zeile 28 nicht betroffen; sein Wert ist immer noch 8.
In Zeile 34 endet der Gültigkeitsbereich der Funktion myFunc()und ihre lokalen Variablen
x stehen nicht mehr zur Verfügung. Die Programmausführung springt in Zeile
15, und der Wert der lokalen Variablen x, die in Zeile 10 erzeugt wurde, wird ausgegeben.
Diese Variable bleibt unberührt von den beiden Variablen, die in myFunc() definiert
wurden.
Es erübrigt sich wohl der Hinweis, daß dieses Programm wesentlich übersichtlicher wäre, wenn man den drei Variablen eindeutige Namen gegeben hätte.
Es gibt praktisch keine Grenze für die Anzahl oder die Art von Anweisungen, die man
in einem Funktionsrumpf unterbringen kann. Sie können zwar innerhalb einer Funktion
keine andere Funktion definieren, aber Sie können andere Funktionen aufrufen.
Das ist genau das, was main() in fast jedem C++-Programm macht. Funktionen können
sich sogar selbst aufrufen. Doch darauf wollen wir erst im Abschnitt zu den Rekursionen
eingehen.
Ihnen ist zwar bezüglich der Größe einer Funktion keine Grenze gesetzt, doch gut konzipierte Funktionen sind in der Regel eher klein. Viele Programmierer raten Ihnen, Ihre Funktionen so kurz wie die Bildschirmfläche zu halten, so daß Sie die ganze Funktion auf einmal im Blick halten können. Das soll hier jedoch nur als Faustregel gelten, die auch von guten Programmierern oft gebrochen wird. Kleinere Funktionen sind jedoch unbestreitbar leichter zu verstehen und zu warten.
Jede Funktion sollte einer bestimmten, leicht verständlichen Aufgabe gewidmet sein. Wird Ihre Funktion zu groß, überlegen Sie sich, wie Sie sie in kleinere Unteraufgaben zerlegen können.
Die Argumente einer Funktion müssen nicht alle vom selben Typ sein. Es ist durchaus
sinnvoll, eine Funktion zu schreiben, die einen int-Wert, zwei Zahlen vom Typ long
und ein Zeichen als Argumente übernimmt.
Als Funktionsausdruck ist jeder gültige C++-Ausdruck zulässig. Dazu gehören Konstanten, mathematische und logische Ausdrücke und andere Funktionen, die einen Wert zurückgeben.
Obwohl es zulässig ist, daß eine Funktion als Parameter eine zweite Funktion übernimmt, die einen Wert zurückgibt, kann man einen derartigen Code schwer lesen und kaum auf Fehler untersuchen.
Nehmen wir zum Beispiel die Funktionen double(), triple(), square() und cube(),
die alle einen Wert zurückgeben. Man kann schreiben
Ergebnis = (double(triple(square(cube(meinWert)))));
Diese Anweisung übergibt die Variable meinWert als Argument an die Funktion cube()
, deren Rückgabewert als Argument an die Funktion square() dient. Die Funktion
square() wiederum liefert ihren Rückgabewert an triple(), und diesen Rückgabewert
übernimmt die Funktion double(). Der Rückgabewert dieser verdoppelten, verdreifachten,
quadrierten und zur dritten Potenz erhobenen Zahl wird jetzt an Ergebnis zugewiesen.
Man kann nur schwer erkennen, was dieser Code bewirkt. (Findet das Verdreifachen vor oder nach dem Quadrieren statt?) Falls diese Anweisung ein falsches Ergebnis liefert, läßt sich kaum die schuldige Funktion ermitteln.
Als Alternative kann man das Ergebnis jedes einzelnen Schrittes einer Variablen zur Zwischenspeicherung zuweisen:
unsigned long meinWert = 2;
unsigned long drittePotenz = cube(meinWert); // zur dritten Potenz = 8
unsigned long quadriert = square(drittePotenz); // quadriert = 64
unsigned long verdreifacht = triple(quadriert); // verdreifacht = 196
unsigned long Ergebnis = double(verdreifacht); // Ergebnis = 392
Jedes Zwischenergebnis kann man nun untersuchen, und die Reihenfolge der Ausführung ist klar erkennbar.
Die an eine Funktion übergebenen Argumente sind zur Funktion lokal. An den Argumenten vorgenommene Änderungen beeinflussen nicht die Werte in der aufrufenden Funktion. Man spricht daher von einer Übergabe als Wert. Das bedeutet, daß die Funktion von jedem Argument eine lokale Kopie anlegt. Die lokalen Kopien lassen sich wie andere lokale Variablen behandeln. Listing 5.5 verdeutlicht dieses Konzept.
Listing 5.5: Übergabe als Wert
1: // Listing 5.5 - Zeigt die Übergabe als Wert
2:
3: #include <iostream.h>
4:
5: void swap(int x, int y);
6:
7: int main()
8: {
9: int x = 5, y = 10;
10:
11: cout << "Main. Vor Vertauschung, x: " << x << " y: " << y << "\n";
12: swap(x,y);
13: cout << "Main. Nach Vertauschung, x: " << x << " y: " << y << "\n";
14: return 0;
15: }
16:
17: void swap (int x, int y)
18: {
19: int temp;
20:
21: cout << "Swap. Vor Vertauschung, x: " << x << " y: " << y << "\n";
22:
23: temp = x;
24: x = y;
25: y = temp;
26:
27: cout << "Swap. Nach Vertauschung, x: " << x << " y: " << y << "\n";
28:
29: }
Main. Vor Vertauschung, x: 5 y: 10
Swap. Vor Vertauschung, x: 5 y: 10
Swap. Nach Vertauschung, x: 10 y: 5
Main. Nach Vertauschung, x: 5 y: 10
Dieses Programm initialisiert zwei Variablen in main() und übergibt sie dann der Funktion
swap(), die scheinbar eine Vertauschung vornimmt. Wenn man die Werte allerdings
erneut in main() untersucht, ist keine Veränderung festzustellen!
Zeile 9 initialisiert die Variablen, Zeile 11 zeigt die Werte an. In Zeile 12 steht der Aufruf
der Funktion swap() mit der Übergabe der Variablen.
Die Ausführung des Programms verzweigt in die Funktion swap(), die in Zeile 21 die
Werte erneut ausgibt. Wie erwartet, befinden sie sich in derselben Reihenfolge wie in
main(). In den Zeilen 23 bis 25 findet die Vertauschung statt. Die Ausgabe in der Zeile
27 bestätigt diese Aktion. Solange wir uns in der Funktion swap() befinden, sind die
Werte tatsächlich vertauscht.
Die Programmausführung kehrt zu Zeile 13 (in der Funktion main()) zurück, wo die
Werte nicht mehr vertauscht sind.
Wie Sie bemerkt haben, findet die Übergabe an die Funktion swap() als Wert statt.
