

|
|
|
Der Nachteil der linearen Suche ist klar bei einem großen Datensatz dauert die Suche ein wenig länger. Speziell dann, wenn sich das gesuchte Element am Ende der Liste befindet. Hierzu ein einfaches Beispiel der sequenziellen Suche: /* simple_search.c */
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAX 255
struct plz{
char ort[MAX];
unsigned int postleit;
};
struct plz postleitzahlen[100];
static int N;
/* Initialisieren */
void init(void) {
N = 0;
postleitzahlen[N].postleit = 0;
strcpy(postleitzahlen[N].ort, "init");
}
void einfuegen(unsigned int p, char *o) {
postleitzahlen[++N].postleit = p;
strcpy(postleitzahlen[N].ort, o);
}
void suche(unsigned int key) {
int i;
for(i=0; i<=N; i++)
if(postleitzahlen[i].postleit == key) {
printf("Der Ort zur Postleitzahl %d : %s\n",
key,postleitzahlen[i].ort);
return;
}
printf("Für den Wert %d konnte keine Postleitzahl "
"gefunden werden!\n",key);
}
int main(void) {
int wahl;
unsigned int search, post;
char new_ort[MAX];
init();
do {
printf("-1- Postleitzahl suchen\n");
printf("-2- Postleitzahl hinzufügen\n");
printf("-3- Ende\n\n");
printf("Ihre Wahl : ");
scanf("%d",&wahl);
getchar();
if(wahl == 1) {
printf("Welche Postleitzahl suchen Sie : ");
scanf("%5d",&search);
suche(search);
}
else if(wahl == 2) {
printf("Neue Postleitzahl : ");
scanf("%5u",&post);
getchar();
printf("Ort für PLZ %d : ",post);
fgets(new_ort, MAX, stdin);
einfuegen(post, strtok(new_ort, "\n") );
}
} while(wahl!=3);
return EXIT_SUCCESS;
}
Natürlich kann die Suche auch so verändert werden, dass zu einem Ort die Postleitzahl gesucht wird. Dazu muss nur die Suchfunktion ein wenig umgeschrieben werden: void suche(char *o) {
int n=N;
int i;
for(i=0; i<=N; i++)
if(strcmp(postleitzahlen[i].ort,o) == 0) {
printf("Der Ort zur Postleitzahl %d : %s\n",
key,postleitzahlen[i].ort);
return;
}
printf("Für den Wert %s konnte keine Postleitzahl "
"gefunden werden!\n",o);
}
In den einfachsten Fällen bei wenigen Daten dürfte die lineare Suche völlig ausreichend sein.  24.4.2 Binäre Suche
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
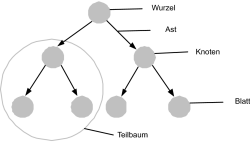
| Wurzel (engl. root) Dieser Knoten ist der einzige, der keinen Vorgänger besitzt. Wie bei einem echten Baum können Sie sich das als Wurzel vorstellen. Nur, dass in der Informatik die Wurzel oben ist. |
| Ast, Kante (engl. edges) Jeder Baum besteht aus einzelnen Knoten, welche mit einem Ast verbunden sind. |
| Knoten (engl. node) Knoten sind die eigentlichen Elemente, welche über alle Informationen wie Daten und Zeiger zum rechten und linken Knoten verfügen. Ein Knoten ist die Struktur selbst. Beim binären Baum hat jeder Knoten nicht mehr als zwei Nachfolger (daher auch bi = zwei). Es gibt zwar auch Bäume mit mehreren Nachfolgern, allerdings handelt es sich dann nicht mehr um einen binären Baum. |
| Blatt (engl. leaf) Blätter sind Knoten, welche keinen Nachfolger besitzen. |
| Teilbaum Ein Knoten mit einem linken und einem rechten Nachfolger wird als Teilbaum bezeichnet. |
| Tiefe (level) Als Tiefe wird die Anzahl der Nachfolgeroperationen bezeichnet, die erforderlich sind, um von der Wurzel des Baums zu einem bestimmten Knoten zu gelangen. Die Tiefe n kann dann 2n 1 einzelne Knoten beinhalten. |
Mit diesem Grundwissen können Sie beginnen, einen binären Baum zu programmieren. Zuerst wird die Struktur eines Knotens benötigt:
struct knoten {
int wert;
struct knoten *links;
struct knoten *rechts;
};
Damit der Umfang des Beispiels nicht zu sehr anwächst, wird sich hier mit der Eingabe eines Werts (int wert) in die Struktur begnügt. Außer dem int-Wert, besitzt die Struktur noch jeweils einen Zeiger auf den linken und einen auf den rechten Nachfolger des Knotens. Somit können Sie sich die Struktur vom Typ knoten so vorstellen:
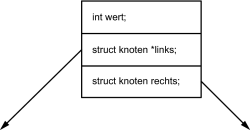
Hier klicken, um das Bild zu Vergrößern
Abbildung 24.19 Die Datenstruktur eines binären Baumes
Als Erstes wird eine Funktion benötigt, mit der Werte in den binären Baum eingeordnet werden. Die kleineren Werte sollen dabei immer auf der linken Seite und die größeren Werte auf der rechten Seite eingeordnet werden. Hier nochmals die Struktur. Es wurde außerdem mit typedef ein neuer Datentyp namens KNOTEN definiert:
struct knoten {
int wert;
struct knoten *links;
struct knoten *rechts;
};
typedef struct knoten KNOTEN;
KNOTEN *einordnen(KNOTEN *zeiger) {
//---->Funktionen ...
