Kapitel
11 Datenstrukturen und Algorithmen
Einen Rat befolgen heißt,
die Verantwortung verschieben.
Urzidil
Algorithmen1
sind ein zentrales Thema der Informatik. Ihre Erforschung und Untersuchung nimmt dort einen bedeutenden Platz ein. Algorithmen operieren nur dann effektiv mit Daten, wenn diese geeignet strukturiert sind. Schon das Beispiel Telefonbuch zeigt, wie wichtig die Ordnung der Daten nach einem Schema ist. Die Suche nach einer Telefonnummer bei gegebenem Namen gelingt schnell, jedoch ist die Suche nach einem Namen bei bekannter Telefonnummer ein mühseliges Unterfangen. Datenstrukturen und Algorithmen sind also eng miteinander verbunden, und die Wahl der richtigen Datenstruktur entscheidet über effiziente Laufzeiten; beide erfüllen alleine nie ihren Zweck. Leider ist die Wahl der »richtigen« Datenstruktur nicht so einfach, wie es sich anhört, und eine Reihe von schwierigen Problemen in der Informatik sind wohl noch nicht gelöst, da eine passende Datenorganisation bis jetzt nicht gefunden wurde.
Die wichtigsten Datenstrukturen wie Listen, Mengen und Assoziativspeicher sollen in diesem Kapitel vorgestellt werden. In der zweiten Hälfte des Kapitels wollen wir uns dann stärker den Algorithmen widmen, die auf diesen Datenstrukturen operieren.
11.1 Mit einem Iterator durch die Daten wandern
Wir wollen bei den Datenstrukturen eine Möglichkeit kennen lernen, wie sich die gespeicherten Daten unabhängig von der Implementierung immer mit derselben Technik abfragen lassen. Bei den Datenstrukturen handelt es sich meistens um Daten in Arrays, Bäumen oder Ähnlichem. Oft wird nur die Frage nach der Zugehörigkeit eines Werts zum Datenbestand gestellt, also: »Gehört das Wort dazu?«. Dieses Wortproblem ist durchaus wichtig, aber die Möglichkeit, die Daten in irgendeiner Weise aufzuzählen, ist nicht minder bedeutend. Bei Arrays können wir über den Index auf die Elemente zuzugreifen. Da wir jedoch nicht immer ein Array als Datenspeicher haben und uns auch die objektorientierte Programmierung verbietet, hinter die Kulisse zu sehen, benötigen wir möglichst einen allgemeineren Weg. Hier bieten sich Enumeratoren beziehungsweise Iteratoren an.
11.1.1 Die Schnittstellen Enumeration und Iterator
Für Iteratoren definiert die Java-Bibliothek zwei unterschiedliche Schnittstellen. Das hat historische Gründe. Die Schnittstelle Enumeration gibt es seit den ersten Java-Tagen; die Schnittstelle Iterator gibt es seit Java 1.2.
Die Schnittstelle Enumeration
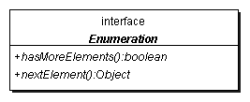
Enumeration schreibt zwei Funktionen hasMoreElements() und nextElement() vor, mit denen durch einen Datengeber (in der Regel eine Datenstruktur) iteriert werden kann wir sprechen in diesem Fall auch von einem Iterator. Bei jedem Aufruf von nextElement() erhalten wir ein weiteres Element der Datenstruktur. Im Gegensatz zum Index eines Felds können wir ein Objekt nicht noch einmal auslesen, nicht vorlaufen beziehungsweise hin und her springen. Ein Iterator gleicht anschaulich einem Datenstrom; wollten wir ein Element zweimal besuchen, zum Beispiel von rechts nach links noch einmal durchwandern, dann müssen wir wieder ein neues Enumeration-Objekt erzeugen oder uns die Elemente zwischendurch merken.
Hier klicken, um das Bild zu Vergrößern
| interface java.util.Enumeration<E>
|

|
boolean hasMoreElements()
Testet, ob noch ein weiteres Element aufgezählt werden kann.2
|
|
|
E nextElement()
Liefert das nächste Element der Enumeration zurück. Diese Funktion kann eine NoSuchElementException auslösen, wenn nextElement() aufgerufen wird und das Ergebnis false beim Aufruf von hasMoreElements() ignoriert wird. |
Beispiel Die Aufzählung erfolgt meistens über einen Zweizeiler: Nehmen wir an, die Datenstruktur ds besitzt eine Methode elements(), die ein Enumeration-Objekt zurückgibt.
for ( Enumeration e = ds.elements(); e.hasMoreElements(); )
System.out.println( e.nextElement() );
|
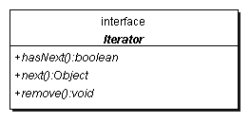
Die Schnittstelle Iterator
Ein Iterator ist für die neuen Collection-Klassen das, was Enumeration für die herkömmlichen Datenstruktur-Klassen ist. Die Schnittstelle Iterator besitzt kürzere Methodennamen als Enumeration. Nun heißt es hasNext() an Stelle von hasMoreElements() und next() an Stelle von nextElement(). Übergehen wir ein false von hasNext(), so erhalten wir wiederum eine NoSuchElementException. Zudem besitzt ein Iterator auch die Möglichkeit, das zuletzt aufgezählte Element aus dem zugrunde liegenden Container zu löschen. Dazu dient die optionale Methode remove(); sie lässt sich allerdings nur unmittelbar aufrufen, nachdem next() das zu löschende Element als Ergebnis geliefert hat. Eine Enumeration kann die aufgezählte Datenstruktur grundsätzlich nicht verändern.
Hier klicken, um das Bild zu Vergrößern
interface java.util. Iterator<E>
|
|
|
boolean hasNext()
Liefert true, falls die Iteration weitere Elemente bietet. |
|
|
E next()
Liefert das nächste Element in der Aufzählung oder NoSuchElementException, wenn keine weiteren Elemente mehr vorhanden sind. |
|
|
void remove()
Entfernt das Element, das der Iterator zuletzt bei next() geliefert hat. Implementiert ein Iterator diese Funktion nicht, so löst er eine UnsupportedOperationException aus. |
| Hinweis Es ist eine interessante Frage, warum es die Methode remove() im Iterator gibt. Die Erklärung dafür ist, dass der Iterator die Stelle kennt, an der sich die Daten befinden (eine Art Cursor). Darum können die Daten auch effizient direkt dort gelöscht werden. Das erklärt jedoch nicht unbedingt, warum es keine Einfüge-Methode gibt. Ein allgemeiner Grund mag sein, dass bei vielen Container-Typen das Einfügen an einer bestimmten Stelle keinen Sinn ergibt, etwa bei SortedSet, SortedMap, Set und Map. Dort ist die Einfügeposition durch die Sortierung vorgegeben oder belanglos (beziehungsweise bei HashSet durch die interne Realisierung bestimmt), also kein Fall für einen Iterator. Dazu wirft Einfügen weitere Fragen auf: Vor oder nach dem zuletzt per next() gelieferten Element? Soll das neue Element mit aufgezählt werden oder nicht? Auch dann nicht, wenn es in der Sortierung erst später an die Reihe käme? Eine Löschen-Methode ist problemloser und universell anwendbar.
|
1 Das Wort »Algorithmus« geht auf den persisch-arabischen Mathematiker Ibn Mûsâ Al-Chwârismî zurück, der im 9. Jahrhundert lebte.
2 Enumeratoren (und Iteratoren) können nicht serialisiert werden, da sie die Schnittstelle Serializable nicht implementieren.
|