Nur allzu schnell kann es geschehen, daß man durch die Konzentration auf die Syntax von C++ den Blick für die Umsetzung der zu Verfügung stehenden Techniken bei der Programmerstellung aus dem Auge verliert. Heute werden Sie lernen,
C++ wurde als Brücke zwischen C, der weltweit führenden Programmiersprache zur Erstellung kommerzieller Software, und der objektorientierten Programmierung konzipiert. Das Ziel war, objektorientiertes Design und objektorientierte Konzepte für eine effiziente und bewährte Entwicklungsplattform zur Verfügung zu stellen.
C wurde als mittlerer Weg zwischen den höheren Anwendungssprachen, wie COBOL, und der ebenso leistungsfähigen wie schwer zu handhabenden Assemblersprache entwickelt. C sollte zudem zur »strukturierten« Programmierung erziehen, bei der Probleme in kleinere Teilprobleme aufgeschlüsselt und in Form von wiederverwertbaren Prozeduren gelöst wurden.
Die Programme, die wir heute, gegen Ende der Neunziger, erstellen, sind jedoch weit komplexer als die Programme, die noch zu Anfang des Jahrzehnts entwickelt wurden. Programme, die in prozeduralen Sprachen aufgesetzt werden, sind meist nur schwer zu verstehen, schwierig zu warten und kaum auszuweiten und anzupassen. Auf der anderen Seite stehen grafische Benutzeroberflächen, das Internet, digitales Fernsprechwesen und eine Reihe weiterer neuer Technologien, die die Komplexität unserer Programme drastisch erhöhen, sowie ständig steigende Anforderungen der Anwender an die Benutzerschnittstelle.
Angesichts der steigenden Komplexität der Programme warfen die Entwickler einen langen, prüfenden Blick auf den Stand ihrer Technik. Was sie sahen, war entmutigend, wenn nicht schockierend. Der größte Teil der Software war veraltet, bruchstückhaft zusammengeflickt, fehlerbehaftet, unzuverlässig und teuer. Daß Software-Projekte ihre Budgets sprengten und nur mit Verspätung auf den Markt kamen, war praktisch die Regel. Die Kosten zur Erstellung und Wartung dieser Projekte waren nahezu untragbar und ein Großteil des Geldes war schlichtweg verschwendet.
Die objektorientierte Software-Entwicklung bot einen Ausweg aus der Misere. Objektorientierte Programmiersprachen knüpfen eine enge Verbindung zwischen den Datenstrukturen und den Methoden, die diese Daten bearbeiten. Tatsächlich, und dies ist vielleicht das Wichtigste, zwingt uns die objektorientierte Programmierung nicht mehr länger, die unnatürliche Trennung von Datenstrukturen und bearbeitenden Funktionen aufrechtzuerhalten, sondern statt dessen in Objekten, in Dingen, zu denken.
Die Welt ist voller Dinge: Autos, Hunde, Bäume, Wolken, Blumen. Jedes Ding hat seine charakteristischen Eigenschaften (schnell, freundlich, braun, flockig, hübsch). Die meisten Dinge weisen ein bestimmtes Verhalten auf (bewegt sich, bellt, wächst, regnet, verwelkt). Wir sprechen nicht von den Daten einen Hundes und wie wir diese bearbeiten könnten, wir sehen einen Hund als ein Ding dieser Welt und beobachten, wie er ist und was er tut.
Um mit komplexen Sachverhalten fertig zu werden, bedient man sich passender Modelle. Ziel des Modells ist es, die Realität so zu abstrahieren, daß das Modell einfacher ist als die reale Welt, aber immer noch genau genug, um mit Hilfe des Modells das Verhalten der Dinge in der realen Welt vorhersagen zu können.
Ein Schülerglobus ist ein klassisches Modell. Das Modell ist nicht das Ding selbst - niemand würde den Globus mit der Erde verwechseln -, aber es ist genau genug, daß wir durch Studium des Globus etwas über die Erde lernen können.
Natürlich gibt es signifikante Vereinfachungen. Auf dem Globus meiner Tochter regnet es nicht, es gibt keine Überflutungen, keine Erdbeben etc. Trotzdem kann ich mit Hilfe ihres Globus abschätzen, wie lange ich für den Flug von meiner Heimatstadt zum Sitz des Verlags benötige, falls die Redakteure wissen wollen, warum ich mein Manuskript so spät abgegeben habe.
Ein Modell, das keine Vereinfachung darstellt, ist keine große Hilfe. Steven Wright scherzte einmal über solche Modelle: »Ich habe eine Karte, auf der jeder Meter auf einen Meter abgebildet ist. Ich selbst lebe in Quadrat E5 der Karte.«
Objektorientiertes Software-Design bedeutet, gute Modelle zu finden. Es umfaßt zwei wichtige Aspekte: Modelliersprache und Vorgehensweise.
Die Modelliersprache ist sicherlich der unbedeutendere Aspekt bei der objektorientierten Analyse und dem objektorientierten Design, doch unglücklicherweise wird ihr oftmals die größte Aufmerksamkeit zuteil. Eine Modelliersprache ist nichts anderes als eine Konvention, wie wir unser Modell auf Papier zeichnen. So könnte man beispielsweise beschließen, Klassen als Dreiecke und Vererbungsbeziehungen als gepunktete Linien zu zeichnen. Ein Modell für eine Geranie sähe dann wie in Abbildung 18.1 aus.
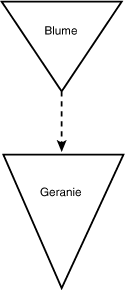
Abbildung 18.1: Generalisierung / Spezialisierung
Der Abbildung können Sie entnehmen, daß eine Geranie eine spezielle Art von Blume ist. Nachdem wir uns darüber geeinigt haben, unsere Vererbungsdiagramme immer auf diese Weise zu zeichnen, gibt es keine Mißverständnisse mehr bei der Interpretation der Diagramme. Mit der Zeit werden wir noch etliche weitere Beziehungen modellieren wollen und wir werden unser eigenes komplexes Regelwerk zum Zeichnen von Diagrammen formulieren.
Den Leuten, mit denen wir zusammenarbeiten, müssen wir unsere Zeichenkonventionen erklären, und jeder neue Angestellte oder Mitarbeiter muß diese Regeln erlernen. Es wird sich vielleicht ergeben, daß wir mit anderen Firmen zusammenarbeiten, die ihre eigenen Konventionen haben, und wir müssen einkalkulieren, daß es einige Zeit benötigen wird, bis ein gemeinsames Regelwerk erarbeitet und alle Mißverständnisse ausgeräumt sind.
Einfacher wäre es natürlich, wenn man sich in der Industrie auf eine gemeinsame Modelliersprache verständigen könnte (ebenso wie es praktisch wäre, wenn alle Menschen die gleiche Sprache sprechen würden). Die Lingua Franca der Software-Entwicklung heißt UML, die Unified Modeling Language. Aufgabe von UML ist es, Fragen wie: »Wie sollen wir eine Vererbungsbeziehung zeichnen?« zu beantworten. Das Geranien-Diagramm aus Abbildung 18.1 würde in UML beispielsweise wie in Abbildung 18.2 zu sehen gezeichnet.
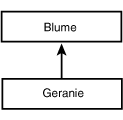
Abbildung 18.2: UML-Darstellung einer Spezialisierung
In UML werden Klassen als Rechtecke und Vererbungen als Pfeile dargestellt. Interessanterweise weist der Pfeil von der stärker spezialisierten Klasse zur allgemeineren Klasse. Für die meisten Leute widerspricht diese Darstellung der intuitiven Sichtweise, doch spielt dies letztlich keine Rolle, sofern man sich nur einig ist.
Ansonsten ist UML nicht schwer zu begreifen. Die Diagramme sind leicht zu verstehen, und ich werde Ihnen im weiteren Verlauf des Kapitels die Sprache UML anhand der Diagramme zum Text erklären. Zwar kann man zu UML auch ohne Mühe ganze Bücher schreiben, doch letztlich benötigt man als Programmierer in 90 % aller Fälle nur eine kleine Untermenge von UML und diese Untermenge ist leicht zu erlernen.
Wie man bei der objektorientierten Analyse und beim Software-Design vorgehen soll, ist ein weitaus wichtigerer und komplexerer Aspekt als die Auswahl einer Modelliersprache. Kein Wunder also, daß man über diesen Aspekt weit weniger hört. Hinzukommt, daß die Frage der Modelliersprache prinzipiell schon beantwortet ist: Die Industrie hat sich weitgehend auf UML geeinigt. Die Diskussion über die richtige Vorgehensweise dauert dagegen noch an.
Leute, die Methoden (Kombinationen aus Modelliersprache und Vorgehensweise) entwickeln oder studieren, bezeichnet man als Methodologen. Zu den führenden Methodologen gehören: Grady Booch, der die Booch-Methode entwickelte, Ivar Jacobson, der Erfinder des objektorientierten Software-Engineerings, und James Rumbaugh, auf den die Object-Modeling-Technologie (OMT) zurückgeht. Zusammen haben diese Männer Objectory entwickelt, eine Methode und das zugehörige Produkt, das von Rational Software vertrieben wird. Alle drei sind übrigens bei Rational Software angestellt, wo man sie liebevoll die drei »Amigos« nennt.
Dieses Kapitel folgt größtenteils der Objectory-Methode. Daß ich nicht ganz der Objectory-Methode folge, liegt daran, daß ich von der sklavische Bindung an akademische Theorien nicht viel halte - mir ist es wichtiger, ein Produkt zur Marktreife zu bringen, statt einer Theorie zu folgen. Andere Methoden haben auch ihre Vorteile und ich bin eher der eklektische Typ, der sich, was er braucht herauspickt und zu einem praktikablen Ganzen zusammenfaßt.
Software-Design ist ein iterativer Prozeß. Dies bedeutet, daß wir bei der Software- Entwicklung wiederholt den ganzen Prozeß von vorne bis hinten durchlaufen - in dem Bemühen, die Zusammenhänge und Anforderungen immer besser zu verstehen. Zwar soll das Design die Implementierung bestimmen, doch tauchen bei der Implementierung oft Details auf, die bis dahin weder erkannt noch berücksichtigt wurden und die dann rückwirkend in das Design einfließen. Wichtig ist, gar nicht erst den Versuch zu machen, größere Projekte in einem einzigen, wohlgeordneten und durchplanten Lauf zu realisieren; besser ist es, die einzelnen Abschnitte des Prozesses zu iterieren und dabei Design und Implementierung stetig zu verbessern.
Das Gegenteil der iterativen Entwicklung ist ein Verfahren, daß ich gerne die Wasserfall-Methode nenne. Bei diesem Verfahren wird das Ergebnis einer Stufe immer zum Input der nächsten Stufe - ein Zurück gibt es nicht (siehe Abbildung 18.3). Bei der Wasserfall-Methode werden die Anforderungen bis ins Detail festgelegt und der Kunde segnet sie ab (»Ja, das ist genau das, was ich haben möchte«). Die in Stein gemeißelten Anforderungen werden dann an den Designer übergeben. Der Designer erstellt das Design (was wirklich eine Leistung ist) und reicht es weiter an den Programmierer, der mit der Implementierung beginnt. Der Programmierer wiederum reicht seinen Code an einen Software-Tester weiter und liefert es schließlich an den Kunden aus. Hört sich in der Theorie wunderbar an, ist in der Praxis aber meist ein einziges Desaster.
