
|
|
|||||
Die Kompilierung des folgenden Codeabschnitts führt beispielsweise zu einem Fehler: // Fehler using System; [CLSCompliant(true)] class Test { public uint Process() {return(0);} } 32.3 Benennung von Klassen
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Methode | p=10, i=2.000.000 | p=1.000, i=20.000 | p=100.000, i=200 |
| Baseline | 1.562 | 0.963 | 3.459 |
| Unsafe | 1.486 | 1.111 | 3.441 |
| Memcpy | 2.028 | 1.121 | 2.703 |
Bei kleinen Arrays ist der unsichere Code am schnellsten, für sehr umfangreiche Arrays erzielte der Systemaufruf die besten Ergebnisse. Der Systemaufruf ist weniger gut für kleine Arrays geeignet, da beim Aufruf der systemeigenen Funktion Overhead entsteht. Interessant ist, dass der unsichere Code nicht als klarer Sieger gegenüber dem Baseline-Code aus dem Vergleich hervorgeht.
Was lernen wir daraus? Der Einsatz von unsicherem Code kann nicht mit schnellerem Code gleichgesetzt werden, und es ist wichtig, im Rahmen der Leistungsoptimierung einen Vergleichstest durchzuführen.
Die Laufzeit ermöglicht einer Struktur über das Attribut StructLayout, das Layout der zugehörigen Datenmitglieder festzulegen. Standardmäßig wird das Layout einer Struktur automatisch bestimmt, d. h., die Felder können von der Laufzeit beliebig angeordnet werden. Bei der Verwendung von interop zum Aufruf von systemeigenem oder COM-Code ist möglicherweise eine weitergehende Steuerung erforderlich.
Beim Setzen des StructLayout-Attributs können über den Aufzählungsbezeichner LayoutKind drei Layouttypen angegeben werden:
| Sequential alle Felder werden in der Deklarationsreihenfolge verwendet. Beim sequenziellen Layout kann mit der Eigenschaft Pack die Packart bestimmt werden. |
| Explicit jedes Feld verfügt über ein festgelegtes Offset. Beim expliziten Layout muss das StructOffset-Attribut für jedes Mitglied verwendet werden, um das Elementoffset in Bytes anzugeben. |
| Union alle Mitglieder werden Offset 0 zugeordnet. |
Zusätzlich kann die Eigenschaft CharSet gesetzt werden, um für die Zeichenfolgendatenmitglieder das Standardmarshalling festzulegen.
Die Dokumentation stets auf dem neuesten Stand der aktuellen Implementierung zu halten, stellt immer eine Herausforderung dar. Eine Möglichkeit hierbei ist die, die Dokumentation als Bestandteil des Quellcodes zu verwalten und anschließend in eine separate Datei zu extrahieren.
C# unterstützt ein XML-basiertes Dokumentationsformat. Mit diesem kann der XML-Aufbau geprüft und eine kontextbasierte Validierung ausgeführt werden, es können compilerspezifische Informationen eingefügt werden (z. B. vollqualifizierte Namen für Mitglieder und Parameter); anschließend werden die Daten in eine separate Datei geschrieben.
Die XML-Unterstützung von C# kann in zwei Bereiche gegliedert werden, die Compilerunterstützung und die Dokumentationskonventionen. Zur Compilerunterstützung gehören Tags, die durch den Compiler auf besondere Weise verarbeitet werden, entweder für die Überprüfung von Inhalten oder für die Symbolsuche. Die übrigen Tags definieren die .NET-Dokumentationskonventionen und werden unverändert durch den Compiler übergeben.