Folglich legt die Funktion swap() lokale Kopien der Werte an. Die Vertauschung in
den Zeilen 23 bis 25 betrifft nur die lokalen Kopien und hat keinen Einfluß auf die Variablen
in der Funktion main().
Im Kapitel 8 und 10 lernen Sie Alternativen zur Übergabe als Wert kennen. Damit lassen
sich dann auch die Werte in main() ändern.
Funktionen geben entweder einen Wert oder void zurück. void ist ein Signal an den
Compiler, daß kein Wert zurückgegeben wird.
Die Syntax für die Rückgabe eines Wertes aus einer Funktion besteht aus dem Schlüsselwort
return, gefolgt vom zurückzugebenden Wert. Der Wert selbst kann ein Ausdruck
sein, der einen Wert liefert. Einige Beispiele:
return 5;
return (x > 5);
return (MeineFunktion());
Unter der Voraussetzung, daß die Funktion MeineFunktion() selbst einen Rückgabewert
liefert, handelt es sich bei den folgenden Beispielen um zulässige return-Anweisungen.
Der Wert in der zweiten Anweisung return (x > 5) ist false, wenn x nicht
größer als 5 ist. Andernfalls lautet der Rückgabewert true. Es wird hier der Wert des
Ausdrucks - false oder true - zurückgegeben und nicht der Wert von x.
Gelangt die Programmausführung zum Schlüsselwort return, wird der auf return folgende
Ausdruck als Wert der Funktion zurückgegeben. Die Programmausführung
kehrt dann sofort zur aufrufenden Funktion zurück, und alle auf return folgenden Anweisungen
gelangen nicht mehr zur Ausführung.
In ein und derselben Funktion dürfen mehrere return-Anweisungen vorkommen. Listing
5.6 zeigt dazu ein Beispiel.
Listing 5.6: Eine Funktion mit mehreren return-Anweisungen
1: // Listing 5.6 - Verwendung mehrerer
2: // return-Anweisungen
3:
4: #include <iostream.h>
5:
6: int Doubler(int AmountToDouble);
7:
8: int main()
9: {
10:
11: int result = 0;
12: int input;
13:
14: cout << "Zu verdoppelnde Zahl zwischen 0 und 10000 eingeben: ";
15: cin >> input;
16:
17: cout << "\nVor Aufruf von Doubler... ";
18: cout <<"\nEingabe: " << input <<" Verdoppelt: "<< result <<"\n";
19:
20: result = Doubler(input);
21:
22: cout << "\nZurueck aus Doubler...\n";
23: cout <<"\nEingabe: " << input <<" Verdoppelt: "<< result <<"\n";
24:
25:
26: return 0;
27: }
28:
29: int Doubler(int original)
30: {
31: if (original <= 10000)
32: return original * 2;
33: else
34: return -1;
35: cout << "Diese Stelle wird nie erreicht!\n";
36: }
Zu verdoppelnde Zahl zwischen 0 und 10000 eingeben: 9000
Vor Aufruf von Doubler...
Eingabe: 9000 Verdoppelt: 0
Zurueck aus Doubler...
Eingabe: 9000 Verdoppelt: 18000
Zu verdoppelnde Zahl zwischen 0 und 10000 eingeben: 11000
Vor Aufruf von Doubler...
Eingabe: 11000 Verdoppelt: 0
Zurueck aus Doubler...
Eingabe: 11000 Verdoppelt: -1
In den Zeilen 14 und 15 wird eine Zahl angefordert und in Zeile 18 zusammen mit dem
Ergebnis der lokalen Variablen ausgegeben. Bei Aufruf der Funktion Doubler() in Zeile
20 erfolgt die Übergabe des eingegebenen Wertes als Parameter. Die zu main() lokale
Variable result erhält das Ergebnis dieses Aufrufs, das die Zeile 23 erneut anzeigt.
In Zeile 31 - in der Funktion Doubler() - wird überprüft, ob der Parameter größer als
10.000 ist. Sollte das nicht der Fall sein, gibt die Funktion das Doppelte des Originalwertes
zurück. Bei einem Wert größer als 10.000 liefert die Funktion -1 als Fehlerwert.
Das Programm erreicht niemals Zeile 35, da die Funktion entweder in Zeile 32 oder in Zeile 34 - je nach übergebenem Wert - zurückkehrt. Ein guter Compiler erzeugt hier eine Warnung, daß diese Anweisung nicht ausgeführt werden kann, und ein guter Programmierer nimmt eine derartige Anweisung gar nicht erst auf!
Was ist der Unterschied zwischen
int main()undvoid main()und welche Deklaration sollte ich verwenden? Ich habe beide ausprobiert und beide funktionierten wie gewünscht. Warum sollte ich alsoint main() { return 0}; verwenden?Antwort: Beide Varianten lassen sich auf den meisten Compilern verwenden, aber nur
int main()stimmt mit den ANSI-Richtlinien überein. Deshalb wird auch nurint main()weiterhin garantiert anwendbar sein.Der Unterschied zwischen beiden Varianten ist, daß
int main()einen Wert an das Betriebssystem zurückliefert. Wenn Ihr Programm abgearbeitet ist, kann dieser Wert zum Beispiel von Batch-Programmen abgefangen werden.Wir werden hier den Rückgabewert nicht weiter berücksichtigen (er wird nur selten benötigt), aber der ANSI-Standard erfordert ihn.
Für jeden Parameter, den man im Prototyp und der Definition einer Funktion deklariert, muß die aufrufende Funktion einen Wert übergeben, der vom deklarierten Typ sein muß. Wenn man daher eine Funktion als
long meineFunktion(int);
deklariert hat, muß die Funktion tatsächlich eine Integer-Variable übernehmen. Wenn die Definition der Funktion abweicht oder man keinen Integer-Wert übergibt, erhält man einen Compiler-Fehler.
Die einzige Ausnahme von dieser Regel: Der Prototyp der Funktion deklariert für den Parameter einen Standardwert, den die Funktion verwendet, wenn man keinen anderen Wert bereitstellt. Die obige Deklaration könnte dazu wie folgt umgeschrieben werden:
long meineFunktion (int x = 50);
Dieser Prototyp sagt aus: »meineFunktion() gibt einen Wert vom Typ long zurück und
übernimmt einen int-Parameter. Wenn kein Argument übergeben wird, verwende
den Standardwert 50.« Da in Funktionsprototypen keine Parameternamen erforderlich
sind, könnte man diese Deklaration auch als
long meineFunktion (int = 50);
schreiben. Durch die Deklaration eines Standardparameters ändert sich die Funktionsdefinition nicht. Der Kopf der Funktionsdefinition für diese Funktion lautet:
long meineFunktion (int x).
Wenn die aufrufende Funktion keinen Parameter einbindet, füllt der Compiler den Parameter
x mit dem Standardwert 50. Der Name des Standardparameters im Prototyp
muß nicht mit dem Namen im Funktionskopf übereinstimmen. Die Zuweisung des
Standardwerts erfolgt nach Position und nicht nach dem Namen.
