 
|
|
|
Volume I:Issue II, Spring 2006 Published: April 1, 2006 In This Issue: From the Editor: New Print Edition Available! Developing For Fun With OS/2 And OpenWatcom --Axel Meiss Surfing In The Colorful Chinese World With OS/2 And eComStation --Chen Biao USB Thumb Drives And Flash Wristbands With eComStation --Tom Mullins Power Tips Gallery-Desktop Backgrounds Want to write for OS2eCS eZine-Learn how! |

 
|
|
Developing For Fun With OS/2 And OpenWatcom -By Axel Meiss For more than a decade I have been
using OS/2 now. I got used to it
when I had to use OS/2 2.1 when I got employed in my first IT-company
who chose OS/2 as their platform to develop software for warehouse
systems. Back then, we used the 16-bit compilers MS C 6.0 and MS Cobol
4.5. (yes, I really did Cobol, and it's not as bad as its reputation).
Having used only the Atari ST and MS-DOS 5, I was quite impressed
about a real multitasking system with a nice GUI. But, I was also
impressed by the possibility of having multiple character mode
applications in multiple windows. I wasn't used to character mode
applications because the Atari ST didn't provide that, and DOS only
allowed me to run it all full-screen. Though I had an Unix machine
available, I didn't like the terminal access with that machine. OS/2
was much more convenient. I upgraded my machine at home with additional
4 MB of RAM, so I could run OS/2 2.0 (a copy which I had bought
inexpensively before) at home with 5 MB.
Commercial compilers were expensive
then ($400+), so I was glad that
there was a free compiler available, the EMX-port (by Eberhard Mattes)
of the GNU compiler. I didn't develop
much at home because I was
already developing in the company. But, it helped me a lot to explore
OS/2. Later, I purchased a copy of Watcom C/C++ 10.0, my first
commercial compiler because they gave it away for only $200 or so. I
liked the idea of a multi-platform compiler which supported OS/2, DOS,
Windows and even Novell. In the company, we were evaluating VisualAge
C++ 3.0 for OS/2 which was quite clumsy, compared to the Watcom
compiler. I was quite annoyed by the fact that VisualAge C++
didn't use the standard LINK386 because it took me some time to
understand it and the new linker also created Extended Attributes for
my executables which I didn't like.
But, I got used to it... Dynamic Linking One of the interesting new things
then was the concept of
Dynamic-Link-Libraries(DLL). First regarded as a totally cool way of
creating applications it has become a source of potential trouble,
especially in the way of different versions of a DLL. This problem is
known under Windows as the "DLL-Chaos". Some programs require a
specific version of a DLL and will not run with an earlier version. If
now a program ships with the older version the installation may replace
the newer DLL with the older one. It can be very hard to keep
track which is
the most recent version of the DLL. OS/2 is by no means immune to the
DLL-Chaos, so a lot of care must be taken when DLLs should be shipped
with an application. When creating DLLs one also should watch the
naming of a DLL. Actually, under OS/2 a DLL name it is advised to be
unique,
i.e. you should not have two different DLLs which are named both
"SOMEDLL.DLL" which are located in different directories. Whenever one
of those DLLs is loaded by an application, an application that requires
the other DLL may not run properly because it refers to the DLL loaded
earlier. You can avoid this problem by explicitely loading a DLL with
fully qualified file name (like C:\SPECIAL\SOMEDLL.DLL). But this
requires that the calling application "knows" where the DLL is
located.
Reportedly, you can also force an explicit load of some version of a
DLL in command line sessions with SET LIBPATHSTRICT=T even if some
other version of the same DLL is already loaded(which was introduced
with some later kernel of Convenience Package 1 or so) . It seems to me
though that this was included for testing DLLs purpose only.