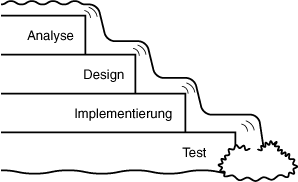
Abbildung 18.3: Die Wasserfall-Methode
Das iterative Design beginnt mit einem Konzept oder einer Vision, auf deren Grundlage wir die Anforderungen ausarbeiten. Während wir immer weiter in die Details hinabsteigen, gewinnt die Vision an Substantialität, bis die Anforderungen so weit ausformuliert sind, daß wir mit dem Design beginnen können - wobei uns vollkommen klar ist, daß Fragen, die beim Design auftauchen, Änderungen an den Anforderungen erforderlich machen können. Während wir an dem Design arbeiten, beginnen wir mit der Erstellung von Prototypen und der Implementierung des Produkts. Neue Aspekte, die sich während des Entwicklungsprozesses ergeben, finden Eingang in das Design und helfen uns unter Umständen sogar, die Anforderungen genauer zu spezifizieren. Dabei entwerfen und implementieren wir immer nur Teile des Endprodukts, während wir durch die Design- und Implementierungsphasen iterieren.
Leider läßt sich das iterative, in Zyklen ablaufende Verfahren nicht in gleicher Weise zu Papier bringen. Wenn ich also im folgenden die einzelnen Phasen nacheinander beschreibe, denken Sie bitte daran, daß alle diese Phasen im Laufe der Entwicklung eines einzigen Produktes mehrfach durchlaufen werden.
Zu den Phasen des iterativen Designs gehören:
Konzeptionierung steht für die Vision, die geniale Idee, mit der alles beginnt. Die Analyse ist der Prozeß, in dem es darum geht, die Anforderungen zu verstehen. In der Design-Phase wird das Modell für die Klassen erstellt, auf dessen Grundlage der Code aufgesetzt wird. Implementierung bedeutet, das Modell in einen Code (beispielsweise C++) umzusetzen. Die Testphase soll sicherstellen, daß das Programm sich wie gewünscht verhält. Zum Schluß wird das Produkt an die Kunden ausgeliefert.
Es gibt endlose Debatten darüber, was genau in den einzelnen Phasen des iterativen Designs zu geschehen hat und wie man die einzelnen Phasen am besten bezeichnen sollte. Hier ein Geheimnis: Es spielt keine Rolle. Die wesentlichen Phasen sind im Prinzip immer die gleichen: herausfinden, was benötigt wird, eine Lösung entwerfen, die Lösung umsetzen.
Auch wenn sich zahlreiche Newsgroups und mit objektorientierter Technologie befaßte Mailinglisten in ausgedehnten Haarspaltereien ergehen, so stehen die wesentlichen Grundzüge objektorientierter Analyse und objektorientierten Designs doch fest und sind leicht zu begreifen. Ich werde Ihnen in diesem Kapitel einen praktischen Ansatz vorstellen, nach dem Sie die Architektur Ihrer Anwendungen aufbauen können.
Ziel all´ dieser Bemühungen ist es, einen Code zu produzieren, der den aufgestellten Anforderungen entspricht, der sicher, erweiterbar und gut zu warten ist. Das wichtigste Ziel aber ist, einen qualitativ hochstehenden Code innerhalb der gesetzten Fristen und ohne Überziehung des Budgets zu entwickeln.
Jedes gute Programm beginnt mit einer Vision. Irgend jemand hat eine Idee für ein Produkt, von dem er überzeugt ist, daß man es realisieren sollte. Selten sind es Komitees, die begeisternde Visionen entwickeln. Der erste Schritt bei der objektorientierten Software-Entwicklung besteht nun darin, diese Vision in einem einzigen Satz (höchstens einem Absatz) auszudrücken. Die Vision wird zum Leitprinzip für das Entwicklungsteam, das die Vision Realität werden lassen soll. Das Entwicklungsteam sollte sich immer wieder auf die Vision rückbesinnen und, falls nötig, die Formulierung der Vision im Zuge des Entwicklungsprozesses aktualisieren.
Die Vision sollte immer von einer einzigen Person kommen. Wurde die Vision von einem Komitee, beispielsweise beim Treffen der Marketingabteilung, formuliert, sollte eine Person zum Visionär auserkoren werden. Aufgabe des Visionärs ist es, den »Gral« zu hüten. Wenn im weiteren Verlauf die Anforderungen für die erste Iteration aufgesetzt und womöglich aus Zeitgründen oder zur Anpassung an die Marktbedingungen wieder und wieder überarbeitet werden, ist es seine Aufgabe, darauf zu achten, daß das angestrebte Produkt der Vision treu bleibt. Es ist seine unnachsichtige Bestimmtheit, seine passionierte Hingabe, die das Projekt zur Vollendung führt. Wenn man die Vision aus dem Auge verliert, ist das Projekt schon zum Scheitern verurteilt.
Die Phase der Konzeptionierung, in der die Vision in Worte gefaßt wird, ist üblicherweise recht kurz. Manchmal ist es nur ein einziger Geistesblitz und die Phase dauert nicht länger als der Visionär braucht, den Einfall zu Papier zu bringen. Oft werden Sie, als Experte für objektorientierte Programmierung, erst zu dem Projektteam hinzugebeten, wenn die Vision schon ausformuliert ist.
In manchen Firmen wird die Formulierung der Vision mit der Formulierung der Anforderungen durcheinandergebracht. Eine starke Vision ist absolut notwendig, aber sie ist nicht ausreichend. Um weiterzukommen, muß man verstehen, wie das Produkt eingesetzt werden wird und welche Aufgaben es erfüllen muß. Diese Fragen zu beantworten und als Anforderungen zu Papier zu bringen, ist das Ziel der Analyse-Phase. Das Ergebnis der Analyse ist das Anforderungspapier. Der erste Abschnitt des Anforderungspapiers umfaßt die Analyse der Nutzungsfälle (Englisch: use cases).
Kern und treibender Motor von Analyse, Design und Implementierung sind die Nutzungsfälle. Ein Nutzungsfall ist nichts anderes als eine Beschreibung der Art und Weise, in der das Produkt genutzt wird. Die Nutzungsfälle dienen nicht nur der Analyse, sie beeinflussen auch das Design, helfen, die erforderlichen Klassen zu finden, und sind noch einmal von besonderer Bedeutung für das Testen des Produkt.
Die mit Abstand wichtigste Aufgabe bei der Analyse ist wohl die Erstellung eines verläßlichen und umfassenden Satzes von Nutzungsfällen. In dieser Phase ist die Hilfe der Bereichsexperten gefragt, denn diese kennen am besten die Bedürfnisse der Geschäftsbereiche, die das Produkt erobern soll.
Nutzungsfälle kümmern sich wenig um Benutzerschnittstellen oder die Interna des zu erstellenden Systems. Systeme und Personen, die mit dem System interagieren, werden als Aktoren bezeichnet.
Zusammengefaßt haben wir es mit folgenden Begriffen zu tun:
Nutzungsfälle beschreiben die Interaktion zwischen einem Aktor und dem System. Bei der Nutzungsfallanalyse wird das System als »black box« angesehen. Der Aktor »sendet eine Nachricht« an das System, woraufhin irgend etwas geschieht: Bestimmte Informationen werden zurückgeliefert, der Zustand des Systems ändert sich, das Raumschiff ändert den Kurs, was auch immer.
Es ist wichtig, sich von dem Gedanken freizumachen, das Aktoren Menschen sein müßten. Systeme, die mit dem System, das Sie erstellen, interagieren, sind ebenfalls Aktoren. Würde man beispielsweise einen Bankautomaten entwickeln, wären nicht nur der Kunde und der Bankangestellte mögliche Aktoren, sondern auch die Systeme, an die Ihr System angeschlossen ist - beispielsweise Hypotheken- oder Darlehenssysteme. Die wesentlichen Eigenschaften eines Aktors sind:
Einen Einstieg zu finden, ist oft das Schwierigste an der Nutzungsfallanalyse. In solchen Fällen hilft es oft weiter, eine Teamsitzung einzuberufen und alles aufzuschreiben, was den Teammitgliedern einfällt.
Setzen Sie eine Liste der Personen und Systeme auf, die mit Ihrem neuen System interagieren. (Wenn ich hier von Personen rede, meine ich im Grunde Rollen: den Bankangestellten, den Manager, den Kunden und so weiter.)
Für das Beispiel unseres Bankautomaten könnte eine solche Liste folgende Rollen enthalten:
Für den Anfang reicht es vollkommen, nur die offensichtlichen Rollen in die Liste aufzunehmen. Drei oder vier Aktoren können vollkommen ausreichend sein, um in die Erstellung von Nutzungsfällen einzusteigen. Jeder der Aktoren interagiert mit dem System auf seine eigene Art und Weise. Diese Interaktionen wollen wir in den Nutzungsfällen auffangen.
Beginnen wir mit der Rolle des Kunden. In unserer Teamsitzung könnten folgende Nutzungsfälle für den Kunden zusammentragen worden sein:
Sollten wir zwischen den Nutzungsfällen »Der Kunde zahlt Geld auf sein Girokonto ein« und »Der Kunde zahlt Geld auf sein Sparkonto ein« unterscheiden oder sollten wir beide Nutzungsfälle zu »Der Kunde zahlt Geld auf sein Konto ein« zusammenfassen (wie in obiger Liste geschehen)? Die Antwort hängt davon ab, ob diese Unterscheidung innerhalb der Domäne sinnvoll ist oder nicht.
Um zu entscheiden, ob für diese Aktionen ein oder zwei Nutzungsfälle aufzusetzen sind, müssen Sie sich die Frage stellen, ob die Abläufe (was macht der Kunde beim Einzahlen) und die Ergebnisse (wie antwortet das System) für beide Fälle verschieden sind. In unserem Beispiel ist die Antwort in beiden Fällen »Nein«: Die Einzahlungen auf beide Konten laufen im wesentlichen identisch ab, und das Ergebnis ist auch grundsätzlich das gleiche (der Bankautomat erhöht den Kontostand um den eingezahlten Betrag).
Da Aktor und System sich bei Einzahlungen auf Giro- und Sparkonto im wesentlichen identisch verhalten und reagieren, handelt es sich tatsächlich um einen einzigen Nutzungsfall. Später, wenn wir für die Nutzungsfälle einzelne Szenarien ausarbeiten, können wir die beiden Varianten austesten, um zu sehen, ob es überhaupt einen Unterschied gibt.