Man kann allen Parametern einer Funktion oder nur einem Teil davon Standardwerte zuweisen. Die einzige Einschränkung: Wenn für einen der Parameter kein Standardwert angegeben ist, kann kein vorheriger Parameter dieser Parameterliste einen Standardwert haben.
Sieht der Prototyp einer Funktion zum Beispiel wie folgt aus
long meineFunktion (int Param1, int Param2, int Param3);
kann man Param2 nur dann einen Standardwert zuweisen, wenn man für Param3 einen
Standardwert festgelegt hat. An Param1 läßt sich nur dann ein Standardwert zuweisen,
wenn sowohl für Param2 als auch Param3 Standardwerte festgelegt wurden. Listing 5.5
demonstriert die Verwendung von Standardwerten.
Listing 5.7: Standardwerte für Parameter
1: // Listing 5.7 - Demonstriert die Verwendung
2: // von Standardwerten für Parameter
3:
4: #include <iostream.h>
5:
6: int VolumeCube(int length, int width = 25, int height = 1);
7:
8: int main()
9: {
10: int length = 100;
11: int width = 50;
12: int height = 2;
13: int volume;
14:
15: volume = VolumeCube(length, width, height);
16: cout << "Erstes Volumen gleich: " << volume << "\n";
17:
18: volume = VolumeCube(length, width);
19: cout << "Zweites Volumen gleich: " << volume << "\n";
20:
21: volume = VolumeCube(length);
22: cout << "Drittes Volumen gleich: " << volume << "\n";
23: return 0;
24: }
25:
26: VolumeCube(int length, int width, int height)
27: {
28:
29: return (length * width * height);
30: }
Erstes Volumen gleich: 10000
Zweites Volumen gleich: 5000
Drittes Volumen gleich: 2500
In Zeile 6 spezifiziert der Prototyp von VolumeCube(), daß die Funktion VolumeCube()
drei int-Parameter übernimmt. Die letzten beiden weisen Standardwerte auf.
Die Funktion berechnet das Volumen des Quaders für die übergebenen Abmessungen.
Fehlt die Angabe der Breite (width), nimmt die Funktion eine Breite von 25 und
eine Höhe (height) von 1 an. Übergibt man die Breite, aber nicht die Höhe, verwendet
die Funktion eine Höhe von 1. Ohne die Übergabe der Breite kann man keine
Höhe übergeben.
Länge (length), Höhe (height) und Breite (width) werden in den Zeilen 10 bis 12 initialisiert
und in Zeile 15 an die Funktion VolumeCube() übergeben. Nach der Berechnung
der Werte gibt Zeile 16 das Ergebnis aus.
Die Programmausführung setzt mit Zeile 18 fort, wo ein weiterer Aufruf von VolumeCube()
steht, diesmal aber ohne Wert für height. Damit läuft die Berechnung mit dem
Standardwert ab. Zeile 20 gibt das Ergebnis aus.
Nach Abarbeitung dieses Funktionsaufrufs gelangt das Programm zur Zeile 21. Im
dritten Aufruf von VolumeCube() werden weder Breite noch Höhe übergeben. Die Ausführung
verzweigt nun zum dritten Mal zu Zeile 26. Die Berechnung erfolgt jetzt mit
beiden Standardwerten. Das Ergebnis zeigt Zeile 22 an.
In C++ lassen sich mehrere Funktionen mit demselben Namen erzeugen. Man bezeichnet das als Überladen von Funktionen. Die Funktionen müssen sich in ihrer Parameterliste unterscheiden, wobei andere Parametertypen, eine abweichende Anzahl von Parametern oder beides möglich sind. Dazu ein Beispiel:
int meineFunktion (int, int);
int meineFunktion (long, long);
int meineFunktion (long);
Die Funktion meineFunktion() wird mit drei unterschiedlichen Parameterlisten überladen.
Die erste Version unterscheidet sich von der zweiten durch die Parametertypen,
während die dritte Version eine abweichende Anzahl von Parametern aufweist.
Die Rückgabetypen der überladenen Funktionen können gleich oder verschieden sein. Bedenken Sie jedoch, daß zwei Funktionen mit gleichem Namen und gleicher Parameterliste, aber unterschiedlichen Rückgabetypen, einen Compiler-Fehler erzeugen.
Das Überladen von Funktionen bezeichnet man auch als Funktionspolymorphie. Das aus dem Griechischen stammende Wort polymorph bedeutet vielgestaltig - eine polymorphe Funktion weist viele Formen auf.
Funktionspolymorphie bezieht sich auf die Fähigkeit, eine Funktion mit mehreren Bedeutungen
zu »überladen«. Indem man die Anzahl oder den Typ der Parameter ändert,
kann man zwei oder mehreren Funktionen denselben Funktionsnamen geben. Anhand
der Parameterliste wird dann die richtige Funktion aufgerufen. Damit kann man
eine Funktion erzeugen, die den Mittelwert von ganzen und reellen Zahlen sowie anderen
Werten bilden kann, ohne daß man für jede Funktion einen separaten Namen
wie MittelwertInts(), MittlewertDoubles() usw. angeben muß.
Nehmen wir eine Funktion an, die den übergebenen Wert verdoppelt. Man möchte
dabei Zahlen vom Typ int, long, float oder double übergeben können. Ohne das
Überladen von Funktionen müßte man vier Funktionsnamen erzeugen:
int DoubleInt(int);
long DoubleLong(long);
float DoubleFloat(float);
double DoubleDouble(double);
Durch Überladung der Funktionen lassen sich folgende Deklarationen formulieren:
int Double(int);
long Double(long);
float Double(float);
double Double(double);
Das ist leichter zu lesen und einfacher zu warten. Man braucht sich nicht darum zu kümmern, welche Funktion aufzurufen ist. Man übergibt einfach eine Variable, und die richtige Funktion wird automatisch aufgerufen. Listing 5.8 verdeutlicht das Konzept des Überladens von Funktionen.