Just giving a short summary what
has been explained in many articles about OS/2 before: Usually, a DLL is placed in some directory listed in the LIBPATH-statement of CONFIG.SYS. The naming problem was even a little aggravated with OS/2 Warp 3 when DLL file names were restricted to follow the 8.3-file-naming convention to allow the DLL to reside on a FAT-formatted volume. Though the namespace for a DLL is quite large (> 36^8) it's very easy to create conflicting DLL names when there should be "speaking" names like "FILEIO.DLL" or "HELPER.DLL" instead of "CY100A9L.DLL". Of course, one of the solutions is to avoid DLLs at all. Very often, this is the best solution. Sometimes though, it is sensible to create and use DLLs, especially if those DLLs provide additional functionality. Take Impos/2 e.g. which uses a separate DLL for each graphics format. In case there are new file formats, only a new DLL is needed while the main application doesn't have to change. As for me, I have come to the opinion that not putting much functionality into a single DLL is the best way when creating DLLs because the more code a DLL contains the more errors are likely to exist and the more often a new version of a DLL may be needed. OS/2 has two ways of handling DLLs: Load-Time Linking and and Run-Time Linking Load-Time Linking means the DLL is
needed when a program starts,
otherwise the program doesn't start at all and the error SYS1804 is
produced. This happens when you have installed Mozilla 1.7 without
having the
LIBC0x.DLL somewhere in a directory which is listed in your LIBPATH.
Run-Time Linking means the program starts, then the DLL is loaded by the program "manually" requiring handling by the program. Obviously, the latter method is more flexible and is widely used by key applications like web browser Mozilla. Even the Cobol environment I used at work took advantage of Run-Time Linking. Why OS/2 ? When telling people that I use
eComStation I usually get asked "What is
that ?". When I tell them it's a system based on OS/2 people
start staring at me. I frankly mention that I was tired of all the
security updates to Windows NT 4.0 which I used for internet access
until three years ago. Of course, I had still a box with OS/2 Warp 3
Connect
installed at home. I decided to purchase a copy of eComStation 1.0,
mainly to run Mozilla. Though I had a package of Warp 4 at home I never
installed it for production because I was still satisfied with Warp 3.
Getting eComStation was a smart decision and I later ordered version
1.1 as an upgrade to my Warp 4 package. Other people who are known to
OS/2 asked me why I
chose that platform for development. They remark that Linux offers much
more software. In fact, that is correct. Yet, there is much more to do
for
OS/2.
However, you are still at risk to develop and publish something that's not needed anymore because it's already there. This goes especially for easy tasks and small programs like utilities. There are only few reasons to publish something which is already covered by some other program, e.g.
Actually, with OS/2 there are too many tasks that a developer can
choose from. But most of those tasks are very complex and require
a lot of effort to implement them. The program I explain here is very
small and hardly worth mentioning unless for demonstrating some
programming technique. As far as larger
projects are concerned, I strongly support the idea of the bounties
at OS/2 World.com
where users are encouraged to donate for potential projects. In the
past, I have purchased a sponsor unit for Netlabs to support the great work
that is done there. I plan to purchase some more.
Why OpenWatcom ? Back in 2003, OpenWatcom 1.0
became available and being a long-term
user of Watcom C/C++, I ordered the media quite soon to support the
project. It didn't really change in handling from previous versions, so
I knew instantly how to operate the IDE. I was quite pleased by that.
That is the main reason why I use it. Being the only Open Source
compiler for OS/2 besides GCC, it deserves continuous usage by
developers. Though OpenWatcom is available for free download, I
encourage all users interested in development to order the OpenWatcom
CD. As far as I know, OpenWatcom is the only supported C++
compiler left
that creates 16-bit executables both for DOS and OS/2. VisualAge C++
3.0 for OS/2 is not supported anymore yet it is still
very common though. That's one of the reasons why I used it for
compiling MD5SUML though
subsequents projects were created with OpenWatcom. We mustn't forget
though that many larger projects have become possible only be the
availability of the GNU C++ Compiler.