Während Sie sich Gedanken um die Rolle der verschiedenen Aktoren machen, sollten Sie sich die folgenden Fragen stellen, die Ihnen helfen können, weitere Nutzungsfälle auszumachen:
Weitere Nutzungsfälle findet man meist, indem man sich auf die Attribute der Objekte in der Domäne konzentriert. Der Kunde verfügt beispielsweise über einen Namen, eine PIN, eine Kontonummer. Haben wir Nutzungsfälle zur Verwaltung dieser Objekte? Ein Konto besteht aus Kontonummer, Kontostand und der Aufzeichnung der vorgenommenen Transaktionen. Haben wir in unseren Nutzungsfällen an diese Elemente gedacht?
Nachdem wir die Nutzungsfälle für den Kunden zusammengetragen haben, überlegen wir uns in gleicher Weise Nutzungsfälle für die anderen Aktoren. Wie ein erster brauchbarer Satz von Nutzungsfällen für das Bankautomaten-Beispiel aussehen könnte, zeigt die folgende Liste:
Ist der erste Satz von Nutzungsfällen aufgesetzt, können Sie darangehen, Ihr Anforderungspapier um ein detailliertes Domänen-Modell zu erweitern. Das Domänen-Modell ist ein Dokument, in dem Sie alles festhalten, was Sie über die betreffende Domäne (den Geschäftsbereich, um den es geht) wissen. Als Teil des Domänen-Modells erzeugen Sie Domänen-Objekte, die die Objekte aus Ihren Nutzungsfällen beschreiben. In unserem Bankautomaten-Beispiel gibt es derzeit die folgenden Objekte: Kunde, Bankpersonal, Back-Office-System, Girokonto, Sparkonto und so weiter.
Zu jedem dieser Objekte versuchen wir, die wichtigsten Daten zu erfassen: den Namen des Objekts (z.B. Kunde, Konto etc.), ob es sich bei dem Objekt um einen Aktor handelt, die wichtigsten Attribute und Verhaltensweisen des Objekts und so weiter. Viele Modellierungstools unterstützen das Zusammentragen dieser Informationen durch sogenannte »class«-Beschreibungen. In Abbildung 18.4 sehen Sie, wie diese Informationen in Rational Rose aufgenommen werden.
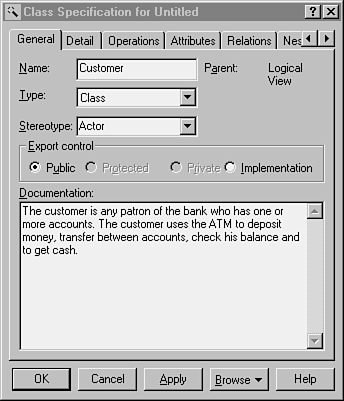
Beachten Sie, daß wir hier keine Design-Objekte, sondern die Objekte der Domäne beschreiben. Wir dokumentieren, wie sich die reale Welt verhält, und nicht, wie unser System arbeitet.
Mit Hilfe von UML können wir für unser Bankautomaten-Beispiel die Beziehungen zwischen den Objekten der Domäne als Diagramm darstellen - also unter Verwendung der gleichen Diagrammkonventionen, die wir später zur Beschreibung der Beziehungen zwischen den Klassen der Domäne verwenden werden. Dies ist eine der großen Stärken von UML: Wir können das gleiche Tool in allen Phasen des Projekts verwenden.
Beispielsweise können wir mit Hilfe der UML-Konventionen festhalten, daß Girokonten und Sparkonten Spezialisierungen des allgemeineren Konzepts eines Bankkontos sind (siehe Abbildung 18.5)
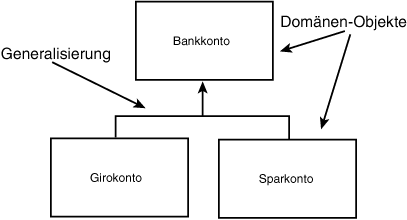
Abbildung 18.5: Spezialisierung
In dem Diagramm aus Abbildung 18.5 repräsentieren die Rechtecke die verschiedenen Domänen-Objekte und die Pfeile stehen für Generalisierungen. UML schreibt vor, daß diese Pfeile von der spezialisierten Klasse zur allgemeinen »Basis-«Klasse gezeichnet werden. Aus diesem Grunde weisen Girokonto und Sparkonto auf Bankkonto.
Ich möchte noch einmal betonen, daß wir im Moment immer noch von Beziehungen zwischen Domänen-Objekten sprechen. Später werden Sie vermutlich entscheiden, zwei Klassen, Girokonto und Sparkonto, in Ihr Design aufzunehmen und deren Beziehung als Vererbung zu implementieren, doch dies sind Entscheidungen, die in der Design-Phase getroffen werden. Während der Analyse beschränken wir uns darauf, unser Verständnis der Domänen-Objekte niederzuschreiben.
UML ist eine leistungsfähige Modellierungssprache, und Sie können beliebig viele Beziehungen definieren. Die wichtigsten Beziehungen, die bei der Analyse erfaßt werden, sind: Generalisierung (oder Spezialisierung), Einbettung und Assoziation.
Generalisierung wird häufig mit »Vererbung« gleichgesetzt, doch es gibt einen wichtigen Unterschied. Generalisierung beschreibt die Beziehung, Vererbung die Implementierung der Generalisierung (wie die Generalisierung in Code umgewandelt wird).
Generalisierung impliziert, daß das abgeleitete Objekt ein Untertyp des Basisobjekts ist. Folglich ist ein Girokonto ein Bankkonto. Die Beziehung ist symmetrisch: Ein Bankkonto verallgemeinert das grundsätzliche Verhalten und die Attribute von Giro- und Sparkonten.
Während der Domänen-Analyse versuchen wir, diese Beziehungen, wie sie in der realen Welt existieren, zu erfassen.
Häufig setzt sich ein Objekt aus mehreren Unterobjekten zusammen. So besteht ein Auto beispielsweise aus Steuerrad, Reifen, Türen, Radio und so weiter. Zu einem Girokonto gehören der Kontostand, die Liste der vorgenommenen Transaktionen, eine PIN und so weiter. Wir sprechen davon, daß das Girokonto diese Elemente enthält. Die Einbettung modelliert diese Beziehung. In UML wird die Einbettung durch Linien mit einer Raute dargestellt, die von dem übergeordneten Objekt zum eingebetteten Objekt weisen (siehe Abbildung 18.6).
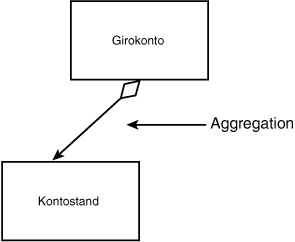
Das Diagramm aus Abbildung 18.6 besagt, daß ein Girokonto ein Kontostand-Element enthält. Aus den Diagrammen der Abbildungen 18.5 und 18.6 kann man schon ein recht komplexes Beziehungsgeflecht erstellen (siehe Abbildung 18.7).
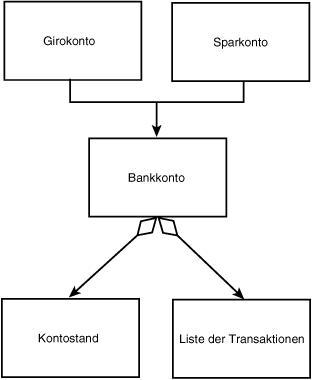
Abbildung 18.7: Beziehungen zwischen den Objekten
Das Diagramm aus Abbildung 18.7 besagt, daß Girokonto und Sparkonto beides Bankkonten sind und daß alle Bankkonten über einen Kontostand und eine Liste der bisherigen Transaktionen verfügen.
Die dritte Beziehung, die bei der Domänen-Analyse üblicherweise auftritt, ist die einfache Assoziation. Assoziation bedeutet, daß zwei Objekte voneinander wissen und in irgendeiner Weise interagieren. In der Design-Phase läßt sich dies noch weiter präzisieren; im Moment, da wir uns noch in der Analyse-Phase befinden, wollen wir dadurch nur ausdrücken, daß Objekt A und Objekt B interagieren, aber weder eines im anderen enthalten ist noch eine Spezialisierung des anderen darstellt. In UML wird die Assoziation durch eine einfache gerade Linie zwischen den Objekten dargestellt (siehe Abbildung 18.8).
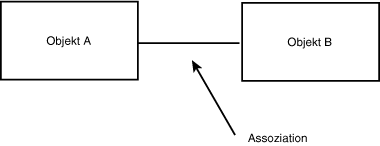
Nachdem wir einen ersten Satz von Nutzungsfällen zusammengetragen haben und über die Tools zum Zeichnen der Beziehungen zwischen den Domänen-Objekten verfügen, sind wir soweit, daß wir die Nutzungsfälle weiter ausarbeiten können.
Für jeden Nutzungsfall kann eine Serie von Szenarien entworfen werden. Ein Szenario ist schlichtweg ein Satz spezieller Umstände, die das Zusammenspiel der einzelnen Elemente des Nutzungsfalls beeinflussen. So könnte man für den Nutzungsfall »Der Kunde hebt Geld von seinem Konto ab« folgende Szenarien entwerfen:
Und so weiter. Jedes Szenario ist eine Variation des ursprünglichen Nutzungfalls. Viele dieser Variationen fangen Ausnahmebedingungen ab (nicht genug Geld auf dem Konto, nicht genug Geld im Automaten etc.). Manchmal erforschen die Variationen kleine Verschiebungen im Ablauf des Nutzungsfalls (»der Kunde möchte eine Überweisung tätigen, bevor er Geld abhebt«).
Nicht jedes denkbare Szenario muß auch wirklich erforscht werden. Konzentrieren Sie sich auf Szenarien, die die Grenzen des Systems ausloten und spezielle Interaktionen mit dem Aktor beleuchten.
Zur von Ihnen eingesetzten Methode gehört auch, daß Sie Richtlinien für die Dokumentation der einzelnen Szenarien aufstellen. Diese Richtlinien werden ebenfalls im Anforderungspapier festgehalten. Üblicherweise versucht man sicherzustellen, daß zu jedem Szenario folgende Angaben gemacht werden:
Zusätzlich werden Sie noch jedem Nutzungfall und jedem Szenario einen Namen geben wollen, so daß die Niederschrift eines Szenarios insgesamt wie folgt aussehen würde:
Dieser Nutzungsfall kann durch ein extrem einfaches Diagramm versinnbildlicht werden (siehe Abbildung 18.9).
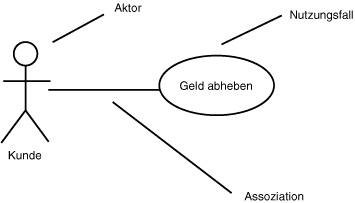
Abbildung 18.9: Nutzungsfalldiagramm
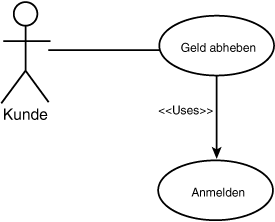
Abbildung 18.10: Der »uses«-Stereotyp
Das Diagramm aus Abbildung 18.9 zeigt wenig mehr als die starke Abstraktion einer Interaktion zwischen Aktor (dem Kunden) und dem System. Ein wenig interessanter wird es, wenn Interaktionen zwischen Nutzungsfällen in das Diagramm mit aufgenommen werden. Ich sage »ein wenig«, weil es zwei mögliche Interaktionen zwischen Nutzungsfällen gibt: »uses« und »extends«. Der »uses«-Stereotyp zeigt an, daß ein Nutzungsfall dem anderen übergeordnet ist. So ist es beispielsweise nicht möglich, Bargeld abzuheben, ohne sich zuvor bei dem System anzumelden. Man kann diese Beziehung durch das Diagramm aus Abbildung 18.10 verdeutlichen.