Listing 5.8: Ein Beispiel für Funktionspolymorphie
1: // Listing 5.8 - zeigt
2: // Funktionspolymorphie
3:
4: #include <iostream.h>
5:
6: int Double(int);
7: long Double(long);
8: float Double(float);
9: double Double(double);
10:
11: int main()
12: {
13: int myInt = 6500;
14: long myLong = 65000;
15: float myFloat = 6.5F;
16: double myDouble = 6.5e20;
17:
18: int doubledInt;
19: long doubledLong;
20: float doubledFloat;
21: double doubledDouble;
22:
23: cout << "myInt: " << myInt << "\n";
24: cout << "myLong: " << myLong << "\n";
25: cout << "myFloat: " << myFloat << "\n";
26: cout << "myDouble: " << myDouble << "\n";
27:
28: doubledInt = Double(myInt);
29: doubledLong = Double(myLong);
30: doubledFloat = Double(myFloat);
31: doubledDouble = Double(myDouble);
32:
33: cout << "doubledInt: " << doubledInt << "\n";
34: cout << "doubledLong: " << doubledLong << "\n";
35: cout << "doubledFloat: " << doubledFloat << "\n";
36: cout << "doubledDouble: " << doubledDouble << "\n";
37:
38: return 0;
39: }
40:
41: int Double(int original)
42: {
43: cout << "In Double(int)\n";
44: return 2 * original;
45: }
46:
47: long Double(long original)
48: {
49: cout << "In Double(long)\n";
50: return 2 * original;
51: }
52:
53: float Double(float original)
54: {
55: cout << "In Double(float)\n";
56: return 2 * original;
57: }
58:
59: double Double(double original)
60: {
61: cout << "In Double(double)\n";
62: return 2 * original;
63: }
myInt: 6500
myLong: 65000
myFloat: 6.5
myDouble: 6.5e+20
In Double(int)
In Double(long)
In Double(float)
In Double(double)
DoubledInt: 13000
DoubledLong: 130000
DoubledFloat: 13
DoubledDouble: 1.3e+21
Die Funktion Double() wird mit int, long, float und double überladen. Die Prototypen
dazu finden Sie in den Zeilen 6 bis 9 und die Definitionen in den Zeilen 41 bis 63.
Im Rumpf des Hauptprogramms werden acht lokale Variablen deklariert. Die Zeilen
13 bis 16 initialisieren vier der Werte, und die Zeilen 28 bis 31 weisen den anderen
vier die Ergebnisse der Übergabe der ersten vier an die Funktion Double() zu. Beachten
Sie, daß beim Aufruf von Double() die aufrufende Funktion nicht weiß, welche
Funktion aufgerufen wird. Sie übergibt lediglich ein Argument, und die korrekte Funktion
wird zum Aufruf ausgewählt.
Der Compiler untersucht die Argumente und entscheidet dann, welche der vier Double()
-Funktionen aufgerufen werden muß. Die Ausgabe macht deutlich, daß alle vier
Funktionen nacheinander wie erwartet aufgerufen wurden.
Da Funktionen für die Programmierung so gut wie unerläßlich sind, möchte ich auf einige spezielle Themen eingehen, die in Hinblick auf seltene Probleme von Interesse sein dürften. So können Inline-Funktionen, mit Bedacht eingesetzt, die Programmerstellung beachtlich optimieren. Und auch rekursive Funktionen sind ein wunderbares Hilfsmittel, mit dem sich auch schier aussichtslose Probleme lösen lassen, die sonst viel Mühe verursachen.
Wenn Sie eine Funktion definieren, erzeugt der Compiler in der Regel nur einen Satz Anweisungen im Speicher. Rufen Sie die Funktion auf, springt die Programmausführung zu diesen Anweisungen, kehrt die Funktion zurück, springt die Programmausführung zurück zur nächsten Zeile in der aufrufenden Funktion. Bei zehn Funktionsaufrufen springt Ihr Programm jedesmal zu dem gleichen Satz Anweisungen. Das bedeutet, daß nur eine Kopie der Funktion und nicht zehn davon existieren.
Das Einspringen in Funktionen und das Zurückkehren kostet jedoch einiges an Leistung. Manchmal kommt es vor, daß Funktionen sehr klein sind, das heißt, nur eine oder zwei Codezeilen groß. In einem solchen Falle ist das Programm effizienter, wenn die Sprünge vermieden werden. Und wenn ein Programmierer von Effizienz spricht, meint er in der Regel Geschwindigkeit. Das Programm läßt sich ohne den Funktionsaufruf schneller ausführen.
Wird eine Funktion mit dem Schlüsselwort inline deklariert, erzeugt der Compiler
keine echte Funktion. Er kopiert den Code von der Inline-Funktion direkt in die aufrufende
Funktion und umgeht so den Sprung. Das Programm benimmt sich, als ob die
Funktionsanweisungen direkt in die aufrufende Funktion geschrieben worden wären.
Dabei gilt es jedoch zu beachten, daß Inline-Funktionen auch erheblichen Ballast bedeuten können. Wird die Funktion nämlich zehnmal aufgerufen, wird der Inline-Code auch zehnmal in aufrufende Funktionen kopiert. Die eher bescheidene Verbesserung der Geschwindigkeit wird durch die stark aufgeblasene Größe des ausführbaren Programms so gut wie zunichte gemacht. Unter Umständen ist der Zeitgewinn auch gar keiner. Zum einen arbeiten die heutigen optimierenden Compiler bereits phantastisch, zum anderen ist der Laufzeitgewinn durch die Inline-Deklaration selten dramatisch. Vielmehr gilt es zu bedenken, daß auch ein größeres Programm zu Lasten der Leistung geht.
Wie also lautet die Faustregel? Haben Sie eine kleine Funktion von einer oder zwei Anweisungen, könnte diese ein Kandidat für eine Inline-Funktion sein. Wenn Sie jedoch Zweifel haben, lassen Sie die Finger davon. Listing 5.9 veranschaulicht den Einsatz der Inline-Funktion.
Listing 5.9: Ein Beispiel für den Einsatz einer Inline-Funktion
1: // Listing 5.9 - zeigt den Einsatz von Inline-Funktionen
2:
3: #include <iostream.h>
4:
5: inline int Double(int);
6:
7: int main()
8: {
9: int target;
10:
11: cout << "Geben Sie eine Zahl ein: ";
12: cin >> target;
13: cout << "\n";
14:
15: target = Double(target);
16: cout << "Ergebnis: " << target << endl;
17:
18: target = Double(target);
19: cout << "Ergebnis: " << target << endl;
20:
21:
22: target = Double(target);
23: cout << "Ergebnis: " << target << endl;
24: return 0;
25: }
26:
27: int Double(int target)
28: {
29: return 2*target;
30: }
Geben Sie eine Zahl ein: 20
Ergebnis: 40
Ergebnis: 80
Ergebnis: 160
Zeile 5 deklariert Double() als Inline-Funktion, die einen Integer-Parameter übernimmt
und einen Integer zurückgibt. Die Deklaration erfolgt wie bei allen anderen Prototypen,
mit der Ausnahme, daß das Schlüsselwort inline dem Rückgabewert vorangestellt
wird.
Der kompilierte Code ist der gleiche, wie wenn Sie für jede Codezeile
target = 2 * target;
target = Double(target);
Sobald Ihr Programm ausgeführt wird, befinden sich die Anweisungen schon an den gewünschten Stellen, kompiliert in die obj-Datei. Damit sparen Sie bei der Programmausführung die Funktionssprünge - zu Lasten eines größeren Programms.
inlineist ein Hinweis an den Compiler, daß Sie diese Funktion als eingefügten Code kompiliert wünschen. Es steht dem Compiler frei, diesen Hinweis zu ignorieren und einen echten Funktionsaufruf vorzunehmen.