Folgende drei Möglichkeiten können beim Einordnen in den binären Baum auftreten:
| 1. | Es befindet sich noch kein Element (genauer: es fehlt noch die Wurzel root) im Baum und das eingefügte ist das erste Element und somit die Wurzel des Baums: |
if(zeiger==NULL) {
zeiger=(KNOTEN*)malloc(sizeof(KNOTEN));
zeiger->wert=zahl;
zeiger->links=zeiger->rechts=NULL;
}
| 2. | Der neue Wert ist kleiner als die Wurzel bzw. bei weiterem Verlauf als der Knoten, und somit wird der neue Wert links von der Wurzel bzw. dem Knoten eingeordnet: |
else if(zeiger->wert >= zahl) zeiger->links=einordnen(zeiger->links);
| Hier erfolgt der erste rekursive Aufruf. Der Zeiger zeiger, der nach links verweist, erhält die Adresse links vom aktuellen Knoten durch einen erneuten Funktionsaufruf mit einordnen(zeiger->links). Dieser erneute Funktionsaufruf muss natürlich noch nicht die Adresse zurückliefern. Der Baum wird so lange weiter nach unten abgesucht, bis ein passender Platz gefunden wurde. | |
| 3. | Die dritte und letzte Möglichkeit: Der Wert des neuen Elements ist größer als die Wurzel bzw. der Knoten. Somit kommt dieses auf die rechte Seite der Wurzel bzw. des Knotens: |
else if(zeiger->wert < zahl) zeiger->rechts=einordnen(zeiger->rechts);
| Trifft die zweite oder dritte Möglichkeit zu, wird der Baum so lange nach rechts oder links durchlaufen (durch weitere rekursive Aufrufe), bis keine der beiden Möglichkeiten mehr zutrifft. Dann wurde der Platz für das neue Element gefunden. | |
Hier die vollständige Funktion zum Einordnen eines neuen Elements im binären Baum mitsamt der main()-Funktion:
/* btree1.c */
#include <stdio.h>
#include <stdlib.h>
struct knoten{
int wert;
struct knoten *links;
struct knoten *rechts;
};
typedef struct knoten KNOTEN;
/* Globale Variable */
int zahl;
KNOTEN *einordnen(KNOTEN *zeiger) {
if(zeiger == NULL) {
zeiger = (KNOTEN *)malloc(sizeof(KNOTEN));
if(zeiger==NULL) {
printf("Konnte keinen Speicherplatz reservieren!\n");
exit (EXIT_FAILURE);
}
zeiger->wert=zahl;
zeiger->links=zeiger->rechts=NULL;
}
else if(zeiger->wert >= zahl)
zeiger->links=einordnen(zeiger->links);
else if(zeiger->wert < zahl)
zeiger->rechts=einordnen(zeiger->rechts);
return (zeiger);
}
int main(void) {
KNOTEN *wurzel=NULL;
do {
printf("Bitte Zahl eingeben : ");
scanf("%d",&zahl);
wurzel=einordnen(wurzel);
} while(zahl != 0);
return EXIT_SUCCESS;
}
Nun der theoretische Ablauf des Programms: Das Programm wurde gestartet, und der erste Wert sei die 10. Jetzt wird mit wurzel=einordnen(wurzel) die Funktion aufgerufen. Bei der ersten Eingabe trifft gleich die erste if-Bedingung zu:
if(zeiger == NULL)
Womit die Zahl 10 das erste Element und gleichzeitig die Wurzel des Baums ist. Die beiden Zeiger links und rechts bekommen den NULL-Zeiger zugewiesen:
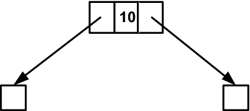
Hier klicken, um das Bild zu Vergrößern
Abbildung 24.20 Die Wurzel des Baums
Als Nächstes sei die Zahl 8 gegeben. Wieder wird über die main()-Funktion die Funktion einordnen() aufgerufen. Dieses Mal ist es aber (zeiger==NULL) falsch, denn das erste Element bzw. die Wurzel des Baums ist die Zahl 10. Die nächste else if-Bedingung:
else if(zeiger->wert >= zahl)
Das trifft zu, zeiger->wert (10) ist größer als die eingegebene Zahl. Es folgt der erste Funktionsselbstaufruf:
zeiger->links=einordnen(zeiger->links);
Jetzt soll der Zeiger zeiger, der auf links verweist, die Adresse vom erneuten Funktionsaufruf einordnen(zeiger->links) zugewiesen bekommen. Alles wieder von vorne:
if(zeiger==NULL)