Abbildung 18.10 besagt, daß der »Geld abheben«-Nutzungsfall den »Anmelden«-Nutzungsfall verwendet (»uses«) und somit den »Anmelden«-Fall als Teil von »Geld abheben« vollständig durchführt.
Der »extends«-Nutzungsfall war dafür gedacht, konditionierte Beziehungen und so etwas Ähnliches wie die Vererbung anzuzeigen, doch es herrscht in der Objektmodellierungsgemeinde so viel Verwirrung über die korrekte Unterscheidung zwischen »uses« und »extends«, daß viele Entwickler einfach auf »extends« verzichten. Ich persönlich verwende »uses« in Fällen, wo ich ansonsten den ganzen Nutzungsfall an die betreffende Stelle kopieren würde, und »extends«, wenn ich den Nutzungsfall nur unter bestimmten, definierbaren Bedingungen verwenden würde.
Auch wenn das Diagramm des Nutzungsfalls für sich genommen nur von begrenztem Wert ist, können Sie durch die Verbindung von Diagrammen und Nutzungsfall die Dokumentation und Beschreibung der Interaktionen drastisch verbessern. So wissen wir beispielsweise, daß das »Geld abheben«-Szenario die Interaktionen zwischen den folgenden Domänen-Objekten darstellt: Kunde, Girokonto und Benutzerschnittstelle. Wir können diese Interaktion durch ein Interaktionsdiagramm verdeutlichen (siehe Abbildung 18.11).
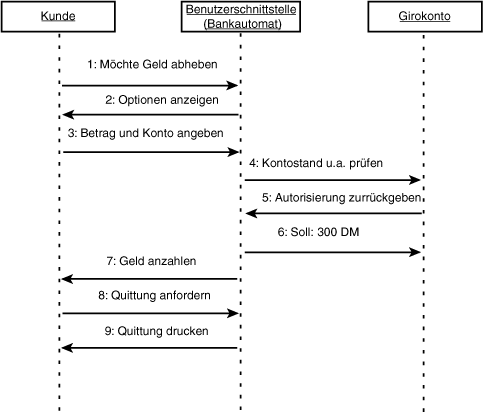
Abbildung 18.11: UML-Interaktionsdiagramm
Im Interaktionsdiagramm aus Abbildung 18.12 werden Details des Szenarios sichtbar, die beim Lesen des Textes nicht so deutlich zu erkennen sind. Die Objekte, die dabei interagieren, sind Domänen-Objekte, und die gesamte Benutzerschnittstelle des Bankautomaten wird als ein einziges Objekt aufgefaßt - lediglich das Bankkonto wird im Detail ausgearbeitet.
Unser recht einfaches Bankautomaten-Beispiel zeigt nur einige wenige Interaktionen. Aber gerade das Herausarbeiten der Spezifika dieser Interaktionen ist ein wichtiger Schritt, um die Probleme der Domäne und die Anforderungen an das neue System zu verstehen.
Komplexere Probleme bedingen meist die Erstellung einer Vielzahl von Nutzungsfällen. UML erlaubt es Ihnen daher, Ihre Nutzungsfälle in Pakete zu bündeln.
Ein Paket ist wie ein Verzeichnis oder ein Ordner - es ist eine Ansammlung von Modellierungsobjekten (Klassen, Aktoren und so weiter). Um komplexe Nutzungsfälle besser verwalten zu können, haben Sie die Möglichkeit, Pakete nach beliebigen Gesichtspunkten zusammenzustellen. So können Sie Ihre Nutzungsfälle nach Kontotyp (alles, was Giro- und Sparkonto betrifft), nach Kreditaufnahme und Kontobelastung, nach Kundentyp oder nach beliebig anderen Kriterien zusammenstellen. Darüber hinaus kann ein einzelner Nutzungsfall in verschiedene Pakete aufgenommen werden, was Ihnen alle erdenkliche Freiheit bei der Zusammenstellung der Pakete läßt.
Neben den von Ihnen erarbeiteten Nutzungsfällen gehören in das Anforderungspapier auch die Wünsche des Kunden, etwaige Beschränkungen, die Anforderungen an Hardware und Betriebssystem. Anwendungsanforderungen sind spezielle Vorgaben des Kunden - Dinge, die man ansonsten während des Designs oder der Implementierung entscheiden würde.
Anwendungsanforderungen ergeben sich oft aus der Notwendigkeit, mit einem bestehenden (eventuell übernommenen) System zusammenzuarbeiten. In solchen Fällen ist es wichtig, in der Analyse zu erarbeiten, was das System macht und wie es arbeitet.
Im Idealfall würde man das Problem analysieren, eine Lösung entwerfen und dann die am besten geeignete Plattform und das Betriebssystem bestimmen. In der Realität sind Idealfälle allerdings rar. Meist hat der Kunde bereits in ein bestimmtes Betriebssystem oder eine Hardware-Plattform investiert und möchte, daß die neue Software auf seinem bestehenden System läuft. Nehmen Sie diesen Wunsch frühzeitig in Ihre Anforderungsliste auf und richten Sie Ihr Design danach.
Manche Programme sind vollkommen eigenständig und interagieren nur mit dem Endanwender. Andere Programme müssen eine Schnittstelle zu einem bestehenden System einrichten. Bei der Systemanalyse werden alle Details über die Systeme zusammengetragen, mit denen Ihr Programm interagieren muß. Handelt es sich bei Ihrem neuen System um einen Server, der seine Dienste bestehenden Systemen zur Verfügung stellt, oder handelt es sich um eine Client-Anwendung? Können Sie die Schnittstelle zwischen den Systemen selbst mit ausarbeiten, oder müssen Sie sich an eine bestehende Schnittstellenspezifikation halten. Ist das andere System stabil oder müssen Sie mit Schwankungen rechnen?
Diese und andere Fragen müssen in der Analyse-Phase beantwortet werden. Versuchen Sie auch zu erarbeiten, welche Anforderungen und Beschränkungen die Interaktion mit anderen Systemen dem eigenen System aufbürdet. Wird die Schnelligkeit und Leistungsfähigkeit Ihres Systems belastet? Muß Ihr System große Mengen von Eingaben seitens der anderen Systeme verarbeiten und Zeit und Ressourcen dafür opfern?
Nachdem Sie verstanden haben, was Ihr System leisten und wie es arbeiten soll, ist es an der Zeit, eine erste Zeit- und Kostenanalyse aufzusetzen. Der Fertigstellungstermin wird meist durch den Kunden vorgegeben: »In 18 Monaten muß das System laufen«. Im Idealfall würden Sie Ihren Anforderungskatalog durchsehen und abschätzen, wie lange Sie für das Design und die Implementierung des Programms benötigen. Dies ist der Idealfall; in der Realität werden Ihnen meist Zeit- und Kostenlimits vorgegeben, und das Problem ist abzuschätzen, wieviel der gewünschten Funktionalität in der zu Verfügung stehenden Zeit und ohne Überschreitung der zugebilligten Kosten realisiert werden kann.
Folgende Punkte sollten Sie bei der Erstellung des Kosten- und Zeitplans berücksichtigen:
Unter diesen Gegebenheiten ist es wichtig, einen sinnvollen Arbeitsplan zu erstellen. Fertig werden Sie nicht - das sollten Sie im Auge behalten. Kommt es soweit, daß Sie den Fertigstellungstermin verpassen, ist es wichtig, daß Ihr Programm, so weit es gediegen ist, funktions- und lauffähig ist und als erstes Release durchgehen kann. Stellen Sie sich vor, sie erbauen eine Brücke und haben das Zeitlimit überschritten. Wenn Sie es nicht mehr geschafft haben, den Fahrradweg über die Brücke einzurichten, ist das nicht so schlimm. Sie können die Brücke trotzdem eröffnen. Wenn Sie das Zeitlimit überschreiten, während die Brücke nur halb über den Fluß führt, ist das unvergleichlich unangenehmer.
Was Sie über Planungsdokumente unbedingt wissen sollten, ist, daß diese nie stimmen. So früh im Entwicklungsprozeß ist es praktisch unmöglich, auch nur eine halbwegs verläßliche Abschätzung des Zeitaufwands für das Projekt abzugeben. Ist der Anforderungskatalog fertiggestellt, können Sie ziemlich genau sagen, wie lange Sie für die Design-Phase brauchen werden, Sie können abschätzen, wie lange die Implementierung dauern wird und Sie können einen ungefähren Zeitraum für die Testphase angeben. Geben Sie dann noch zwischen 20 und 25 % Spielraum hinzu, und Sie sollten in etwa mit Ihrer Zeit hinkommen.
Die Zugabe von 20 bis 25 % Spielraum soll keine Entschuldigung dafür sein, bei der Erstellung der Planungsdokumente nachlässig zu sein. Doch selbst auf sorgfältig ausgearbeitete Zeit- und Kostenpläne sollte man nicht zu sehr vertrauen. Je weiter das Projekt voranschreitet, um so besser lernen Sie Ihr System verstehen und um so genauer lassen sich Zeit- und Kostenaufwand abschätzen.
Zu guter Letzt wird das Anforderungspapier mit Diagrammen, Bildern, Bildschirmabbildungen, Prototyp-Skizzen und anderem grafischen Material ausgeschmückt, das Ihnen hilft, eine bessere Vorstellung vom Design der grafischen Benutzerschnittstelle des Produkts zu bekommen.
Für größere Projekte bietet es sich an, einen Prototypen zu entwickeln, der Ihnen (und Ihren Kunden) hilft, das System besser zu verstehen. Manche Teams verwenden einen Prototyp als lebendiges Anforderungspapier und realisieren das System als Implementierung der vom Prototyp angedeuteten Funktionalität.
Am Ende der Analyse- wie auch der Design-Phase setzen Sie eine Reihe von Dokumenten auf, die sogenannten Artefakte. In Tabelle 18.1 sehen Sie die Artefakte der Analyse-Phase aufgelistet. Anhand dieser Dokumente vergewissert sich der Kunde, daß Sie verstanden haben, was er benötigt, die Endanwender melden Verbesserungsvorschläge an das Team und das Team selbst benötigt die Dokumente für das Design und die Implementierung des Codes. Etliche dieser Dokumente sind auch unabdingbar für das Dokumentationsteam und die Qualitätssicherungsabteilung, die den Dokumenten entnehmen können, wie sich das System verhalten soll.