MD5SUML MD5SUML
was a test project to see how those file APIs introduced with
Warp Server for e-Business worked which made it possible to create and
access files with a size over 2 Gigabytes. It was also tested how
to compile a program without 64-bit integer support of the
compiler (VisualAge C++ 3.0) and without the Warp 4.5 toolkit
available. Interestingly, by then
(February 2004) at Hobbes there
was no message digest program available
for handling large files. I was quite puzzled by that. Following the
rule of overcoming a severe
limitation of the existing solution, I uploaded the whole stuff to
Hobbes
as it would be valuable to someone though MD5SUML has only a very
limited functionality, i.e., calculating a large file's MD5 sum.
The program itself was yet another implementation of Ron Rivest's reference code of MD5 in RFC1321. The Message Digest 5 is a cryptographic hash algorithm which allows files to be verified against tampering. Usually, it is used as a one-way hash to encrypt passwords. It is encryption because the password cannot be reconstructed from its MD5 sum. This feature of cryptographic hashes is the "one-way function". To verify a password, the MD5 sum of the password is calculated and is then compared to the MD5 sum of that user's password. If they compare equal the password is accepted. So, on the authorization side, no user passwords are stored but only their MD5 sums. However, it may be that different passwords produce the same MD5. That is called a "collision". A strong message digest requires that collisions cannot be produced except by brute force. To verify files against accidental change the good old Cyclic-Redundancy-Check is usually preferred. Open Source! Of course, I uploaded the source, too so anybody with experience could modify the program to fit his own needs. But there is a more serious reason
for uploading the source, too:
By providing the source, you enable others to validate that the code is free from "hidden" features. The user doesn't have to trust you anymore, he can see for himself if the code only does what it is supposed to do. Obviously, it can be embarrassing to publish poor code. But it's better to include the source even if you are not sure about your code. The successor to MD5SUML In
2004, there were reports that collisions could be found with
MD5
sums more easily than probability would expect. A collision means
finding two files which produce the same MD5 sum. Though it doesn't
affect file integrity I began to check for other message digests. I
encountered the Java program JACKSUM (www.jonelo.de).
I was quite
impressed by the number of different message digests it can calculate.
To my surprise, I didn't find any standalone program for OS/2 that
calculates an SHA-1 checksum. I realized that a native implementation
of SHA-1 would be a significant
enhancement to MD5SUML. Of course, extending MD5SUML by SHA-1
leads to the question why only SHA-1 ? What about other message digests
and how should it be handled then ?
A new executable like CHCKSUML.EXE each time a new message digest is implemented thus creating versions from 1.0 to 19.0? Creating different programs like MD5SUML.EXE for MD5, SHA1SUML.EXE for SHA-1 etc ? It was clear that OS/2 offered something much better. As I mentioned earlier, OS/2 offers the concept of Dynamic Linking. So, the better solution was to create a different DLL for each of the different message digests being processed by a frame program. It became quite obvious that Load-Time Linking was not appropriate. Load-Time Linking requires that all needed DLLs are present at program startup. So, each time a new message digest is implemented it requires the original application to be linked again. That is what you need an Import Library or a DEF-file for. It's actually as good as creating a new executable program when a new message digest should be implemented. But with Run-Time Linking you don't have to run the linker again. The main application stays the same while new DLLs can be added. Of course, you have another problem then: can all the message digest functions be called the same way ? After investigating, I came to the conclusion that that should be possible. Each message digest DLL has then the following functions:
Those functions above will be
exported functions of the DLL. You can
either create a DEF-file or you tell the linker to export those
functions. With MD5SUML I have created a Module Definition file
(MD5SUML.DEF) which tells the linker where to resolve the API-function
DosOpenL. With OpenWatcom I chose the latter option.
The new program MD5SUML could only be used by Warp 4
users who had at least Fixpak 13 installed. That was ok because the
others could still use MD5.EXE (md5_os2.zip).