Und tatsächlich zeigt der Zeiger zeiger jetzt auf NULL, da er ja zuvor durch den erneuten Aufruf die Adresse von der linken Seite des ersten Elements (10) erhalten hat. Also wird erst Speicher allokiert und dann das neue Element eingefügt. Der linke und der rechte Zeiger des neuen Elements bekommen wieder jeweils den NULL-Zeiger zugewiesen:
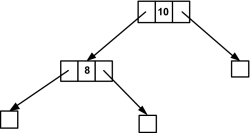
Hier klicken, um das Bild zu Vergrößern
Abbildung 24.21 Kleinere Elemente wie die Wurzel kommen auf die linke Seite
Als Nächstes sei die Zahl 9 gegeben. Im ersten Durchlauf wird
else if(zeiger->wert >= zahl) zeiger->links=einordnen(zeiger->links);
wie schon zuvor ausgeführt. Jetzt verweist der Zeiger zeiger auf die Adresse mit dem Wert 8. Also ist zeiger==NULL nicht wahr, und die Bedingung
else if(zeiger->wert >= zahl)
ist auch nicht wahr, denn zeiger->wert (8) ist dieses Mal nicht größer oder gleich der aktuellen Zahl (9). Die nächste else if-Anweisung
else if(zeiger->wert < zahl)
ist jetzt wahr, denn (8 < 9) trifft zu. Dies ist der zweite rekursive Funktionsaufruf (einer liegt ja schon auf dem Stack):
zeiger->rechts=einordnen(zeiger->rechts);
Jetzt bekommt der Zeiger zeiger, der auf rechts verweist, die Adresse von einordnen(zeiger->rechts). Das ist übrigens auch der Grund, weshalb die Funktion einen Rückgabewert vom Typ KNOTEN * hat. Auf zum erneuten Durchlauf der Funktion. zeiger==NULL trifft jetzt zu, also wurde der Platz für das neue Element gefunden:
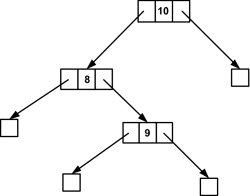
Hier klicken, um das Bild zu Vergrößern
Abbildung 24.22 Neues Element ist kleiner als die Wurzel aber größer als der Nachfolgerknoten
Als Nächstes sei die Zahl 20 gegeben. Hierzu soll eine Grafik genügen, die als Übung selbst durchgegangen werden kann:
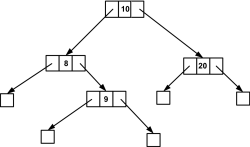
Hier klicken, um das Bild zu Vergrößern
Abbildung 24.23 Größere Elemente wie die Wurzel kommen auf die rechte Seite
Die einzelnen Knoten, die zuvor erzeugt wurden, werden nun besucht bzw. in diesem Fall ausgeben. Dies wird Traversieren der Bäume genannt. Hierzu zwei gängige Möglichkeiten, die Bäume zu traversieren. Zur Demonstration wird der eben erstellte binäre Baum verwendet.
| 1. | Die erste Variante ist die Preorder-Travesierung. Gemäß der Preorder-Travesierung wird zuerst die Wurzel mit dem Wert 10 besucht, anschließend der Knoten mit dem Wert 8. Es folgt der Knoten mit dem Wert 9. Als Letztes wird der Knoten mit dem Wert 20 besucht. Diese Preorder-Taktik läuft wie folgt ab: Besuche die Wurzel, dann besuche den linken Unterbaum, als Nächstes besuche den rechten Unterbaum. Hierzu die Funktion, die das Verfahren realisiert: |
void zeige_baum(KNOTEN *zeiger) {
if(zeiger != NULL) {
printf("\n%d->",zeiger->wert);
zeige_baum(zeiger->links);
zeige_baum(zeiger->rechts);
}
}
| 2. | Die zweite Möglichkeit ist die so genannte Inorder-Travesierung. Bei dieser Möglichkeit werden die Knoten in folgender Reihenfolge besucht |
8->9->10->20
| im Gegensatz zum Preorder | |
10->8->9->20
| Daraus lässt sich folgende Inorder-Taktik konstatieren: Besuche den linken Unterbaum, dann besuche die Wurzel und besuche zuletzt den rechten Unterbaum. Die Funktion der Inorder-Taktik sieht dann wie folgt aus: | |
void zeige_baum(KNOTEN *zeiger) {
if(zeiger != NULL) {
zeige_baum(zeiger->links);
printf("\n%d->",zeiger->wert);
zeige_baum(zeiger->rechts);
}
}
Es ist kaum eine Änderung zur Preorder-Travesierung festzustellen, nur dass bei der Inorder-Travesierung zuerst mit dem am weitesten links unten liegenden Knoten oder Blatt angefangen wird und beim Preorder mit der Wurzel.
Es gibt noch eine dritte Möglichkeit: Besuche den linken Unterbaum, besuche den rechten Unterbaum und dann besuche die Wurzel. Diese Methode benötigen Sie eigentlich nur bei Postfix-Notationen.