Tabelle 18.1: Artefakte, die während der Analyse-Phase der Projektentwicklung erstellt werden
Während sich die Analyse auf die Ergründung des Problems konzentriert, geht es beim Design um die Ausarbeitung einer Lösung. Design bedeutet hierbei, unser Verständnis der Anforderungen in ein Modell umzusetzen, das als Software implementiert werden kann. Das Ergebnis dieses Prozesses ist die Fertigstellung eines Design-Dokuments.
Das Design-Dokument gliedert sich in zwei Abschnitte: Klassendesign und Architektur. Der Klassendesign-Abschnitt wiederum gliedert sich in Statisches Design (mit Details zu den verschiedenen Klassen, ihren Beziehungen und Charakteristika) und Dynamisches Design (mit Angaben zur Interaktion der Klassen).
Im Architektur-Abschnitt des Design-Dokuments halten Sie fest, wie Sie Objektpersistenz, verteilte Objektsysteme und anderes implementieren wollen. Der Rest dieses Kapitels ist dem Klassendesign-Abschnitt des Design-Dokuments gewidmet, in den weiteren Kapiteln dieses Buches finden Sie Informationen über die Implementierung verschiedener Architekturkonzepte.
Als C++-Programmierer sind Sie den Umgang mit Klassen natürlich gewohnt, doch für die weiteren Ausführungen müssen Sie zwischen den C++-Klassen und den Design-Klassen unterscheiden - auch wenn beide eng miteinander verwandt sind. Die C++-Klassen, die Sie in Ihrem Code aufsetzen, sind die Implementierungen Ihrer Design-Klassen. Dies ist eine isomorphe Abbildung: Jede Klasse aus Ihrem Design korrespondiert mit einer Klasse aus Ihrem Code. Trotzdem sollte man beide auseinanderhalten. So ist es durchaus möglich, die Design-Klassen in einer anderen Sprache zu implementieren oder die Syntax der Klassendefinition zu ändern.
Nachdem dies nun geklärt ist, möchte ich anmerken, daß wir im folgenden meist einfach
über Klassen reden, ohne explizit zwischen beiden Erscheinungen einer Klasse zu
trennen. Wenn es heißt, daß die Katzen-Klasse Ihres Modells eine Miau()-Methode
hat, bedeutet dies auch, daß Ihre C++-Klasse eine Miau()-Methode erhalten soll.
Die Modellklassen werden in einem UML-Diagramm festgehalten, die C++-Klassen in einem Code, der kompiliert werden kann. Die Unterscheidung ist sinnvoll, wenn auch subtil.
Wie auch immer, die größte Hürde für Novizen ist, einen ersten Satz von Klassen zu finden und zu verstehen, was eine gut entworfene Design-Klasse auszeichnet. Eine simple Technik, diese Hürde zu nehmen, besteht darin, die Nutzungsfall-Szenarien niederzuschreiben und für jedes Substantiv eine Klasse zu erstellen. Betrachten wir das folgende Nutzungsfall-Szenario:
Der Kunde möchte Bargeld von seinem Girokonto abheben. Auf dem Konto ist genügend Geld, der Bankautomat hat ausreichend Geld und Quittungen, das Netzwerk ist hochgefahren und läuft. Der Bankautomat fordert den Kunden auf, den Betrag für die Abhebung anzugeben und der Kunde fordert 300,- DM - ein zur Zeit legaler Betrag. Die Maschine gibt 300,- DM aus und druckt eine Quittung. Der Kunde nimmt das Geld und die Quittung.
Aus diesem Szenario lassen sich die folgenden Klasse ableiten:
Synonyme Eintragungen kann man zusammenfassen und erhält dann die folgende Liste, für deren einzelne Einträge man Klassen erstellt:
So weit ist dies kein schlechter Anfang. Als nächsten Schritt könnte man jetzt die offensichtlichen Beziehungen zwischen den einzelnen Einträgen der Klasse in ein Diagramm eintragen (siehe Abbildung 18.12).
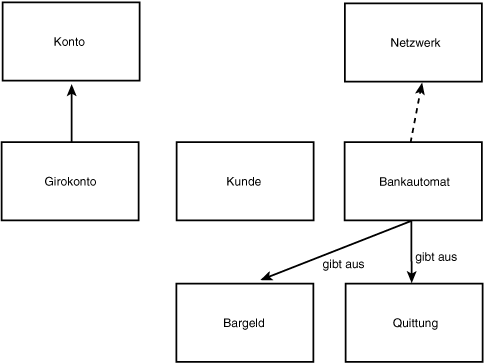
Abbildung 18.12: Erste Klassen
Womit wir im vorangehenden Abschnitt begonnen haben, war nur vordergründig die Aussortierung der Substantive aus dem Szenario. Tatsächlich haben wir damit begonnen, Objekte aus der Analyse-Domäne in Design-Objekte zu transformieren. Häufig verhält es sich nämlich so, daß es für viele Objekte in der Domäne korrespondierende Objekte (Surrogate oder Stellvertreter) im Design gibt. Von Surrogaten sprechen wir, um zwischen der eigentlichen physischen Empfangsbestätigung, die vom Bankautomat ausgegeben wird, und dem Objekt in unserem Design, das nur eine geistige, als Code implementierte Abstraktion ist, zu unterscheiden.
Vermutlich werden Sie feststellen, daß es für die meisten Domänen-Objekte eine isomorphe Repräsentation im Design gibt - daß also eine Eins-zu-Eins-Entsprechung zwischen den Domänen-Objekten und den Design-Objekten besteht. Es ist aber auch möglich, daß ein einziges Domänen-Objekt im Design durch eine ganze Reihe von Design-Objekten respräsentiert wird, und manchmal korrespondieren eine Reihe von Domänen-Objekten mit einem einzigen Design-Objekt.
Beachten Sie, daß wir in Abbildung 18.14 bereits der Tatsache Rechnung getragen
haben, daß Girokonto eine Spezialisierung von Konto ist. Diese Beziehung ist so evident,
daß wir ihr nicht erst groß nachspüren mußten. Von der Domänen-Analyse her
wußten wir, daß der Bankautomat sowohl Bargeld als auch Quittungen ausgibt. Wir haben
daher auch diesen Punkt direkt in unser Diagramm einfließen lassen.
Die Beziehung zwischen Kunde und Girokonto ist nicht so offensichtlich. Wir wissen,
daß eine solche Beziehung existiert, aber ihre Details sind noch verborgen. Wir werden
diese Beziehung später ausarbeiten.
Nachdem Sie die Domänen-Objekte transformiert haben, können Sie nach weiteren nützlichen Design-Objekten Ausschau halten. Ein guter Ausgangspunkt ist hierfür die Betrachtung der Schnittstellen. Jede Schnittstelle zwischen Ihrem neuen System und irgendeinem bestehenden System sollte in eine Schnittstellenklasse gekapselt werden. Wenn Sie beispielsweise mit einer Datenbank kommunizieren, ist diese zweifelsohne ein guter Kandidat für eine eigene Schnittstellenklasse.
Die Schnittstellenklassen ermöglichen die Kapselung des Schnittstellenprotokolls und schotten dadurch Ihren Code von Änderungen in den anderen Systemen ab. Schnittstellenklassen erlauben Ihnen, Ihr eigenes Design oder das Design anderer Systeme zu ändern, ohne daß der jeweilige Rest des Codes davon betroffen ist. Solange sich beide Systeme an die vereinbarte Schnittstellenspezifikation halten, können beide Systeme unabhängig voneinander weiterentwickelt werden.
Auch für Datenmanipulationen erstellen wir Klassen. Wenn Sie Daten von einem Format in ein anderes konvertieren müssen (etwa von Fahrenheit in Celsius oder von englischen Längenangaben ins metrische System), empfiehlt es sich, diese Manipulationen in eine eigene Klasse zu kapseln. Man kann diese Technik für die Aufbereitung von Daten für die Weitergabe an ein anderes System oder die Übertragung via Internet nutzen - praktisch jedes Mal, wenn man Daten in ein bestimmtes Format bringen muß, kapselt man das zugehörige Protokoll in eine Datenmanipulationsklasse.
Jede »Ausgabe«, jeder »Bericht«, den Ihr System generiert, ist ein Kandidat für eine Klasse. Die Regeln, nach denen der Bericht erstellt wird (sowohl das Zusammentragen der Daten wie auch deren Präsentation), werden am sinnvollsten in einer eigenen Klasse gekapselt.
Wenn Ihr System mit externen Geräten zusammenarbeitet oder diese manipuliert (Drucker, Modems, Scanner und so weiter), sollte das Geräteprotokoll in einer Klasse gekapselt werden. Auch hier gilt, daß Sie sich durch die Erstellung eigener Klassen für die Schnittstelle zu den Geräten die Überarbeitung des restlichen Programmcodes ersparen, wenn ein neues Gerät mit neuem Protokoll eingestöpselt wird; alles was Sie tun müssen, ist eine neue Schnittstellenklasse aufzusetzen, die die neue Schnittstelle unterstützt.
Nachdem ein erster Satz von Klassen gefunden wurde, kann man mit der Modellierung der Beziehungen und Interaktionen zwischen den Klassen beginnen. Um nicht unnötig Verwirrung zu stiften, werde ich zuerst das statische Modell und danach das dynamische Modell erklären, obwohl Sie während des Design-Prozesses frei zwischen statischer und dynamischer Modellierung hin- und herwechseln und neue Klassen gleich einzeichnen werden.
Das statische Modell konzentriert sich auf drei Punkte: Verantwortungsbereich, Attribute und Beziehungen. Der wichtigste Punkt - der, auf den Sie sich zuerst konzentrieren sollten - sind die Verantwortungsbereiche jeder Klasse. Dabei gilt, daß »Jede Klasse für eine einzige Sache verantwortlich sein sollte«.
Das soll nun nicht bedeuten, daß die einzelnen Klassen nur jeweils über eine Methode verfügen sollten. Weit gefehlt, viele Klasse werden Dutzende von Methoden haben. Aber alle diese Methoden müssen auf ein Ziel ausgerichtet sein, d.h., sie müssen alle in Beziehung zueinander stehen und dazu beitragen, daß die Klasse ihren einen Aufgabenbereich erfüllen kann.
In einem wohldurchdachten System ist jedes Objekt eine Instanz einer wohldefinierten und wohlverstandenen Klasse, die für eine bestimmte Aufgabe verantwortlich ist. Verwandte oder untergeordnete Aufgaben werden von den Klassen typischerweise an andere Klassen delegiert. Durch die Beschränkung der Klassen auf jeweils einen Verantwortungsbereich fördert man die Erstellung eines gut zu wartenden Codes.
Um herauszufinden, welches die Verantwortungsbereiche Ihrer Klassen sind, kann es hilfreich sein, die Design-Arbeit mit CRC-Karten zu beginnen.
CRC steht für Class (Klasse), Responsibility (Verantwortungsbereich) und Collaboration (Kollaboration). Eine CRC-Karte ist nichts anderes als eine Karteikarte. Mit diesem einfachen Hilfsmittel und ein paar Kollegen können Sie sich effektiv in die Verantwortungsbereiche Ihrer anfänglichen Klassen einarbeiten. Besorgen Sie sich einen Stapel von Karteikarten, und setzen Sie sich mit Ihren Kollegen für ein paar CRC-Kartensitzungen an einen Konferenztisch.