As I didn't find a program for calculating SHA-1 sums I considered it a
must not to
exclude Warp 3 users from usage. I later found that there was a REXX
script which calculates SHA-1 (Daniel Hellerstein's rexx_md5.zip)
but the information about SHA-1 was really hidden there. Though Warp 3
users are not
able to check large files they can, with the new program , calculate
different
checksums, too. It would have been a pity if the message digest program
was only available to those who used the Warp 4.5 kernel. I apologize
for not creating 16-bit executables which are needed for OS/2 1.3
users. The easiest
way to support both Warp 3 and Warp 4.5 was to create two different
programs which only have
different file access routines. Of course, they use the same
message digest DLLs. It gave me a minute of trouble finding the
name for the frame
program but DIGEST
was a proper name. So, as there should be two
different programs, I chose
DIGEST.EXE - for Warp 3 and Warp4 before Fixpak 13 DIGESTL.EXE - for Warp 4 with Fixpak 13, Warp 4 Convenience Package and eComStation As a matter of course, DIGEST.EXE can be run by eComStation and Warp CP, too. DIGESTL.EXE is mainly an adoption of what was developed in MD5SUML with the message digest calculation being done outside the EXE in the DLL part. Usage of DIGEST The program is run on command line like [c:\]digestl case <method> <file name> <file name> is a normal file or '-' when input is taken from STDIN <method> is the name of the message digest algorithm [case] is optional and will produce the message digest in lower case letters The key enhancement is supplied by
mandatory parameter <method>
which says which DLL is used. DIGESTL will prefix that parameter with a
'D' and will then try to load the corresponding DLL according to the
LIBPATH statement in CONFIG.SYS, e.g. "sum64" as <method> becomes
DSUM64.DLL.
I chose composing the DLL name that
way because it might be that
someone else ships some DLL some time whose name is
MD5.DLL. Later I found that there is already an MD5.DLL as part
of the MIT/GNU Scheme package.
Nevertheless it is only a weak protection against duplicate DLL names but for easy handling of the program I didn't dare to use cryptic names like CY100A9L.DLL . On my system I have put the method-DLLs into C:\OS2\APPS\DLL which is included in the LIBPATH-statement of CONFIG.SYS by default. Last year, I was written to by a user
who needed to check his
DVD-images.
The tool he used could write the content of the image to STDOUT so he asked me if MD5SUML could take input from STDIN. Though MD5SUML can do so it produces wrong results. I created the custom program MD5STDIN for him which allowed him to check the stream from STDIN. When he asked me if I could publish MD5STDIN I told him that I would include that feature with DIGEST because DIGEST is the more flexible program. So, if you need to check STDIN stream you simply use the dash (-) as a file name. It may be of interest that DIGEST.EXE which doesn't support large files can check large files though when redirecting a large file to STDIN. I was also asked why both MD5SUML and
DIGEST produce output in
upper case. It has been a tradition that hexadecimal numbers are
printed in capitals to stress that those are numbers and not regular
texts.
babe2feed may more easily be taken for a phrase than BABE2FEED However, I have added the option to print the message digest in lower case by the optional first parameter "case" because it was requested. I dropped the optional formatting of the output as it is in MD5SUML (1234-5678-...) because it didn't seem to be used at all. Now, it may be remarked that this
program should have been one that
makes use of the GUI. This is seriously considerable. As I wanted a
command line program it would have been needed to create an extra
project, let's call it PMDIGEST. Displaying the result while not
extending the functionality would look like this:
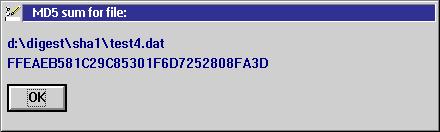 This is not what I consider well
done. So, it's better to stick with
the command line program only. Of course, there is a PM program
available for calculating MD5 sums: SigmaMD5
by Keith Merrington
Back in July last year, when SigmaMD5 was first uploaded to Hobbes I contacted the author saying it may be sensible that he did the PM version while taking advantage of the sample source concerning large file support provided with DIGEST. Unfortunately, the program doesn't come with source, so I don't know if he did. The nice thing about SigmaMD5 is that it loads the DLL for handling large files according to the version of OS/2. Nevertheless, SigmaMD5 has a different objective than DIGEST. Its main purpose is comparing two directories or drives like Roman Stangl's XCOMP2 while DIGEST is more or less sample code doing something useful. Let's make it Now, we have come to the section
where it is shown how to create a
simple message digest DLL. I have chosen an algorithm that simply adds
all the bytes of a file and produces the sum of it as a 64-bit value.