Eine Funktion kann sich auch selbst aufrufen. Dies wird als Rekursion bezeichnet, die sowohl direkt als auch indirekt erfolgen kann. Eine direkte Rekursion liegt vor, wenn eine Funktion sich selbst aufruft. Eine indirekte Rekursion liegt vor, wenn eine Funktion eine andere Funktion aufruft, die dann wieder die erste Funktion aufruft.
Einige Probleme lassen sich am besten mit rekursiven Funktionen lösen. Üblicherweise sind dies Probleme, in denen Sie zuerst Daten und dann in gleicher Weise das Ergebnis bearbeiten wollen. Direkte als auch indirekte Rekursionen gibt es jeweils in zwei Formen: jene, die irgendwann beendet werden und ein Ergebnis liefern, und jene, die einen Laufzeitfehler produzieren. Programmierer halten letzteres für ziemlich lustig (solange es anderen passiert).
Eines sollten Sie sich dabei merken: Wenn eine Funktion sich selbst aufruft, wird eine
neue Kopie dieser Funktion ausgeführt. Die lokalen Variablen in der zweiten Version
sind unabhängig von den lokalen Variablen in der ersten Version; das heißt, sie haben
ebensowenig einen direkten Einfluß aufeinander, wie die lokalen Variablen in main()
auf die lokalen Variablen all jener Funktionen, die von main() aufgerufen werden.
Um zu zeigen, wie man ein Problem mit Hilfe von Rekursion löst, betrachten wir einmal die Fibonacci-Reihe:
Jede Zahl nach der zweiten ist die Summe der zwei Zahlen vor ihr. Ein Fibonacci- Problem könnte lauten: Wie heißt die 12te Zahl in der Reihe?
Eine Möglichkeit, dieses Problem zu lösen, besteht darin, die Reihe genau zu studieren. Die ersten beiden Zahlen lauten 1. Jede folgende Zahl ist die Summe der vorhergehenden zwei Zahlen. Demzufolge ist die siebte Zahl die Summe der sechsten und fünften Zahl. Allgemeiner ausgedrückt, ist die n-te Zahl die Summe von n-2 und n-1, wobei n > 2 sein muß.
Rekursive Funktionen benötigen eine Abbruchbedingung. Irgend etwas muß dafür sorgen, daß das Programm die Rekursion abbricht oder die Programmausführung geht endlos weiter. In der Fibonacci-Reihe lautet die Abbruchbedingung n<3.
Der Algorithmus für die Funktion lautet wie folgt:
Fragen Sie den Benutzer nach einer Position in der Reihe.
Rufen Sie die Funktion fib() mit dieser Position als Argument auf.
Die fib()-Funktion untersucht das Argument (n). Bei n < 3 liefert sie 1 zurück; andernfalls
ruft sich fib() selbst auf und übergibt n-2, ruft sich erneut selbst auf und
übergibt n-1 und liefert dann die Summe zurück.
Rufen Sie fib(1) auf, lautet der Rückgabewert 1. Rufen Sie fib(2) auf, lautet der
Rückgabewert 1. Rufen Sie fib(3) auf, erhalten Sie die Summe des Aufrufs von
fib(2) und fib(1). Da fib(2) 1 zurückliefert und fib(1) ebenfalls 1, lautet der Rückgabewert
von fib(3) 2.
Wenn Sie fib(4) aufrufen, liefert die Funktion die Summe von fib(3) und fib(2). Da
wir bereits eruiert haben, daß fib(3) 2 zurückliefert (durch Aufruf von fib(2) und
fib(1)) und der Rückgabewert von fib(2) 1 lautet, werden mit fib(4) diese beiden
Zahlen summiert und 3 zurückgeliefert. 3 lautet auch die vierte Zahl in der Reihe.
Gehen wir noch einen Schritt weiter: Mit dem Aufruf von fib(5) wird die Summe von
fib(4) und fib(3) zurückgegeben. Da fib(4) 3 und fib(3) 2 zurückliefert, lautet die
Summe 5.
Diese Methode ist zwar nicht der effizienteste Weg, um dies Problem zu lösen (für
fib(20) wird die fib-Funktion 13.528mal aufgerufen!), aber sie funktioniert. Seien
Sie jedoch vorsichtig. Wenn Sie eine zu große Zahl wählen, haben Sie ein Speicherproblem.
Jedesmal, wenn Sie fib() aufrufen, wird Speicherplatz reserviert. Kehrt die
Funktion zurück, wird der Speicherplatz wieder freigegeben. Bei der Rekursion wird
fortwährend Speicher reserviert, bevor Speicher freigegeben wird. Dieses System
kann sehr schnell Ihren Speicher aufbrauchen. In Listing 5.10 sehen Sie die fib()-
Funktion in der Anwendung.
Bei der Ausführung von 5.10 sollten Sie eine kleine Zahl (kleiner als 15) wählen. Da dies Beispiel mit Rekursion arbeitet, kann es Sie beträchtlich viel an Speicherplatz kosten.
Listing 5.10: Rekursion anhand der Fibonacci-Reihe
1: #include <iostream.h>
2:
3: int fib (int n);
4:
5: int main()
6: {
7:
8: int n, answer;
9: cout << "Zu findende Zahl eingeben: "; 10: cin >> n;
10:
11: cout << "\n\n";
12:
13: answer = fib(n);
14:
15: cout << "Die " << n << ". Fibonacci-Zahl" << " lautet " << answer;
16: cout << endl;
17: return 0;
18: }
19:
20: int fib (int n)
21: {
22: cout << "Verarbeitung von fib(" << n << ")... "; 23:
23: if (n < 3 )
24: {
25: cout << "Rückgabewert 1!\n";
26: return (1);
27: }
28: else
29: {
30: cout <<"Aufruf von fib(" << n-2 << ") und fib(" << n-1 << ").\n";
31: return( fib(n-2) + fib(n-1));
32: }
33: }
Zu findende Zahl eingeben: 6
Verarbeitung von fib(6)... Aufruf von fib(4) und fib(5).
Verarbeitung von fib(4)... Aufruf von fib(2) und fib(3).
Verarbeitung von fib(2)... Rückgabewert 1!
Verarbeitung von fib(3)... Aufruf von fib(1) und fib(2).
Verarbeitung von fib(1)... Rückgabewert 1!
Verarbeitung von fib(2)... Rückgabewert 1!
Verarbeitung von fib(5)... Aufruf von fib(3) und fib(4).
Verarbeitung von fib(3)... Aufruf von fib(1) und fib(2).
Verarbeitung von fib(1)... Rückgabewert 1!
Verarbeitung von fib(2)... Rückgabewert 1!
Verarbeitung von fib(4)... Aufruf von fib(2) und fib(3).
Verarbeitung von fib(2)... Rückgabewert 1!
Verarbeitung von fib(3)... Aufruf von fib(1) und fib(2).
Verarbeitung von fib(1)... Rückgabewert 1!