An einer CRC-Sitzung sollten idealerweise drei bis sechs Leute teilnehmen. Mehr Teilnehmer machen das Verfahren unhandlich. Einer der Teilnehmer sollte die Sitzung leiten. Seine Aufgabe ist es, die Sitzung in Gang zu halten und den Teilnehmern beim Verarbeiten der gemachten Erfahrungen zu helfen. Zumindest einer der Teilnehmer sollte Software-Architekt sein, idealerweise jemand mit großer Erfahrung in objektorientierter Analyse und objektorientiertem Design. Des weiteren wird man mindestens zwei »Domänen-Experten« dazubitten, die die Systemanforderungen kennen und Ratschläge und Hinweise zum Ablauf der Szenarien geben können.
Das Wichtigste an einer CRC-Sitzung ist aber, daß keine übergeordneten Manager teilnehmen. CRC-Sitzungen sollten frei und kreativ sein und nicht davon beeinträchtigt werden, daß die Teilnehmer das Gefühl haben, ihren Boss beeindrucken zu müssen. Das Ziel der Sitzungen ist es, Erfahrungen zu machen, Risiken einzugehen, die Verantwortungsbereiche der Klassen auszuloten und besser verstehen zu lernen, wie die Klassen interagieren.
Die CRC-Sitzung beginnt damit, daß sich die Gruppe um den Konferenztisch versammelt. Auf dem Tisch liegt ein kleiner Stapel von Karteikarten. Oben auf die Vorderseite der Karten schreiben Sie die Klassennamen, auf jede Karte eine Klasse. Darunter ziehen Sie eine Linie von oben nach unten, die die Karte in zwei Hälften teilt. Die linke Hälfte überschreiben Sie mit Verantwortungen, die rechte Hälfte mit Kollaborationen.
Füllen Sie zuerst die Karten für die wichtigsten der identifizierten Klassen aus. Setzen Sie für jede Klasse ein Beschreibung (ein oder zwei Sätze) auf der Rückseite der Karte auf. Wenn Sie jetzt schon wissen, welche andere Klassen diese Klasse spezialisiert, können Sie auch diese Information festhalten. Legen Sie einfach unter dem Klassennamen eine Zeile »Basisklasse:« an und schreiben Sie den Namen der Klasse, von der die aktuelle Klasse abgeleitet ist, daneben.
Ziel der CRC-Sitzung ist die Identifizierung der Verantwortungsbereiche der einzelnen Klassen. Verschwenden Sie Ihre Energie nicht auf die Attribute, erfassen Sie während der Sitzung nur die offensichtlichen und wirklich wesentlichen Attribute - wichtig ist die Identifizierung der Verantwortungsbereiche. Ist eine Klasse bei der Erfüllung ihrer Aufgabe darauf angewiesen, Arbeiten an andere Klassen zu delegieren, halten Sie diese Information unter Kollaborationen fest.
Behalten Sie während des Verlaufs der Sitzung Ihre Verantwortungenliste im Auge. Wenn der Platz auf Ihrer Karteikarte nicht mehr ausreicht, sollten Sie sich fragen, ob diese Klasse nicht zuviel Aufgaben übernimmt. Denken Sie daran, daß jede Klasse grundsätzlich nur für einen Aufgabenbereich verantwortlich sein sollte und daß die aufgelisteten Verantwortungen alle zusammengehören sollten (d.h., die Klasse bei der Erfüllung Ihres Verantwortungsbereichs unterstützen sollten).
Die Beziehungen zwischen den Klassen, die Konzeptionierung der Klassenschnittstelle oder die Aufteilung in öffentliche und private Methoden interessieren uns zu diesem Zeitpunkt nicht. Konzentrieren Sie sich ganz darauf, was die einzelnen Klassen machen.
CRC-Karten sollten anthropomorph sein, das heißt, Sie sollten den einzelnen Klassen menschliche Züge zuweisen. Das funktioniert so: Nachdem Sie einen anfänglichen Satz von Klassen zusammengetragen haben, kehren Sie zurück zu Ihrem CRC-Szenario. Verteilen Sie die Karten zufällig auf die Teilnehmer, und spielen Sie das Szenario mit den anderen durch. Nehmen wir zum Beispiel noch einmal folgendes Szenario:
Der Kunde möchte Bargeld von seinem Girokonto abheben. Auf dem Konto ist genügend Geld, der Bankautomat hat ausreichend Geld und Quittungen, das Netzwerk ist hochgefahren und läuft. Der Bankautomat fordert den Kunden auf, den Betrag für die Abhebung anzugeben und der Kunde fordert 300,- DM, ein zur Zeit legaler Betrag. Die Maschine gibt 300,- DM aus und druckt eine Quittung. Der Kunde nimmt das Geld und die Quittung.
Nehmen wir weiter an, es nehmen fünf Leute an unserer CRC-Sitzung teil: Amy, die Leiterin und objektorientierte Designerin, Barry, der Chefprogammierer, Charlie, der Kunde, Dorris, die Domänen-Expertin und Ed, ein Programmierer.
Amy hält eine CRC-Karte hoch, die die Klasse Girokonto repräsentiert, und sagt: »Ich
informiere den Kunden darüber, wieviel Geld verfügbar ist. Der Kunde fordert mich
auf, ihm 300,- DM auszugeben. Ich schicke eine Nachricht an die Ausgabe, mit der
Aufforderung, dem Kunden 300,- DM auszuzahlen.« Barry hält seine Karte hoch und
sagt: »Ich bin die Ausgabe. Ich spucke 300,- DM aus und sende Amy eine Nachricht
mit der Aufforderung, den Kontostand um 300,- DM zu verringern. Wie aber teile ich
der Maschine mit, daß sie jetzt 300,- DM weniger hat? Überwache ich selbst das Bargelddepot
des Automaten?« Charlie sagt: »Ich denke, wir brauchen ein eigenes Objekt,
das überwacht, wieviel Geld im Automaten ist.« Ed sagt: »Nein, die Ausgabe sollte den
Geldbestand überwachen. Das ist ihre Aufgabe.« Amy ist damit nicht einverstanden:
»Nein, irgend jemand muß die Ausgabe von Bargeld koordinieren. Die Ausgabe muß
wissen, ob Bargeld verfügbar ist und ob der Kunde genügend Geld auf seinem Konto
hat. Sie muß das Geld abzählen und ausgeben. Die Verantwortung für die Überwachung
des Bargelddepots sollte sie delegieren - an irgendeine Art von internem Konto.
Wer auch immer den Stand des Bargelddepots überwacht, kann dann das Back-
Office-System informieren, wenn es Zeit ist, das Depot aufzufüllen. Für die Ausgabe
ist das zuviel Verantwortung.«
So geht die Diskussion weiter. Durch Hochhalten der Karten und Interaktion mit den anderen, werden die Anforderungen und Delegationsmöglichkeiten ausgelotet. Jede Klasse wird quasi lebendig, ihre Verantwortungen treten klar zu Tage. Wenn die Gruppe in Design-Fragen steckenbleibt, kann der Leiter durch einen Schiedsspruch der Gruppe helfen, die Diskussion wieder aufzunehmen.
Auch wenn CRC-Karten ein äußerst nützliches Hilfsmittel sind, um mit dem Design zu beginnen, so haben sie doch ihre Grenzen. Das erste Problem liegt darin, daß sie für umfangreiche Projekte sehr unhandlich sind. Bei komplexen Systemen kann es schnell passieren, daß man von der Zahl der CRC-Karten überwältigt und es schwierig wird, alle Klassen im Auge zu behalten.
Zudem werden Beziehungen zwischen Klassen von den CRC-Karten nicht erfaßt. Es stimmt zwar, daß Kollaborationen notiert werden, doch wird deren Natur nur schlecht modelliert. Man kann beim Blick auf die Karten nicht erkennen, welche Klassen andere Klassen einschließen, welche Klasse eine andere erzeugt und so weiter. Schließlich sind CRC-Karten statisch. Sie können die Interaktionen zwischen den Klassen nachspielen, aber die CRC-Karten selbst erfassen diese Information nicht.
Zusammengefaßt bedeutet dies, daß die CRC-Karten Ihnen einen guten Start verschaffen, Sie aber danach noch die Klassen in UML überführen müssen, wenn Sie ein robustes und vollständiges Modell Ihres Designs erhalten wollen. Die Überführung in UML ist zwar nicht so schwierig, aber es ist eine Einbahnstraße. Nachdem Sie Ihre Klassen in UML-Diagramme eingebaut haben, gibt es kein Zurück. Sie legen die CRC- Karten beiseite und werden Sie nicht mehr aufnehmen, denn die Synchronisierung der beiden Modelle ist zu aufwendig.
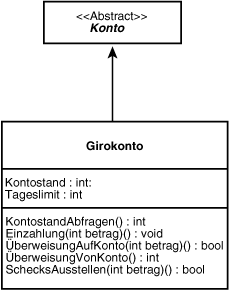
Jede CRC-Karte läßt sich direkt in eine UML-modellierte Klasse umwandeln. Verantwortungen werden dabei zu Methoden, und die Attribute, die Sie bereits erfaßt haben, werden zu Datenelementen. Die Klassenbeschreibung auf der Rückseite der Karte wird zur Dokumentation der Klasse verwendet. Abbildung 18.13 verdeutlicht die Beziehung zwischen der CRC-Karte für das Girokonto und der aus der Karte erzeugten UML-Klasse.
Nach der Überführung der Klassen in UML kann man damit beginnen, die Beziehungen zwischen den verschiedenen Klasse herauszuarbeiten. Die wichtigsten Beziehungen, die man dabei modelliert sind:
Die Generalisierung wird in C++ durch die public-Vererbung implementiert. Während
des Designs interessiert uns aber weniger der zugrundeliegende Mechanismus als
vielmehr die Semantik: Was impliziert diese Beziehung?
Wir haben die Generalisierung schon einmal in der Analyse-Phase untersucht. Anders als bei der Analyse konzentrieren wir uns nicht mehr ausschließlich auf die Objekte in der Domäne, sondern auch auf die Design-Objekte. Allgemeine Funktionalität der Klassen lagern wir in Basisklassen aus, um in diesen die gemeinsame Verantwortungen zu kapseln.
Wenn Sie gemeinsame Funktionalität auslagern, verschieben Sie diese Funktionalität
von den spezialisierten Klassen zu den allgemeineren Klassen. Wenn ich also bemerke,
daß ich sowohl für mein Giro- wie auch mein Bankkonto Methoden zum Einzahlen
und Abheben von Geld benötige, verschiebe ich die TransferGeld()-Methode in die
Basisklasse Konto. Je mehr Funktionalität Sie aus den abgeleiteten Klassen in die Basisklassen
verschieben, um so polymorpher wird Ihr Design.