Jetzt folgt ein etwas komplizierteres Problem. Das Löschen eines Elements im Baum. Hierbei gibt es erneut drei Möglichkeiten:
| Die einfachste Form ist die Entfernung eines Blatts, da dieses keinen Nachfolger mehr hat. |
| Die zweite Möglichkeit ist die Entfernung eines Knotens mit nur einem Nachfolger. |
| Die letzte Möglichkeit ist gleichzeitig auch die schwierigste. Es muss ein Knoten gelöscht werden, der zwei Nachfolger hat. |
Zuerst benötigen Sie eine Funktion, die den zu löschenden Knoten sucht:
void loesche(KNOTEN **zeiger, int such) {
if((*zeiger) == NULL)
printf("Baum ist leer\n");
else if((*zeiger)->wert == such) /* Gefunden! */
loesche_knoten(zeiger);
else if((*zeiger)->wert >= such)
loesche(&((*zeiger)->links),such);
else
loesche(&((*zeiger)->rechts),such);
}
Der Funktion loesche() werden als Argumente die Wurzel (zeiger) und der zu suchende Wert (such) übergeben. Als Erstes wird überprüft, ob überhaupt eine Wurzel vorhanden ist (if((*zeiger) == NULL)). Danach wird getestet, ob der Wert schon gefunden wurde (else if((*zeiger)->wert == such)). Wurde der Wert gefunden, wird die Funktion loesche_knoten() mit dem zeiger auf den gefundenen Wert aufgerufen. Als Nächstes (falls der Knoten noch nicht gefunden wurde) wird überprüft, ob der Wert, auf den der Zeiger zeiger verweist, größer oder gleich dem gesuchten Wert such ist (else if((*zeiger)->wert >= such) ). Ist dies der Fall, ist der gesuchte Wert kleiner als der, auf den der Zeiger zeiger verweist, und muss sich somit auf der linken Seite der aktuellen Adresse zeiger befinden (loesche(&((*zeiger)> links),such)). Hier erfolgt der erste rekursive Aufruf mit dem Adressoperator. Die letzte else-Anweisung ergibt sich dadurch, dass der gesuchte Wert größer als der ist, auf den der Zeiger zeiger gerade verweist. In diesem Fall wird auf der rechten Seite mit dem rekursiven Aufruf (loesche(&((*zeiger)-> rechts),such)) weiter gesucht.
Es wird jetzt davon ausgegangen, dass der Knoten gefunden wurde, und nun wird die Funktion loesche_knoten(zeiger) aufgerufen:
void loesche_knoten(KNOTEN **zeiger) {
KNOTEN *temp;
int tempwert;
if(globale_wurzel == *zeiger) {
printf("Kann die Wurzel nicht loeschen!!\n");
return;
}
if((*zeiger)!=NULL) { /* Blatt! */
if((*zeiger)->links==NULL && (*zeiger)->rechts==NULL) {
free(*zeiger);
*zeiger=NULL;
}
else if((*zeiger)->links==NULL) {
/* Nur rechter Nachfolger */
temp = *zeiger;
*zeiger=(*zeiger)->rechts;
free(temp);
}
else if((*zeiger)->rechts==NULL) {
/* Nur linker Nachfolger */
temp = *zeiger;
*zeiger=(*zeiger)->links;
free(temp);
}
else { /* 2 Nachfolger, wir suchen Ersatzelement */
suche_ersatz(&tempwert, &((*zeiger)->rechts));
(*zeiger)->wert=tempwert;
}
}
}
Zunächst wird überprüft, ob der gefundene Wert die Wurzel ist. In diesem Fall wird kein Element gelöscht und die Funktion beendet (dazu unten mehr). Als Nächstes wird getestet, ob das zu löschende Element ein Blatt ist (ein Element ohne Nachfolger):
if((*zeiger)->links==NULL && (*zeiger)->rechts==NULL)
Falls es ein Blatt ist, wird es entfernt. Ansonsten wird mit den nächsten beiden else if-Bedingungen ermittelt, ob das zu löschende Element einen rechten oder linken Nachfolger hat. Die letzte und die schwierigste Möglichkeit ist es, wenn der zu löschende Knoten zwei Nachfolger besitzt. Dafür wird am besten eine spezielle Funktion geschrieben, die für den zu löschenden Knoten ein Ersatzelement sucht:
else { /* 2 Nachfolger, wir suchen Ersatzelement */
suche_ersatz(&tempwert, &((*zeiger)->rechts));
(*zeiger)->wert=tempwert;
}
Hier wird ein Ersatzelement auf der rechten Seite gesucht. Die Funktion suche_ersatz():
void suche_ersatz(int *neuwert, KNOTEN **zeiger) {
KNOTEN *temp;
if(*zeiger != NULL) {
if((*zeiger)->links==NULL) {
neuwert=(*zeiger)->wert;
temp=*zeiger;
*zeiger=(*zeiger)->rechts;
free(temp);
}
else
suche_ersatz(neuwert, &((*zeiger)->links));
}
}
Die Funktion suche_ersatz() läuft jetzt durch einen rekursiven Aufruf (suche_ersatz(neuwert, &((*zeiger)->links));) so lange die linke Seite des Baums hinab, bis die Bedingung (if((*zeiger)->links==NULL)) wahr ist. Dann wurde ein Ersatzelement gefunden, auf das gleich der Zeiger *neuwert verweist.
|
Tipp Zum besseren Verständnis hilft es oft, sich den Vorgang mit einer Zeichnung auf einem Blatt Papier zu vergegenwärtigen. |
Das vollständige Listing mit einigen zusätzlichen Funktionen kann unter http://www.pronix.de/ (btree2.c) bezogen werden.