OpenWatcom supports the use of 64-bit integers unlike VisualAge C++
3.0.
It is required that OpenWatcom has been installed on the system. For
good reason, I have not included the source in the DIGEST package
because I want the user to really compile the source himself. The
following C source code must be put into a file named SUM64.C by copy
& paste. It is preferred to create a directory E:\SUM64 where
SUM64.C can be saved and which will serve as project directory.
/* SUM64.C -- snip start */ /* SUM64.C Copyright (c) 2006 Axel Meiss */ /* may be distributed freely as long as copyright notice is preserved */ #include <stdio.h> #include <string.h> #include <stdlib.h> unsigned long long sum64; /* OpenWatcom has 64-bit integers */ int DIGESTINIT(void) { sum64 = 0; /* the sum is initialized to zero */ return 0; } int DIGESTUPDATE(unsigned char *buffer, unsigned long ulSize) { unsigned long ulIndex; for(ulIndex = 0;ulIndex < ulSize;++ulIndex) sum64 += buffer[ulIndex]; return 0; } int DIGESTRESULT(unsigned char *output) { int len; int longlen; int shiftsize; unsigned char *buffer = output; unsigned int iValue; char digits[16] = {'0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F' }; longlen = sizeof(sum64) - 1; for(len = 0;len <= longlen;len++) { shiftsize = (longlen - len) * 8; iValue = (sum64 >> shiftsize) & 0xff; *buffer++ = digits[iValue >> 4]; *buffer++ = digits[iValue & 0xf]; } *buffer = '\0'; return 0; } /* SUM64.C -- snip end -- */ Now, that the source has been saved
to SUM64.C we can run the
OpenWatcom IDE by opening the OpenWatcom folder and run
OpenWatcom-Prompt and type "start ide". We create a "New project". The
following window will appear. The user may excuse that the German
version of the File Selector box is shown
 Set the target to OS/2 DLL 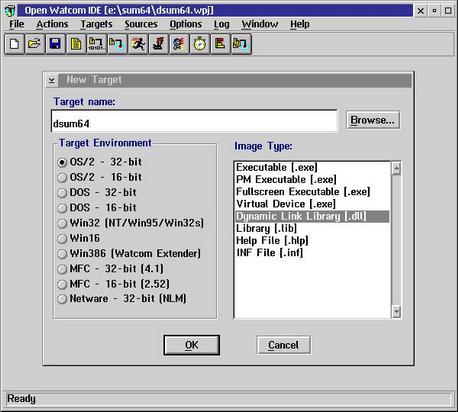 You see the name of the target is DSUM64 which will name the DLL DSUM64.DLL Then, the source files must be inserted. Use key "Insert" and type in SUM64.C  After that we must check Compiler options and go to 10. Memory Model It's essential to use Stack based calling 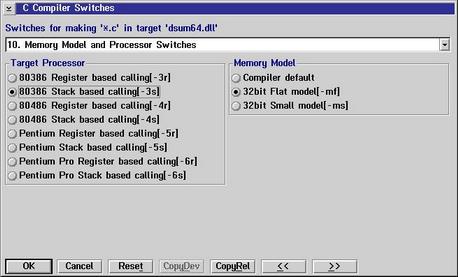 Then the Linker options must be set Here, the stack size must be set to zero. 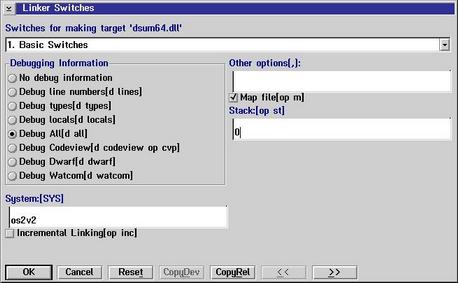 Then we must export our DLL functions DIGESTINIT DIGESTUPDATE DIGESTRESULT 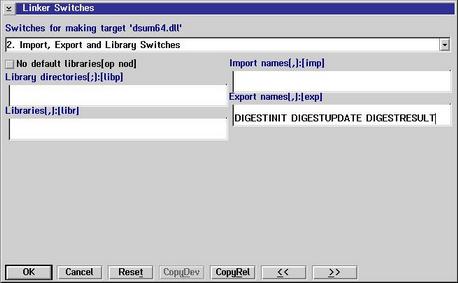 Then we must make sure that DGROUP is set to non-shared This is important because it allows the DLL to be used by different processes without using the same data of the DLL 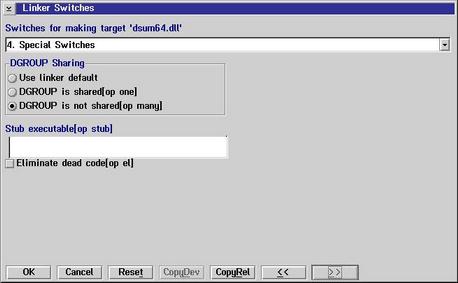 After we have done that all we press