Eine besondere Eigenschaft von C++, die Java nicht zur Verfügung stellt, ist die mehrfache Vererbung (Java kennt nur mehrfache Schnittstellen, die eine ähnliche, aber stärker eingeschränkte Technik darstellen). Die Mehrfachvererbung gestattet es, eine Klasse von mehreren Basisklassen abzuleiten, und dadurch die Elemente und Methoden von zwei oder mehr Klassen in eine abgeleitete Klasse einzuführen.
Die Erfahrung lehrt, die Mehrfachvererbung nur behutsam und wohlüberlegt einzusetzen, denn sie kompliziert sowohl Design als auch Implementierung. Viele Probleme, die früher durch Mehrfachvererbung gelöst wurden, werden heute mittels Aggregation gelöst. Dennoch ist die Mehrfachvererbung ein mächtiges Hilfsmittel, und manche Designs erfordern einfach, daß eine Klasse das Verhalten mehrerer Basisklassen spezialisiert.
Ist ein Objekt die Summe seiner Einzelteile? Ist es sinnvoll, wie in Abbildung 18.14,
ein Auto-Objekt als eine Spezialisierung von Steuerrad, Tuer und Reifen zu modellieren?
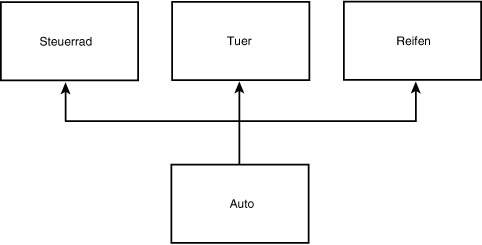
Abbildung 18.14: Falsche Vererbung
Hier ist es wichtig, sich auf die Grundlagen zu besinnen: public-Vererbung sollte stets
eine Generalisierung modellieren. Allgemein sagt man, daß die Vererbung eine »Ist-
ein«-Beziehung modelliert. Wenn Sie dagegen eine »hat-ein«-Beziehung vorliegen haben
(wie zum Beispiel ein Auto ein Steuerrad enthält), bedienen Sie sich dazu der Aggregation
(siehe Abbildung 18.15).
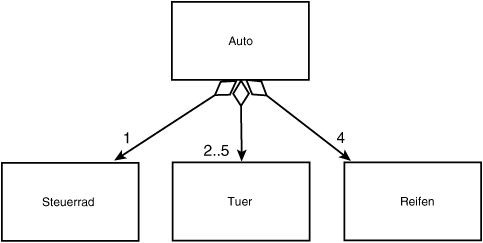
Das Diagramm aus Abbildung 18.15 verdeutlicht, daß ein Auto über ein Steuerrad, vier Reifen und zwei bis fünf Türen verfügt. Dies ist eine weit genauere Modellierung der Beziehung zwischen einem Auto und seinen Teilen. Beachten Sie, daß die Raute in dem Diagramm nicht ausgefüllt ist: Dies zeigt an, daß wir die Beziehung als Aggregation und nicht als Komposition modellieren. Komposition impliziert die Kontrolle über die gesamte Lebensdauer des Objekts. Obwohl ein Auto Reifen und Türen hat, können die Reifen und Türen existieren, bevor sie zu Teilen des Autos werden, und sie können auch noch weiterexistieren, wenn sie nicht mehr Teile des Autos sind.
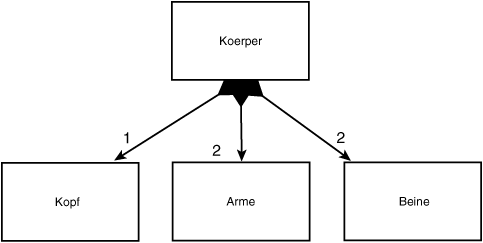
Abbildung 18.16 modelliert die Komposition. Das Modell besagt, daß ein Körper nicht nur eine Aggregation von Kopf, zwei Armen und zwei Beinen ist, sondern daß diese Objekte (Kopf, Arme, Beine) zusammen mit dem Körper erzeugt werden und verschwinden, wenn der Körper verschwindet. Sie führen also keine unabhängige Existenz. Der Körper ist aus diesen Elementen zusammengesetzt, und die Lebensdauer der Elemente und des Körpers sind gekoppelt.
Wie würde ein Klassen-Design aussehen, daß die verschiedenen Modelle eines Automobilherstellers repräsentiert? Nehmen wir an, Sie wären von einem namhaften Automobilhersteller engagiert, der augenblicklich fünf Wagen in seinem Programm hat: den Pluto (ein langsamer, kompakter Wagen mit wenig PS), die Venus (eine viertürige Limousine mit durchschnittlicher PS-Stärke), den Mars (ein Sportcoupé mit kraftvollem Motor für maximale Leistung), den Jupiter (ein Minivan, ausgestattet mit dem gleichen Motor wie der Mars, aber für niedrigere Drehzahlen) und die Erde (ein Kombi mit weniger PS, aber hoher Drehzahl).
Sie könnten damit beginnen, für jedes der Modelle eine eigene Klasse von der Basisklasse
Auto abzuleiten und dann für jeden Wagen, der vom Fließband rollt, eine Instanz
zu erzeugen (siehe Abbildung 18.17).
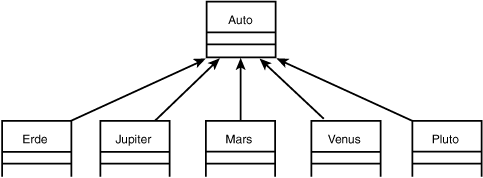
Abbildung 18.17: Modellierung abgeleiteter Typen
Worin unterscheiden sich diese Modelle? Sie unterscheiden sich in der Leistung des Motors, in der Form und ihrem Fahrverhalten. Diese Eigenschaften können vermischt und zu neuen Modellen kombiniert werden. In UML kann man dies durch den Diskriminator-Stereotyp darstellen (siehe Abbildung 18.18).
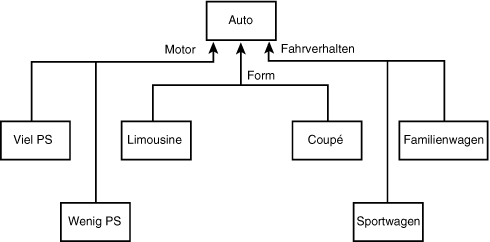
Abbildung 18.18: Modellierung der Diskriminatoren
Das Diagramm aus Abbildung 18.18 besagt, daß Klassen von der Basisklasse Auto durch Kombination der drei unterscheidenden (im Englischen: discriminating) Attribute abgeleitet werden können. Die PS-Zahl des Motors bestimmt, wie leistungsstark der Wagen ist, das Fahrverhalten beschreibt, wie sportlich der Wagen ist. So kann man einen leistungsstarken, sportlichen Kombi oder eine Familienlimousine mit geringer PS- Zahl oder irgendeinen anderen Wagen kreieren.
Die einzelnen Attribute können durch Aufzählungstypen (enum) implementiert werden.
So könnte die Form des Wagens durch folgenden Code implementiert werden:
enum Form = { limousine, coupe, minivan, kombi };
Für manche Diskriminatoren ist die Umsetzung als einfacher Wert ungenügend. So dürfte beispielsweise das Fahrverhalten recht komplex sein. In so einem Fall modelliert man den Diskriminator als Klasse und kapselt die Unterschiede in Instanzen der Klasse.
Zur Modellierung des Fahrverhaltens könnte man einen eigenen Typ mit Informationen
über Gangschaltung und maximale Drehzahl erstellen. Für Klassen, die Diskriminatoren
kapseln und die benutzt werden können, um aus einer Klasse (Auto) Instanzen
zu erzeugen, die logisch verschiedenen Typen angehören (beispielsweise Sportwagen
versus Luxuswagen), dient in UML der Stereotyp »Powertyp«. In unserem Beispiel ist
die Klasse Fahreigenschaften ein Powertyp für Auto. Wenn Sie ein Instanz der Klasse
Auto bilden, instantiieren Sie auch ein Fahreigenschaften-Objekt und verbinden das
Fahreigenschaften-Objekt mit dem gegebenen Auto (siehe Abbildung 18.19).
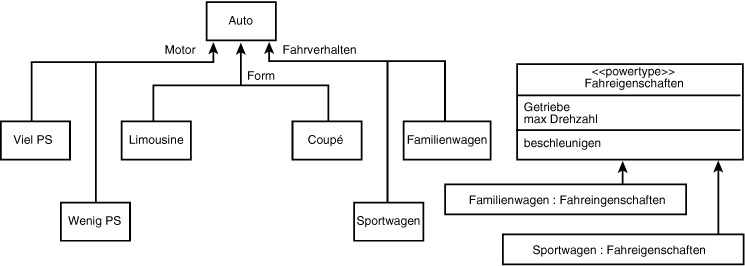
Abbildung 18.19: Diskriminator als Powertyp
Mit Hilfe der Powertypen lassen sich Variationen logischer Typen erzeugen, ohne daß man dazu die Vererbung bemühen und ohne daß man sich mit den kombinatorischen Verwicklungen, wie sie die Vererbung hervorrufen würde, auseinandersetzen muß.
Üblicherweise implementiert man Powertypen in C++ mit Hilfe von Zeigern. In unserem
Beispiel enthält die Klasse Auto einen Zeiger auf eine Instanz der Klasse Fahreigenschaften
(siehe Abbildung 18.20). Die Umwandlung der Form- und Motor-Diskriminatoren
in Powertypen überlasse ich dem engagierten Leser als Übung.
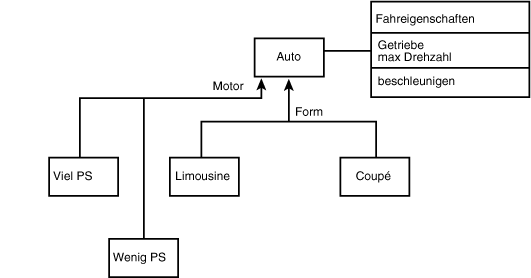
Abbildung 18.20: Beziehung zwischen einem Auto-Objekt und seinem Powertyp
Class Auto : public Fahrzeug
{
public:
Auto();
~Auto();
// weitere public-Methoden
private:
Fahreigenschaften *pFahrverhalten;
};
Abschließend sei noch vermerkt, daß man mit Hilfe der Powertypen zur Laufzeit neue Typen (nicht bloß Instanzen) erzeugen kann. Da sich die logischen Typen nur durch die Attribute unterscheiden, die mit dem Powertyp verbunden sind, können diese Attribute als Parameter an den Konstruktor des Powertyps übergeben werden. Dies bedeutet, daß man zur Laufzeit neue Typen von Autos erzeugen kann. Indem Sie unterschiedliche Maschinengrößen und Getriebe an den Powertyp übergeben, können Sie definitiv neue Fahreigenschaften erzeugen. Indem Sie diese Fahreigenschaften an unterschiedliche Autos weitergeben, vergrößern Sie letztlich zur Laufzeit die Anzahl der verschiedenen Autotypen.