Jetzt soll der binäre Suchbaum mit dem Postleitzahlen-Programm verwendet werden. Zuerst wird die grundlegende Knotenstruktur für den binären Baum festgelegt:
struct binaer_knoten{
char ort[255];
unsigned int plz;
struct binaer_knoten *links;
struct binaer_knoten *rechts;
};
Jetzt eine spezielle Struktur für den Baum:
struct binaer_baum{
struct binear_knoten *root;
unsigned int counter;
};
Dank dieser Struktur werden die rekursiven Aufrufe des vorigen Beispiels aufgehoben. Dies ist möglich, weil beim ersten Aufruf der Funktion als Argument immer die Adresse der Wurzel des Baums mit übergeben wird.
Als Nächstes benötigen Sie eine Funktion, um den binären Baum zu initialisieren:
struct binaer_baum *init(void) {
struct binaer_baum *baum =(struct binaer_baum *)
malloc(sizeof *baum);
if(baum == NULL) {
fprintf(stderr, "Speicherplatzmangel!!!\n");
return NULL;
}
else { /*Initialisieren*/
baum->root = NULL;
baum->counter=0;
return baum;
}
}
Es folgt eine Funktion zum Einfügen einzelner Knoten in den binären Baum ohne einen rekursiven Funktionsaufruf:
int einfuegen(struct binaer_baum *baum, unsigned int p, char *o){
struct binaer_knoten *knoten, **neu;
neu =(struct binaer_knoten **) &baum->root;
knoten= (struct binaer_knoten *) baum->root;
for(;;) {
if(knoten == NULL) {
/* Haben wir einen freien Platz gefunden? */
knoten = *neu =
(struct binaer_knoten *)malloc(sizeof *knoten);
if(knoten != NULL) {
/* Daten rein damit */
knoten->plz = p;
strcpy(knoten->ort, o);
knoten->links=knoten->rechts=NULL;
baum->counter++;
/* Beendet die Funktion erfolgreich */
return 1;
}
else {
fprintf(stderr, "Speicherplatzmangel\n");
return 0;
}
}
/* Ist die aktuelle Postleitzahl größer */
else if(p > knoten->plz) {
/* Dann gehts rechts weiter im Baum */
neu = &knoten->rechts;
knoten = knoten->rechts;
}
else { /* Der letzte Fall, die aktuelle PLZ ist kleiner */
/* dann eben nach links weiter im Baum */
neu = &knoten->links;
knoten = knoten->links;
}
}
}
Das Thema binäre Bäume ist erheblich einfacher, wenn die Rekursion beseitigt wird. Wichtig ist bei dieser Funktion, dass sich die Endlosschleife auch irgendwann einmal beendet. In diesem Beispiel beendet sich die Funktion bei Erfolg mit dem Rückgabewert 1 (return 1), wenn das neue Element eingefügt wurde. Bei Mangel an Speicherplatz gibt diese Funktion 0 zurück. Das Einfügen eines neuen Elements berücksichtigt übrigens keine doppelten Einträge. Dies können Sie zur Übung gern selbst nachtragen.
Jetzt soll die Suchfunktion erstellt werden (um die es ja eigentlich in diesem Kapitel geht). Es wird an der Wurzel (root) des Baums angefangen. Ist das gesuchte Element größer, geht die Suche auf der rechten Seite des Baums weiter. Ist das gesuchte Element kleiner, wird auf der linken Seite weiter gesucht. Bei einem perfekt ausgeglichenen Baum führt dies zu optimalen Ergebnissen. Hier die Suchfunktion, welche sich relativ einfach erstellen lässt:
void binaere_suche_plz(const struct binaer_baum *baum,
unsigned int p) {
const struct binaer_knoten *knoten;
/* Zuerst an die Wurzel */
knoten = (struct binaer_knoten *) baum->root;
for(;;) {
if(knoten == NULL) {
printf("Keine erfolgreiche Suche!\n");
return;
}
if(p == knoten->plz) { /* Gefunden */
printf("Ort zu Postleitzahl %d : %s\n",
p,knoten->ort);
return;
}
else if(p > knoten->plz) /* Gesuchtes Element größer */
knoten=knoten->rechts; /* Rechts am Baum weiter */
else /* Gesuchtes Element kleiner */
knoten=knoten->links; /* Links am Baum weiter */
}
}
Mit dieser Funktion haben Sie auch schon die Grundlage für das Löschen eines Elements im Baum geschaffen. Nur müssen Sie anstatt
if(p == knoten->plz) { /* Gefunden */
printf("Ort zu Postleitzahl %d : %s\n",
p,knoten->ort);
return;
}
break verwenden, um nach der for-Schleife weitere Operationen durchzuführen:
if(p == knoten->plz) /* Gefunden */ break;
Das Löschen eines Elements im binären Baum wurde ja schon einmal präsentiert. Da aber schon beim Einfügen eines Knotens auf weitere Funktionsaufrufe, insbesondere Rekursionen, verzichtet wurde, soll auch die Funktion zum Löschen eines Knotens entsprechend umgeschrieben werden, und zwar so, dass alle Operationen in dieser Funktion ausgeführt werden. Hier die Funktion:
int bin_delete(struct binaer_baum *baum, unsigned int p) {