Verarbeitung von fib(2)... Rückgabewert 1!
Die 6. Fibonacci-Zahl lautet 8
Einige Compiler haben Schwierigkeiten mit der Verwendung von Operatoren in einer cout-Anweisung. Sollten Sie eine Warnung für Zeile 30 erhalten, setzen Sie die Subtraktion in Klammern, so daß Zeile 30 wie folgt aussieht:
30: cout <<"Aufruf von fib(" <<(n-2) <<") und fib(" <<(n-1) << ").\n";
Das Programm fragt nach einer Zahl (Zeile 9) und weist diese Zahl n zu. Danach ruft
es fib() mit n auf. Die Ausführung verzweigt in die fib()-Funktion, die in Zeile 22 ihr
Argument ausgibt.
Zeile 23 überprüft, ob das Argument n kleiner als 3 ist. Wenn ja, liefert fib() den
Wert 1 zurück. Andernfalls liefert es die Summe der Werte, die mit Aufruf von fib()
für n-2 und n-1 zurückgeliefert werden.
Das Programm kann diese Werte erst zurückliefern, wenn der Ausdruck mit dem zweimaligen
Aufruf von fib() ausgewertet ist. Sie können sich also vorstellen, daß dieses
Programm solange fib() wiederholt aufruft, bis es auf einen Aufruf von fib() trifft,
der einen Wert zurückliefert. Die einzigen Aufrufe, die sofort einen Wert zurückgeben,
sind die an fib(2) und fib(1). Diese Rückgabewerte werden dann an die wartenden
Aufrufer weitergegeben, die wiederum den Rückgabewert ihrem eigenen hinzufügen,
um dann einen neuen Wert zurückzugeben. Abbildung 5.4 und Abbildung 5.5 sollen
diese Rekursion von fib() verdeutlichen.
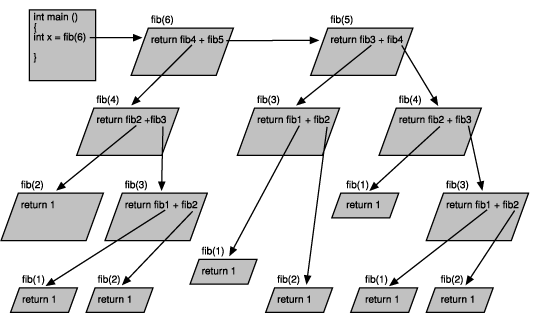
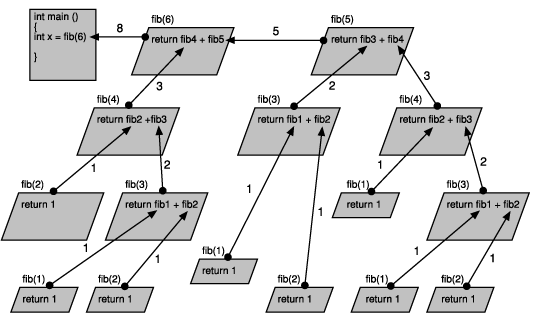
Abbildung 5.5: Rückkehr von der Rekursion
In unserem Beispiel ist n gleich 6, so daß in main() fib(6) aufgerufen wird. Die Ausführung
springt zu der fib()-Funktion, und in Zeile 23 wird geprüft, ob n kleiner als 3
ist. Da dem nicht so ist, liefert fib(6) die Summe der Werte von fib(4) und fib(5)
wie folgt zurück.
31: return( fib(n-2) + fib(n-1));
Das bedeutet, es erfolgt ein Aufruf von fib(4) [da n == 6, entspricht fib(n-2) dem
Aufruf fib(4) ] und ein weiterer Aufruf von fib(5) [fib(n-1)]. Währenddessen wartet
die Funktion, in der Sie sich befinden [fib(6)], bis diese Aufrufe einen Wert zurückliefern.
Wurde für die beiden Funktionsaufrufe ein Wert ermittelt, kann die Funktion die
Summe dieser beiden Werte zurückgeben.
Da fib(5) ein Argument übergibt, das nicht kleiner als 3 ist, wird erneut fib() aufgerufen,
diesmal mit den Werten 4 und 3. Die Funktion fib(4) ihrerseits ruft fib(3) und
fib(2) auf.
Die Ausgabe verfolgt diese Aufrufe und die zurückgegebenen Werte. Kompilieren, linken und starten Sie das Programm mit der Eingabe von 1, dann 2, dann 3 bis hin zu 6 und beobachten Sie die Ausgabe genau.
Hier bietet es sich förmlich an, einmal mit dem Debugger herumzuspielen. Setzen Sie
in Zeile 22 einen Haltepunkt und verzweigen Sie dann in die Aufrufe von fib(), wobei
Sie den Wert von n im Auge behalten.
Rekursion wird in der C++-Programmierung nicht oft eingesetzt. Für bestimmte Zwecke stellt es jedoch eine hilfreiche und elegante Lösung dar.
Rekursion gehört zum eher komplizierten Teil der fortgeschrittenen Programmierung. Ich habe Ihnen das Konzept vorgestellt, da es nützlich sein kann, die Grundlagen der Funktionsweise von rekursiven Funktionen zu verstehen. Machen Sie sich jedoch keine allzu großen Sorgen, wenn noch Fragen offen bleiben.
Beim Aufruf einer Funktion verzweigt der Code in die aufgerufene Funktion, die Parameter
werden übergeben, und der Rumpf der Funktion wird ausgeführt. Nach abgeschlossener
Abarbeitung gibt die Funktion einen Wert zurück (außer wenn die Funktion
als void deklariert ist), und die Steuerung geht an die aufrufende Funktion über.
Wie wird dies realisiert? Woher weiß der Code, wohin zu verzweigen ist? Wo werden die Variablen aufbewahrt, wenn die Übergabe erfolgt? Was geschieht mit den Variablen, die im Rumpf der Funktion deklariert sind? Wie wird der Rückgabewert der Funktion zurückgeliefert? Woher weiß der Code, wo das Programm fortzusetzen ist?
In den meisten Anfängerbüchern wird gar nicht erst versucht, diese Fragen zu beantworten. Ohne Kenntnis dieser Antworten wird die Programmierung Ihnen jedoch immer ein Buch mit sieben Siegeln bleiben. Zur Erläuterung möchte ich jetzt kurz abschweifen und das Thema Computerspeicher ansprechen.
Eine der größten Hürden für Programmierneulinge ist es, Verständnis für die vielen Abstraktionsebenen zu entwickeln. Computer sind selbstverständlich nur elektronische Maschinen. Sie wissen nicht, was Fenster und Menüs oder Programme und Anweisungen sind, ja sie wissen nicht einmal, wozu Nullen und Einsen gut sind. Dabei läßt sich das Ganze auf das Abgreifen und Messen von Strom an bestimmten Stellen auf der Leiterplatte reduzieren. Aber selbst das ist bereits abstrahiert: Elektrizität ist an sich lediglich ein intellektueller Begriff, der das Verhalten subatomarer Partikel beschreibt.