Die Compilerunterstützungstags sind ein gutes Beispiel für die Zaubertricks eines Compilers; sie werden mit Hilfe von Informationen verarbeitet, die nur dem Compiler bekannt sind. Das folgende Beispiel veranschaulicht die Verwendung der Unterstützungstags:
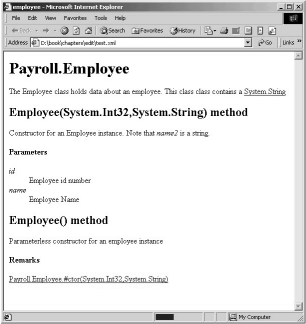
// Datei: employee.cs using System; namespace Payroll { /// <summary> /// Die Employee-Klasse enthält Daten zu einem Mitarbeiter. /// Diese Klasse enthält eine <see cref="String">string</see> /// </summary> public class Employee { /// <summary> /// Erstellungsroutine für eine Employee-Instanz. Beachten Sie, dass /// <paramref name="name">name2</paramref> eine Zeichenfolge ist. /// </summary> /// <param name="id">Mitarbeiter-ID</param> /// <param name="name">Mitarbeitername</param> public Employee(int id, string name) { this.id = id; this.name = name; } /// <summary> /// Parameterlose Erstellungsroutine für eine Employee-Instanz. /// </summary> /// <remarks> /// <seealso cref="Employee(int, string)">Employee(int, string)</seealso> /// </remarks> public Employee() { id = -1; name = null; } int id; string name; } }
Der Compiler führt eine spezielle Verarbeitung der vier Dokumentationstags durch. Bei den Tags param und paramref wird geprüft, ob es sich bei dem Namen innerhalb des Tags um einen Parameternamen für die Funktion handelt.
Bei den Tags see und seealso wird unter Verwendung der Regeln für die Bezeichnersuche nach dem im cref-Attribut übergebenen Namen gesucht, damit der Name in einen vollqualifizierten Namen aufgelöst werden kann. Anschließend wird vor dem Namen ein Code eingefügt, um zu kennzeichnen, auf was sich der Name bezieht. Beispiel:
<see cref="String">
<see cref="T:System.String">
String wird in die Klasse System.String aufgelöst, T: bedeutet, dass es sich um einen Typ handelt.
Das seealso-Tag wird ähnlich gehandhabt:
<seealso cref="Employee(int, string)">
<seealso cref="M:Payroll.Employee.#ctor(System.Int32,System.String)">
Der Verweis bezieht sich auf eine Erstellungsmethode, die als ersten Parameter einen int-, als zweiten Parameter einen string-Wert aufweist.
Zusätzlich zur vorstehenden Übersetzung legt der Compiler die XML-Informationen zu jedem Codeelement in einem member-Tag ab, das den Mitgliedsnamen unter Verwendung der gleichen Codierung angibt. Dies ermöglicht einem Nachverarbeitungstool das einfache Abgleichen der Mitglieder und der Verweise auf Mitglieder.
Die aus dem vorstehenden Beispiel generierte XML-Datei lautet folgendermaßen (mit einigen Wortumbrüchen):
<?xml version="1.0"?> <doc> <assembly> <name>employee</name> </assembly> <members> <member name="T:Payroll.Employee"> <summary> /// Die Employee-Klasse enthält Daten zu einem Mitarbeiter. Diese Klasse enthält eine <see cref="T:System.String">string</see> </summary> </member> <member name="M:Payroll.Employee.#ctor(System.Int32,System.String)"> <summary> /// Erstellungsroutine für eine Employee-Instanz. Beachten Sie, dass /// <paramref name="name2">name</paramref> eine Zeichenfolge ist. </summary> <param name="id">Mitarbeiter-ID</param> <param name="name">Mitarbeitername</param> </member> <member name="M:Payroll.Employee.#ctor"> <summary> /// Parameterlose Erstellungsroutine für eine Employee-Instanz. </summary> <remarks> <seealso cref="M:Payroll.Employee.#ctor(System.Int32,System.String)" >Employee(int, string)</seealso> </remarks> </member> </members> </doc>
Die Nachverarbeitung einer Datei kann einfach sein; es kann eine XSL-Datei (Extensible Style Language) mit Festlegungen zum XLM-Rendering hinzugefügt werden. Dies führt in einem Browser mit XSL-Unterstützung zu einer Anzeige wie in Abbildung 32.1.