/* pointer_z ist das zu löschende Element */
struct binaer_knoten **pointer_q, *pointer_z,
*pointer_y, *pointer_x;
pointer_q = (struct binaer_knoten **)&baum->root;
pointer_z = (struct binaer_knoten *)baum->root;
for(;;) {
if(pointer_z == NULL)
return 0;
else if(p == pointer_z->plz)
/* zu löschendes Element gefunden */
break;
else if(p > pointer_z->plz) {
/* löschende Element ist größer */
pointer_q = &pointer_z->rechts;
/* rechts weitersuchen */
pointer_z = pointer_z->rechts;
}
else { /* Löschende Element ist kleiner */
pointer_q = &pointer_z->links;
/* links weitersuchen */
pointer_z = pointer_z->links;
}
} /* Hierher kommen wir nur durch ein break */
/* Jetzt müssen wir das zu löschende Element untersuchen
* pointer_z hat rechts keinen Nachfolger, somit können wir
* es austauschen gegen den linken Nachfolger ... */
if(pointer_z->rechts == NULL)
*pointer_q = pointer_z->links;
else {
/* pointer_z hat einen rechten Nachfolger, aber
* keinen linken. */
pointer_y = pointer_z->rechts;
if(pointer_y->links == NULL) {
/* pointer_z->rechts hat keinen linken Nachfolger ... */
pointer_y->links = pointer_z->links;
*pointer_q = pointer_y;
}
else { /* es gibt einen linken Nachfolger */
pointer_x = pointer_y->links;
/* Jetzt suchen wir so lange, bis es keinen linken
* Nachfolger mehr gibt */
while(pointer_x->links != NULL) {
pointer_y = pointer_x;
pointer_x = pointer_y->links;
}
/* Jetzt haben wir alle Punkte zusammen und
* können diese verknüpfen */
pointer_y->links = pointer_x->rechts;
pointer_x->links = pointer_z->links;
pointer_x->rechts = pointer_z->rechts;
*pointer_q = pointer_x;
}
}
/* Zu guter Letzt können wir pointer_z freigeben */
baum->counter--;
free(pointer_z);
return 1;
}
Zugegeben, auf den ersten Blick dürfte diese Funktion etwas abschreckend wirken. Aber zeichnen Sie sich einen binären Baum auf ein Blatt Papier und gehen Sie dabei diese Funktion Schritt für Schritt durch: Sie werden sich wundern, wie einfach diese Funktion im Gegensatz zur rekursiven Variante ist.
Zum Schluss noch der vollständige Quellcode zu diesem Abschnitt:
/* btree3.c */
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAX 255
struct binaer_knoten{
char ort[MAX];
unsigned int plz;
struct binaer_knoten *links;
struct binaer_knoten *rechts;
};
struct binaer_baum{
struct binear_knoten *root;
unsigned int counter;
};
struct binaer_baum *init(void) {
struct binaer_baum *baum =(struct binaer_baum *)
malloc(sizeof *baum);
if(baum == NULL) {
fprintf(stderr, "Speicherplatzmangel!!!\n");
return NULL;
}
else { /*Initialisieren*/
baum->root = NULL;
baum->counter=0;
return baum;
}
}
int einfuegen(struct binaer_baum *baum, unsigned int p, char *o){
struct binaer_knoten *knoten, **neu;
neu =(struct binaer_knoten **) &baum->root;
knoten= (struct binaer_knoten *) baum->root;
for(;;) {
if(knoten == NULL) {
/* Haben wir einen freien Platz gefunden? */
knoten = *neu =
(struct binaer_knoten *)malloc(sizeof *knoten);
if(knoten != NULL) {
/* Daten rein damit */
knoten->plz = p;
strcpy(knoten->ort, o);
knoten->links=knoten->rechts=NULL;
baum->counter++;
/* Beendet die Funktion erfolgreich */
return 1;
}
else {
fprintf(stderr, "Speicherplatzmangel\n");
return 0;
}
}
/* Ist die aktuelle Postleitzahl größer? */
else if(p > knoten->plz) {
/* Dann gehts rechts weiter im Baum */
neu = &knoten->rechts;
knoten = knoten->rechts;
}
else { /* Der letzte Fall, die aktuelle PLZ ist kleiner */
/* dann eben nach links weiter im Baum */
neu = &knoten->links;
knoten = knoten->links;
}
}
}
void binaere_suche_plz(const struct binaer_baum *baum,
unsigned int p) {
const struct binaer_knoten *knoten;
/* Zuerst an die Wurzel */
knoten = (struct binaer_knoten *) baum->root;
for(;;) {
if(knoten == NULL) {
printf("Keine erfolgreiche Suche!\n");
return;
}
if(p == knoten->plz) { /* Gefunden */
printf("Ort zu Postleitzahl %d : %s\n",
p,knoten->ort);
return;
}
else if(p > knoten->plz) /* Gesuchtes Element größer */
knoten=knoten->rechts; /* Rechts am Baum weiter */
else /* Gesuchtes Element kleiner */
knoten=knoten->links; /* Links am Baum weiter */
}
}
int bin_delete(struct binaer_baum *baum, unsigned int p) {
/* pointer_z ist das zu löschende Element */
struct binaer_knoten **pointer_q, *pointer_z,
*pointer_y, *pointer_x;