Nur wenige Programmierer setzen sich mit Detailwissen unterhalb der Ebene von RAM-Werten auseinander. Denn schließlich muß man ja nichts von Teilchenphysik verstehen, um ein Auto zu fahren, den Toaster anzuwerfen oder einen Baseball zu schlagen. Ebensowenig muß man Ahnung von Computern haben, um programmieren zu können.
Was Sie jedoch wissen müssen ist, wie der Speicher organisiert ist. Ohne eine ziemlich genaue Vorstellung, wo Ihre Variablen sich befinden, wenn sie erzeugt werden, und wie Werte zwischen Funktionen übergeben werden, wird Ihnen das Ganze ein einziges unlösbares Rätsel bleiben.
Wenn Sie Ihr Programm beginnen, richtet Ihr Betriebssystem (zum Beispiel DOS oder Microsoft Windows) je nach Anforderungen Ihres Compilers mehrere Speicherbereiche ein. Als C++-Programmierer werden Sie nicht umhin kommen, sich mit Begriffen wie globaler Namensbereich, Heap, Register, Codebereich und Stack auseinanderzusetzen.
Globale Variablen werden im globalen Namensbereich abgelegt. Doch zu dem globalen Namensbereich und dem Heap werden wir erst in einigen Tagen kommen. Im Moment möchte ich mich auf Register, Codebereich und Stack beschränken.
Register sind ein besonderer Speicherbereich, der sich direkt in der Central Processing Unit (auch CPU genannt) befindet. Sie sind für die interne Hausverwaltung, die eigentlich nicht Thema dieses Buches sein soll. Was wir aber kennen sollten, ist der Satz von Registern, der die Aufgabe hat, zu jedem beliebigen Zeitpunkt auf die nächste auszuführende Codezeile zu zeigen. Wir werden diese Register zusammengefaßt als Befehlszeiger bezeichnen. Dem Befehlszeiger obliegt es, die nächste auszuführende Codezeile im Auge zu behalten.
Der Code selbst befindet sich im Codebereich - ein Speicherbereich, der eingerichtet wurde, um die in binärer Form vorliegenden Anweisungen Ihres Programms aufzunehmen. Jede Quellcodezeile wird übersetzt in eine Reihe von Anweisungen und jede dieser Anweisungen befindet sich an einer bestimmten Adresse im Speicher. Der Befehlszeiger verfügt über die Adresse der nächsten auszuführenden Anweisung. Abbildung 5.6 veranschaulicht dieses Konzept.
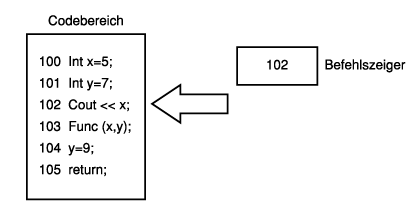
Abbildung 5.6: Der Befehlszeiger
Beim Start eines Programms legt der Compiler einen speziellen Speicherbereich für die Funktionsaufrufe an: den sogenannten Stack. Der Stack (Stapelspeicher) ist ein spezieller Bereich im Hauptspeicher, der die Daten aufnimmt, die für die einzelnen Funktionen im Programm gedacht sind. Die Bezeichnung Stapelspeicher läßt Ähnlichkeiten mit einem Geschirrstapel vermuten, wie ihn Abbildung 5.7 zeigt. Was man zuletzt auf den Stapel gelegt hat, entnimmt man auch wieder zuerst.
Der Stack wächst, wenn man Daten auf den Stack »legt«. Entnimmt man Daten vom Stack, schrumpft er. Einen Geschirrstapel kann man auch nicht wegräumen, ohne die zuletzt oben auf gelegten Teller als erste wieder wegzunehmen.
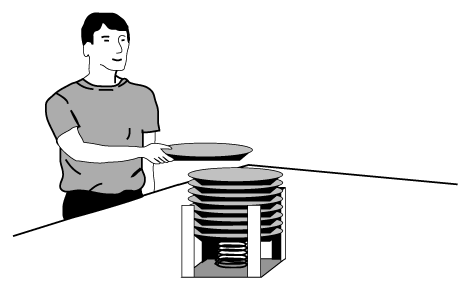
Abbildung 5.7: Ein Stack (Stapel)
Die Analogie zum Geschirrstapel eignet sich zwar zur anschaulichen Darstellung, versagt aber bei der grundlegenden Arbeitsweise des Stacks. Eine genauere Vorstellung liefert eine Folge von Fächern, die von oben nach unten angeordnet sind. Die Spitze des Stacks ist das Fach, auf das der Stack-Zeiger (ein weiteres Register) zeigt.
Alle Fächer haben eine fortlaufende Adresse, und eine dieser Adressen wird im Stack- Register abgelegt. Alles unterhalb dieser magischen Adresse, die man als Spitze des Stacks bezeichnet, wird als »auf dem Stack befindlich« betrachtet. Alles oberhalb des Stack-Zeigers liegt außerhalb des Stacks und ist ungültig. Abbildung 5.8 verdeutlicht dies.
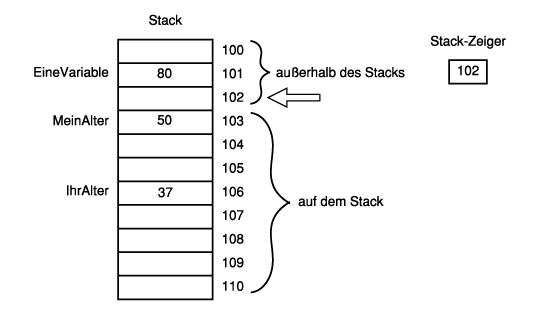
Abbildung 5.8: Der Stack-Zeiger
Wenn man neue Daten auf den Stack legt, kommen sie in ein Fach oberhalb des Stack-Zeigers. Anschließend wird der Stack-Zeiger zu den neuen Daten verschoben. Entnimmt man Daten aus dem Stack, passiert weiter nichts, als daß die Adresse des Stack-Zeigers auf dem Stack nach unten geschoben wird (siehe Abbildung 5.9).
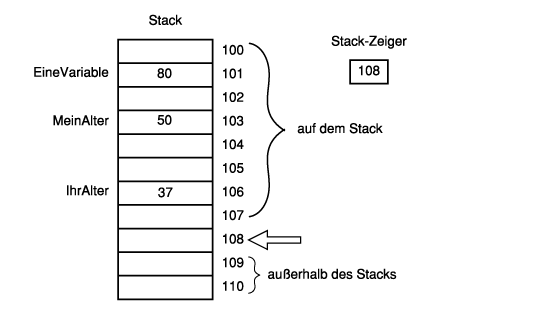
Abbildung 5.9: Verschieben des Stack-Zeigers
Wenn ein Programm, das auf einem PC unter DOS ausgeführt wird, in eine Funktion verzweigt, passiert folgendes:
Ist die Funktion soweit, zurückzukehren, wird der Rückgabewert in dem in Punkt 2 beschriebenen Stack-Bereich abgelegt. Der Stack wird jetzt bis zum Stack-Rahmen-Zeiger aufgelöst, so daß damit alle lokalen Variablen und die Argumente der Funktion entfernt werden.