function key F5 and let OpenWatcom
do all the processing.
Now, if everything went fine, we have DSUM64.DLL which we test by issuing the command [e:\sum64]digest sum64 sum64.c I may be asked why I chose a
hexadecimal string as output instead of
binary data. The reason is that different message digests have
different sizes. SUM64 has 64-bit size, MD5 has 128-bit size and SHA-1
has 160-bit size. Strings in C are limited by the NUL-character so its
length is calculated by regular string functions. Otherwise, I would
have to provide some length information somewhere. This way, the
calling application doesn't have to know about the size of the message
digest as long as the output buffer is large enough to hold the string
with terminating NUL-character.
Using DIGEST in REXX scripts Sometimes, it can be useful to create
the checksums of a whole list of
files.
When I created a REXX script to produce those checksums I found both in MD5SUML and DIGEST the serious flaw that a non-zero return code is not supplied when DIGEST tries to open an inaccessible file. This error has been corrected for DIGEST with the actual version. The following REXX script lists all files of a directory and its subdirectories and their respective 64-bit sums: /* files digest */ call RxFuncAdd 'SysLoadFuncs', 'RexxUtil', 'SysLoadFuncs' call SysLoadFuncs parse arg filenames say filenames if filenames == "" then filenames = "*" call SysFileTree filenames, 'files', 'FOS' do i = 1 to files.0 fname = '"'files.i'"' digestl sum64 fname ">> list.s64" if rc <> 0 then do zeile = 'Error' rc fname commando = "@echo " zeile " >> list.s64" commando end end Using such REXX script can be handy when you have only a command line available and want to create a list of files with their checksums. Things to do When you check the JACKSUM homepage
you find that there are a lot of
different message digests that are included with JACKSUM. DIGEST only
ships with two (MD5 and SHA-1). It is a task then to implement
some of the remaining message digests like RIPEMD-160 which I plan to
do soon. Though there are enough programs for calculating CRCs at
Hobbes (Radim Kolar's crc.zip
e.g.) CRC should be implemented, too. Another task may be the
creation of a REXX callable DLL like
RXDIGEST.DLL.
Acknowledgements Johann Nepomuk Ingo Steiner Jeramie Samphere (c) 2006 by Axel Meiss Axel Meiss is a long time user of OS/2 since OS/2 v2.1. He serves as Vice-President and Director at the OS2eCS Organization.  | |