pointer_q = (struct binaer_knoten **)&baum->root;
pointer_z = (struct binaer_knoten *)baum->root;
for(;;) {
if(pointer_z == NULL)
return 0;
else if(p == pointer_z->plz)
/* zu löschendes Element gefunden */
break;
else if(p > pointer_z->plz) {
/* löschende Element ist größer */
pointer_q = &pointer_z->rechts;
/* rechts weitersuchen */
pointer_z = pointer_z->rechts;
}
else { /* Löschende Element ist kleiner */
pointer_q = &pointer_z->links;
/* links weitersuchen */
pointer_z = pointer_z->links;
}
} /* Hierher kommen wir nur durch ein break */
/* Jetzt müssen wir das zu löschende Element untersuchen
* pointer_z hat rechts keinen Nachfolger, somit können wir
* es austauschen gegen den linken Nachfolger ... */
if(pointer_z->rechts == NULL)
*pointer_q = pointer_z->links;
else {
/* pointer_z hat einen rechten Nachfolger, aber
* keinen linken. */
pointer_y = pointer_z->rechts;
if(pointer_y->links == NULL) {
/* pointer_z->rechts hat keinen linken Nachfolger ... */
pointer_y->links = pointer_z->links;
*pointer_q = pointer_y;
}
else { /* es gibt einen linken Nachfolger */
pointer_x = pointer_y->links;
/* Jetzt suchen wir so lange, bis es keinen linken
* Nachfolger mehr gibt */
while(pointer_x->links != NULL) {
pointer_y = pointer_x;
pointer_x = pointer_y->links;
}
/* Jetzt haben wir alle Punkte zusammen und
* können diese verknüpfen */
pointer_y->links = pointer_x->rechts;
pointer_x->links = pointer_z->links;
pointer_x->rechts = pointer_z->rechts;
*pointer_q = pointer_x;
}
}
/* Zu guter Letzt können wir pointer_z freigeben */
baum->counter--;
free(pointer_z);
return 1;
}
int main(void) {
struct binaer_baum *re;
char o[MAX];
unsigned int p;
int wahl, r;
re = init();
if(re == NULL) {
printf("Konnte keinen neuen binären Baum erzeugen!\n");
return EXIT_FAILURE;
}
else
printf("Binärbaum wurde erfolgreich Initialisiert\n");
do {
printf("\n-1- Neue PLZ hinzufügen\n");
printf("-2- PLZ suchen\n");
printf("-3- PLZ löschen\n");
printf("-4- Ende\n\n");
printf("Ihre Wahl : ");
scanf("%d",&wahl);
if(wahl == 1) {
printf("Bitte geben Sie eine neue PLZ ein : ");
do{ scanf("%5d",&p); }while( (getchar()) != '\n' );
printf("Der Ort dazu : ");
fgets(o, MAX, stdin);
r=einfuegen(re, p, strtok(o, "\n") );
if(r == 0)
return EXIT_FAILURE;
}
else if(wahl == 2) {
printf("Für welche PLZ suchen Sie einen Ort : ");
scanf("%5d",&p);
binaere_suche_plz(re, p);
}
else if(wahl == 3) {
printf("Welche PLZ wollen Sie löschen : ");
scanf("%5d",&p);
bin_delete(re, p);
}
} while(wahl != 4);
return EXIT_SUCCESS;
}
Es gibt noch mehrere andere Wege, binäre Bäume zu implementieren, um sich z.B. das Travesieren des Baums zu erleichtern. Bereits gesehen haben Sie das Durchlaufen der Bäume mittels Preorder- und Inorder-Travesierung. Wenn Sie aber das Durchlaufen (Travesieren) eines Baums iterativ und nicht mehr rekursiv vornehmen wollen, können Sie die Struktur um einen Zeiger zum Elternknoten erweitern:
struct binaer_knoten{
char ort[255];
unsigned int plz;
struct binaer_knoten *links;
struct binaer_knoten *rechts;
struct binaer_knoten *eltern;
};
Jetzt kann jeder Knoten sein Umfeld kontrollieren. Dieser Eltern-Zeiger vereinfacht das Travesieren des Baums, doch der Schreibaufwand für das Programm steigt. Außerdem wird auch das Einfügen und Löschen eines Elements verlangsamt, da ein Zeiger mehr verwaltet werden muss. Dem Eltern-Zeiger der Wurzel übergeben Sie hingegen den NULL-Zeiger.
Mit Threads (threading) haben Sie die Möglichkeit, einen Baum noch schneller zu travesieren. Denn anstatt zu überprüfen, ob der linke oder rechte Teil eines Knotens leer (NULL) ist, was zu einer schlechteren Laufzeit führen könnte, müssen Sie nur zwei Extra-Bits (Bit-Felder) in die Struktur einfügen:
struct binaer_knoten{
char ort[255];
unsigned int plz;
struct binaer_knoten *links;
struct binaer_knoten *rechts;
unsigned linker_thread:1;
unsigned rechter_thread:1;
};
Wenn sich z.B. auf der linken Seite eines Knotens ein weiterer Knoten befindet, steht das Bit linker_tread auf 1, falls sich dort noch kein Knoten befindet, auf 0. Natürlich lässt sich auf diese Weise nicht generell eine bessere Laufzeit garantieren, da diese davon abhängt, wie der Compiler Bit-Felder optimiert. Aber eine Erleichterung dürfte es auf jeden Fall darstellen.