|
Die übrigen XML-Dokumentationstags beschreiben die .NET-Dokumentationskonventionen. Sie können für ein bestimmtes Projekt erweitert, bearbeitet oder ignoriert werden.
| Tag | Beschreibung |
| <Summary> | Eine kurze Beschreibung des Elements |
| <Remarks> | Eine ausführliche Beschreibung eines Elements |
| <c> | Formatzeichen als Code innerhalb eines anderen Textes |
| <code> | Mehrzeiliger Codeabschnitt üblicherweise in einem <example>-Abschnitt |
| <example> | Ein Beispiel zur Verwendung einer Klasse oder Methode |
| <exception> | Die von einer Klasse ausgegebenen Ausnahmen |
| <list> | Eine Liste von Elementen |
| <param> | Beschreibt einen Parameter für eine Mitgliedsfunktion |
| <paramref> | Ein Verweis auf einen Parameter in einem anderen Text |
| <permission> | Die auf ein Mitglied angewendete Berechtigung |
| <returns> | Der Rückgabewert einer Funktion |
| <see cref="member"> | Eine Verknüpfung zu einem Mitglied oder Feld in der aktuellen Kompilierungsumgebung |
| <seealso cref="member"> | Eine Verknüpfung im »Siehe auch«-Abschnitt der Dokumentation. |
| <value> | Beschreibt den Wert einer Eigenschaft. |
Die Speicherbereinigung hat in einigen Gebieten der Softwarewelt einen schlechten Ruf. Einige Programmierer sind der Meinung, dass eine selbst durchgeführte Speicherzuordnung in jedem Fall besser ist als eine automatische Speicherbereinigung.
Es stimmt, eine selbst durchgeführte Speicherbereinigung ist häufig besser, jedoch nur mit einer benutzerdefinierten Zuordnungsroutine für jedes Programm und wahrscheinlich auch für jede Klasse. Darüber hinaus erfordern benutzerdefinierte Zuordnungsroutinen eine Menge Schreibaufwand und müssen verwaltet werden.
In sehr vielen Fällen erzielt eine gut austarierte Speicherbereinigung gegenüber einer nicht verwalteten Heapzuordnungsroutine ähnliche oder bessere Ergebnisse.
In diesem Abschnitt sollen die Funktionsweise der Speicherbereinigung und deren Steuerung erläutert werden, und Sie erfahren, welche Steuerungsmöglichkeiten Ihnen in einer Welt mit automatischer Speicherbereinigung zur Verfügung stehen. Die hier bereitgestellten Informationen beziehen sich auf die PC-Plattform. Systeme mit eingeschränkteren Ressourcen weisen häufig einfachere Speicherbereinigungssysteme auf.
Beachten Sie des Weiteren, dass für Mehrprozessorsysteme und Servercomputer Optimierungen durchgeführt werden.
Die Heapzuordnung in der .NET-Laufzeitwelt ist sehr schnell; das System muss lediglich sicherstellen, dass für das angeforderte Objekt im verwalteten Heap genügend Platz vorhanden ist, einen Zeiger auf diesen Speicherort zurückgeben und den Zeiger an das Objektende verschieben.
Die Speicherbereinigung tauscht Einfachheit zur Zuordnungszeit gegen Komplexität zur Bereinigungszeit. Zuordnungen sind in den meisten Fällen sehr schnell auch, wenn nicht genügend Speicherplatz für die Zuordnung vorhanden ist und eine Speicherbereinigung zur Freigabe von Speicherplatz für die Objektzuordnung erforderlich ist.
Um sicherzustellen, dass genügend Speicherplatz vorhanden ist, muss das System natürlich unter Umständen eine Speicherbereinigung durchführen.
Zur Leistungsoptimierung werden große Objekte (>20K) von einem Heap für große Objekte aus zugeordnet.