Der Rückgabewert wird vom Stack geschmissen und als Wert des Funktionsaufrufs zugewiesen. Die in Punkt 1 gespeicherte Adresse wird ermittelt und im Befehlszeiger abgelegt. Das Programm fährt deshalb direkt nach dem Funktionsaufruf mit dem Rückgabewert der Funktion fort.
Einige Details dieser Vorgehensweise sind von Compiler zu Compiler oder unter Computern verschieden, aber die wesentlichen Konzepte sind umgebungsunabhängig. Allgemein gilt, daß Sie bei Aufruf einer Funktion die Rückgabeadresse und die Parameter auf dem Stack ablegen. Solange die Funktion »lebt«, werden die lokalen Variablen dem Stack hinzugefügt. Kehrt die Funktion zurück, werden sie entfernt, indem der Stackbereich der Funktion aufgelöst wird.
In den nächsten Tagen werden wir Speicherbereiche kennenlernen, in denen Daten abgelegt werden, die über die Geltungsdauer einer Funktion hinaus gehalten werden müssen.
Dieses Kapitel war eine Einführung in Funktionen. Praktisch handelt es sich bei einer
Funktion um ein Unterprogramm, an das man Parameter übergeben und von dem
man einen Rückgabewert erhalten kann. Jedes C++-Programm beginnt in der Funktion
main(), und main() kann ihrerseits andere Funktionen aufrufen.
Die Deklaration einer Funktion erfolgt durch einen Prototyp, der den Rückgabewert,
den Funktionsnamen und die Parametertypen beschreibt. Funktionen können optional
als inline deklariert werden. Funktionsprototypen können auch Standardvariablen
für einen oder mehrere Parameter festlegen.
Die Funktionsdefinition muß mit dem Funktionsprototyp hinsichtlich Rückgabetyp, Name und Parameterliste übereinstimmen. Funktionsnamen kann man überladen, indem man die Anzahl oder den Typ der Parameter ändert. Der Compiler ermittelt die richtige Funktion für einen Aufruf anhand der Argumentliste.
Lokale Variablen in Funktionen und die an die Funktion übergebenen Argumente sind lokal zu dem Block, in dem sie deklariert sind. Als Wert übergebene Parameter sind Kopien und können nicht auf den Wert der Variablen in der aufrufenden Funktion zurückwirken.
Frage:
Warum arbeitet man nicht generell mit globalen Variablen?
Antwort:
In den Anfangszeiten der Programmierung wurde genau das gemacht. Durch
die zunehmende Komplexität der Programme ließen sich Fehler allerdings immer
schwerer finden, da jede beliebige Funktion die Daten verändern konnte
- globale Daten lassen sich an beliebigen Stellen im Programm verändern. Im
Lauf der Jahre hat sich bei den Programmierern die Erkenntnis durchgesetzt,
daß Daten so lokal wie möglich zu halten sind und der Zugriff auf diese Daten
sehr eng abgesteckt sein sollte.
Frage:
Wann sollte das Schlüsselwort inline in einem Funktionsprototypen
verwendet werden?
Antwort:
Ist eine Funktion sehr klein, das heißt, nicht größer als ein bis zwei Zeilen,
und wird sie nur von einigen wenigen Stellen in Ihrem Programm aufgerufen,
ist sie ein potentieller Kandidat für die Verwendung des Schlüsselwortes inline
.
Frage:
Warum werden Änderungen am Wert von Funktionsargumenten nicht
in der aufrufenden Funktion widergespiegelt?
Antwort:
Die Übergabe der Argumente an eine Funktion erfolgt als Wert. Das bedeutet,
daß die Argumente innerhalb der Funktion tatsächlich als Kopien der Originalwerte
vorliegen. Das Konzept wird im Abschnitt »Arbeitsweise von Funktionen
- ein Blick hinter die Kulissen« in diesem Kapitel genau erklärt.
Frage:
Wenn Argumente als Wert übergeben werden, was muß ich dann tun,
damit die Änderungen sich auch in der aufrufenden Funktion widerspiegeln?
Antwort:
Am Tag 8 werden wir die Zeiger besprechen. Mit Zeigern kann man dieses
Problem lösen und gleichzeitig die Beschränkung, nur einen Wert von einer
Funktion zurückzuliefern, umgehen.
Frage:
Was passiert, wenn ich die folgenden beiden Funktionen in ein und
demselben Programm deklariere?
int Area (int width, int length = 1);
int Area (int size);
Werden diese Funktionen überladen? Die Anzahl der Parameter ist unterschiedlich, aber der erste Parameter hat einen Standardwert.
Antwort:
Die Deklarationen werden zwar kompiliert, wenn man aber Area() mit einem
Parameter aufruft, erhält man einen Fehler zur Kompilierzeit: 'Area': Mehrdeutiger
Aufruf einer ueberladenen Funktion.
Der Workshop enthält Quizfragen, die Ihnen helfen sollen, Ihr Wissen zu festigen, und Übungen, die Sie anregen sollen, das eben Gelernte umzusetzen und eigene Erfahrungen zu sammeln. Versuchen Sie, das Quiz und die Übungen zu beantworten und zu verstehen, bevor Sie die Lösungen in Anhang D lesen und zur Lektion des nächsten Tages übergehen.
Perimeter() auf, die einen vorzeichenlosen Integer (unsigned long int) zurückgibt und zwei Parameter, beide vom Typ unsigned short int, übernimmt.
Perimeter(), wie in Übung 1 beschrieben. Die zwei Parameter stellen die Länge und Breite eines Rechtecks dar. Die Funktion soll den Umfang (zweimal die Länge plus zweimal die Breite) zurückliefern.
#include <iostream.h>
void myFunc(unsigned short int x);
int main()
{
unsigned short int x, y;
y = myFunc(int);
cout << "x: " << x << " y: " << y << "\n";
}
void myFunc(unsigned short int x)
{
return (4*x);
}
#include <iostream.h>
int myFunc(unsigned short int x);
int main()
{
unsigned short int x, y;
y = myFunc(x);
cout << "x: " << x << " y: " << y << "\n";
}
int myFunc(unsigned short int x);
{
return (4*x);
}
unsigned short übernimmt und das Ergebnis der Division des ersten Arguments durch das zweite Argument zurückliefert. Führen Sie die Division nicht durch, wenn die zweite Zahl Null ist, sondern geben Sie -1 zurück.
© Markt&Technik Verlag, ein Imprint der Pearson Education Deutschland GmbH