Nur die Beziehungen zwischen den Klassen zu modellieren reicht nicht aus, man muß
auch festhalten, wie die Klassen zusammenarbeiten. So interagieren beispielsweise die
Klassen Girokonto, Bankautomat und Quittung mit dem Kunden, um den Nutzungsfall
»Geld abheben« zu verwirklichen. Wir kehren damit zu dem Sequenzdiagramm zurück,
das wir zum ersten Mal bei der Analyse verwendet haben, und arbeiten das Diagramm
auf der Grundlage der Methoden, die wir für die Klassen entwickelt haben, weiter aus
(siehe Abbildung 18.21).
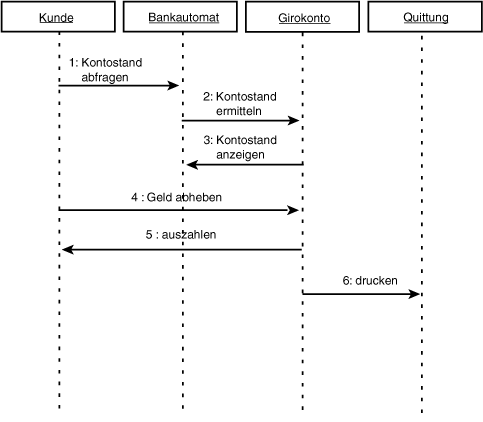
Abbildung 18.21: Sequenzdiagramm
Anhand des einfachen Diagramms aus Abbildung 18.21 kann man verfolgen, welche
Interaktionen sich über die Zeit zwischen einer Reihe von Klassen abspielen. Das Diagramm
deutet an, daß die Bankautomat-Klasse die Verantwortung für die Verwaltung
des Kontostandes an die Klasse Girokonto delegiert, während letztere die Bankautomat-
Klasse zur Anzeige des Kontostandes aufruft.
Es gibt zwei Typen von Interaktionsdiagrammen. Den ersten Typ, das sogenannte Sequenzdiagramm, sehen Sie in Abbildung 18.21. Eine andere Sicht der gleichen Informationen bietet das Kollaborationsdiagramm. Das Sequenzdiagramm streicht vor allem die Abfolge der Ereignisse über die Zeit heraus; das Kollaborationsdiagramm betont die Interaktionen zwischen den Klassen. Kollaborationsdiagramme können direkt aus Sequenzdiagrammen erzeugt werden; Hilfsprogramme wie Rational Rose tun dies auf Knopfdruck (siehe Abbildung 18.22).
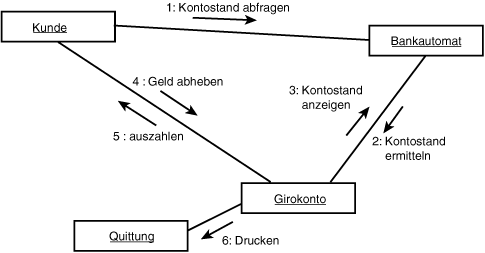
Abbildung 18.22: Kollaborationsdiagramm
Nachdem wir nun schon einiges über die Interaktionen zwischen den Objekten gelernt haben, müssen wir uns noch den verschiedenen Zuständen widmen, die ein einzelnes Objekt einnehmen kann. Die Übergänge zwischen den verschiedenen Zuständen kann man in einem Zustandsdiagramm (oder Zustandübergangsdiagramm) modellieren. Abbildung 18.23 zeigt die verschiedenen Zustände der Girokonto-Klasse, wenn der Kunde sich auf dem System anmeldet.
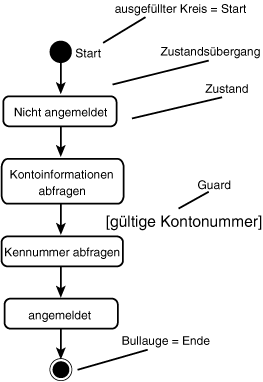
Abbildung 18.23: Kundenkonto-Zustände
Jedes Zustandsdiagramm beginnt mit einem einzigen Startzustand und endet mit Null oder mehr Endzuständen. Die einzelnen Zustände werden mit Namen dargestellt, die Übergänge zwischen den Zuständen werden beschriftet. Der Guard (Wächter) weist auf Bedingungen hin, die erfüllt sein müssen, bevor ein Objekt von einem Zustand zu einem anderen wechseln kann.
Der Kunde kann jederzeit seine Absichten ändern und die Anmeldung abbrechen. Er kann dies tun, nachdem er seine Karte zur Identifizierung des Kontos eingeführt hat, er kann abbrechen, nachdem er seine Kennummer eingegeben hat. In beiden Fällen muß das System seinen Wunsch akzeptieren und in den »Nicht angemeldet«-Zustand zurückkehren.
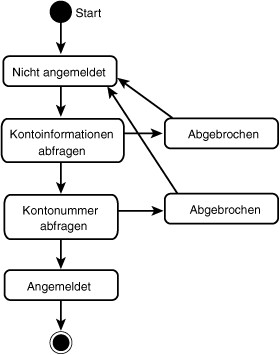
Abbildung 18.24: Kunde bricht Anmeldung womöglich ab
Man kann erahnen, daß diese Behandlung des »Abgebrochen«-Zustands komplexere Diagramme schnell sehr unübersichtlich werden läßt. Dies ist um so ärgerlicher, als das Abbrechen eigentlich eine Ausnahmebedingung ist, die nicht zu sehr von dem eigentlichen Ablauf ablenken sollte. Durch die Einrichtung eines Superzustands, zu sehen in Abbildung 18.25, läßt sich das Diagramm allerdings vereinfachen.
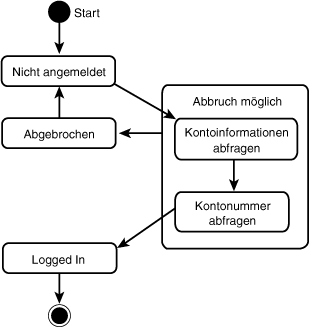
Abbildung 18.25: Kundenkonto-Zustände
Das Diagramm aus Abbildung 18.25 enthält die gleichen Informationen wie das Diagramm aus Abbildung 18.24, ist aber klarer strukturiert und leichter zu lesen. Von dem Moment an, da der Kunde mit der Anmeldung beginnt, bis zu dem Punkt, da das System die Anmeldung abschließt, kann der Prozeß abgebrochen werden. Wird abgebrochen, kehrt das System in den Zustand »Nicht angemeldet« zurück.
Dieses Kapitel gewährte Ihnen einen Einblick in die Grundzüge der objektorientierten Analyse und des objektorientierten Designs. Die wesentlichen Schritte des vorgestellten Ansatzes waren: a) zu analysieren, wie ein System eingesetzt wird (Nutzungsfälle) und welche Aufgaben es erfüllen muß, und b) auf der Grundlage dieser Informationen die Klassen zu entwerfen und die Beziehungen und Interaktionen zwischen den Klassen zu modellieren.
Früher skizzierte man kurz, was man programmieren wollte, und begann dann mit dem Aufsetzen des Codes. Das Problem ist, daß komplexere Projekte auf diese Weise nie wirklich fertiggestellt werden und wenn sie doch einmal abgeschlossen werden, dann sind sie unzuverlässig und schwer zu warten. Heute investiert man vorab in die Analyse der Anforderungen und die Modellierung des Designs und stellt dadurch sicher, daß das fertige Produkt korrekt (entspricht dem Design), robust, verläßlich und erweiterbar ist.
Der Rest des Buches beschäftigt sich größtenteils mit Detailfragen zur Implementierung. Auf Fragen des Austestens und Vertriebs der Software kann im Rahmen dieses Buches nicht eingegangen werden. Ich möchte allerdings noch anmerken, daß der Testplan bereits während der Implementierung und unter Berücksichtigung des Anforderungspapiers erarbeitet wird.
Frage:
Inwiefern unterscheidet sich objektorientierte Analyse und objektorientiertes
Design von anderen Ansätzen?
Antwort:
Vor der Entwicklung dieser objektorientierten Techniken wurden Programme
als eine Sammlung von Funktionen angesehen, die Daten bearbeiteten. Die
objektorientierte Programmierung basiert dagegen auf der Einheit von Daten
und Funktionalität. So spricht man auch davon, daß Pascal- und C-Programme
Sammlungen von Prozeduren sind, während C++-Programme Sammlungen
von Klassen sind.
Frage:
Ist die objektorientierte Programmierung die Lösung zu allen Problemen?
Antwort:
Nein, und sie wollte es auch nie sein. Objektorientierte Analyse, objektorientiertes
Design und objektorientierte Programmierung sind allerdings Hilfsmittel,
mit denen ein Programmierer Projekte von enormer Komplexität in einer
Weise angehen kann, die früher nicht vorstellbar gewesen wäre.
Frage:
Ist C++ die perfekte objektorientierte Sprache?
Antwort:
C++ hat im Vergleich zu anderen objektorientierten Sprachen viele Vor- und
Nachteile. Ein Vorzug zeichnet C++ jedoch vor allen anderen Sprachen aus:
C++ ist die mit Abstand am weitesten verbreitete objektorientierte Programmiersprache,
die es gibt. Seien wir ehrlich: Die meisten Programmierer, die
sich für C++ entscheiden, tun dies nicht nach erschöpfender Analyse der verschiedenen
objektorientierten Programmiersprachen, sondern weil sie dem
aktuellen Trend folgen - und der hieß in den Neunzigern: C++. Man soll diese
Entscheidung nicht geringschätzen. C++ hat viel zu bieten, und es gibt umfangreiche
Unterstützung für C++-Programmierer - ganz abgesehen von diesem
Buch, daß auch nur deshalb existiert, weil C++ von so vielen Firmen
favorisiert wird.
Der Workshop enthält Quizfragen, die Ihnen helfen sollen, Ihr Wissen zu festigen, und Übungen, die Sie anregen sollen, das eben Gelernte umzusetzen und eigene Erfahrungen zu sammeln. Versuchen Sie, das Quiz und die Übungen zu beantworten und zu verstehen, bevor Sie die Lösungen in Anhang D lesen und zur Lektion des nächsten Tages übergehen.
Welche Objekte sollten in der Simulation modelliert werden? Welche Klassen benötigt man für die Simulation?
Ortsansässige, die auch über Ampeln fahren, wenn diese schon auf Rot geschaltet haben, Touristen, die langsam und vorsichtig fahren (meist in angemieteten Wagen), und Taxen, deren Fahrverhalten sich im wesentlichen danach richtet, welche Art von Kunde im Taxi sitzt.
Daneben gibt es zwei Arten von Fußgängern: Ortsansässige, die nach Lust und Laune die Straße überqueren und selten Fußgängerübergänge benutzen, und Touristen, die immer die Fußgängerampeln benutzen.
Schließlich gibt es noch die Fahrradfahrer, die auf keine Ampeln achten.
Wie kann man diese Gegebenheiten in dem Modell berücksichtigen?
© Markt&Technik Verlag, ein Imprint der Pearson Education Deutschland GmbH