Es gibt leider einen negativen Aspekt bei den eben kennen gelernten binären Bäumen. Betrachten Sie bitte folgenden Binärbaum:
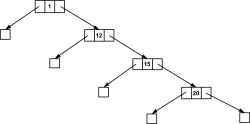
Hier klicken, um das Bild zu Vergrößern
Abbildung 24.24 Entarteter Binärbaum
Bei diesem Beispiel handelt es sich tatsächlich um einen binären Baum, nicht wie Sie vielleicht vermuten würden, um einen verkettete Liste. Der Baum hat die Tiefe 4 und könnte normalerweise 15 Elemente aufnehmen (241). Es handelt sich dabei um einen entarteten Baum. So etwas kann passieren, wenn ein relativ kleiner oder großer Wert als Wurzel des Baums verwendet wird. Zugegeben, dieses Beispiel ist ein ungünstiger Fall, aber es könnte dazu kommen.
Es gibt, um entartete Binärbäume auszugleichen, Algorithmen, die allerdings nicht einfach zu verstehen sind. Aber was heißt perfekt ausbalanciert (ausgeglichen) im Sinne von Binärbäumen? Ein Binärbaum ist perfekt ausgeglichen, wenn sich die Höhen (oder auch Tiefen) der linken und rechten Teilbäume höchstens um den Wert 1 unterscheiden. Solche Bäume werden AVL-Bäume genannt.
Um also Probleme zu vermeiden, müssen Sie den Baum immer ausgeglichen halten. Dies ist allerdings auch mit einem erhöhten Speicheraufwand verbunden. Denn wenn ein neues Element eingefügt oder ein Element gelöscht wird, kann es sein, dass der komplette Baum wieder neu organisiert werden muss. Diesen Aufwand sollten Sie jedoch nur betreiben, wenn es denn tatsächlich auf ein schnelleres Suchergebnis ankommt. Ein solches schnelleres Suchergebnis wird durch die Verkürzung der Pfadlänge erreicht.
Zu diesem Thema könnte man ganze Bücher schreiben. Einige weiterführende Hinweise sollen zu den binären Bäumen dennoch gegeben werden. Zudem habe ich Ihnen im Anhang weiterführende Links und empfehlenswerte Literatur zusammengestellt.
Ein AVL-Baum ist ein Suchbaum, dessen Knoten sich in der Höhe (Tiefe) von derjenigen der Teilbäume um höchstens 1 unterscheidet, also ein perfekt ausbalancierter Baum. Wird diese Bedingung verletzt, muss eine Ausgleichsfunktion ausgeführt werden. Folgende drei Bedingungen können dabei auftreten (auch Balance-Grad genannt):
| balance > 0 Der rechte Teilbaum besitzt eine größere Höhe als der linke. |
| balance < 0 Der linke Teilbaum besitzt eine größere Höhe als der rechte. |
| balance = 0 Teilbäume haben die gleiche Höhe und sind optimal ausbalanciert. Dieser Zustand wird angestrebt. |
Um gegen diese Verletzung vorzugehen, werden so genannte Rotationen vorgenommen. Dabei gilt es zwischen rechtsseitiger Rotation (betrifft die rechte Seite des Teilbaums eines Knotens) und linksseitiger Rotation (betrifft die linke Seite des Teilbaums eines Knotens) zu unterscheiden. Außerdem gibt es noch einfache und doppelte Rotationen. Dass all diese Operationen sehr rechenintensiv sind, lässt sich wohl leicht erschließen.
Wenn Sie sich für die Programmierung einer eigenen Datenbank interessieren, dann sollten Sie sich mit diesem Baum befassen. Der B-Baum wird durch eine variable Anzahl von Elementen (Blättern) pro Knoten an die Blockgröße des Dateisystems angepasst. Dadurch ist eine effektive und optimale Geschwindigkeitsausnutzung auf verschiedenen Systemen möglich. Die einzelnen Knoten eines B-Baums sind nicht immer belegt und variieren zwischen dem Kleinst- und Höchstwert. Somit ist immer Platz für Änderungen von Strukturen bei Manipulationen (Einfügen, Löschen, Ändern ) an der Datenbank vorhanden.
Dies waren lange noch nicht alle Algorithmen, mit denen Sie ausgeglichene Bäume erstellen können. Zu erwähnen sind hier noch die Top-Down-234-Bäume und die Rot-Schwarz-Bäume.
| << zurück |
|
||||||||||||||
|
||||||||||||||
|
||||||||||||||
|
||||||||||||||
Copyright © Galileo Press 2006
Für Ihren privaten Gebrauch dürfen Sie die Online-Version natürlich ausdrucken. Ansonsten unterliegt das <openbook> denselben Bestimmungen, wie die gebundene Ausgabe: Das Werk einschließlich aller seiner Teile ist urheberrechtlich geschützt. Alle Rechte vorbehalten einschließlich der Vervielfältigung, Übersetzung, Mikroverfilmung sowie Einspeicherung und Verarbeitung in elektronischen Systemen.



 bestellen
bestellen