Die .NET-Speicherbereinigung verwendet einen so genannten »Kennzeichnen und Komprimieren«-Algorithmus. Bei Durchführung einer Bereinigung startet die Speicherbereinigung an den Stammobjekten (einschließlich der globalen, statischen, lokalen und CPU-Register) und ermittelt alle Objekte, die von diesen Stammobjekten (Rootobjekten) referenziert werden. Über diesen Vorgang werden die derzeit in Verwendung befindlichen Objekte ermittelt, d. h., alle weiteren Objekte im System werden nicht länger benötigt.
Zum Abschließen der Bereinigung werden alle referenzierten Objekte in den verwalteten Heap kopiert, und die Zeiger auf die Objekte werden aktualisiert. Anschließend wird der Zeiger für den nächsten verfügbaren Speicherort an das Ende des referenzierten Objekts verschoben.
Da durch Speicherbereinigung Objekte und Objektverweise verschoben werden, dürfen im System keine weiteren Operationen durchgeführt werden. Mit anderen Worten, während der Speicherbereinigung müssen alle weiteren Prozesse gestoppt werden.
Es ist aufwendig, alle Objekte zu durchlaufen, die derzeit referenziert werden. Ein Großteil dieser Arbeit ist verlorene Liebesmüh, denn je älter ein Objekt ist, desto wahrscheinlicher ist es, dass der Verweis erhalten bleibt. Umgekehrt liegt die Wahrscheinlichkeit, dass der Verweis auf ein neueres Objekt aufgehoben wird, sehr hoch.
Das Laufzeitsystem macht sich dieses Verhalten durch eine Generationenimplementierung in der Speicherbereinigung zunutze. Die Objekte im Heap werden drei Generationen zugeordnet:
Bei Objekten der Generation 0 handelt es sich um neu zugeordnete Objekte, die nicht für die Bereinigung in Frage kommen. Objekte der Generation 1 haben eine Speicherbereinigung überstanden, Objekte der Generation 2 haben bereits mehrere Speicherbereinigungen überstanden. Im Hinblick auf den Entwurf ausgedrückt enthält Generation 2 tendenziell langlebige Objekte (z. B. Anwendungen), Generation 1 enthält Objekte mittlerer Lebensdauer (etwa Formulare oder Listen), Generation 0 enthält eher kurzlebige Objekte, beispielsweise lokale Variablen.
Wenn das Laufzeitsystem eine Bereinigung durchführen muss, wird zunächst eine Bereinigung von Generation 0 durchgeführt. Diese Generation enthält den größten Prozentsatz nicht referenzierter Objekte und liefert daher den meisten Speicherplatz bei kleinstem Aufwand. Wenn durch die Bereinigung dieser Generation nicht genügend Speicher freigegeben wird, wird Generation 1 bereinigt und im Anschluss daran ggf. eine Bereinigung von Generation 2 durchgeführt.
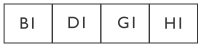
Abbildung 32.2 zeigt einige dem Heap zugeordnete Objekte, bevor eine Speicherbereinigung ausgeführt wird. Das numerische Suffix gibt die Objektgeneration an; anfänglich gehören alle Objekte der Generation 0 an. Aktive Objekte sind nur diejenigen, die sich im Heap befinden, auch wenn weitere Objekte zugeordnet werden könnten.
|
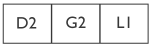
Zum Zeitpunkt der ersten Speicherbereinigung befinden sich nur noch die Objekte B und D in Verwendung. Abbildung 32.3 zeigt den Heapspeicher nach der Bereinigung.
|
Da B und D eine Bereinigung überstanden haben, wird ihre Generationenkennung auf 1 erhöht. Anschließend werden neue Objekte zugeordnet, wie in Abbildung 32.4 dargestellt.
|
Es vergeht einige Zeit. Bei der nächsten Speicherbereinigung handelt es sich bei D, G und H um aktive Objekte. Es wird eine Speicherbereinigung für Generation 0 durchgeführt, die zum in Abbildung 32.5 gezeigten Speicherstatus führt.
|
Obwohl Objekt B nicht länger aktiv ist, wird es nicht bereinigt, da die Bereinigung nur für Objekte der Generation 0 erfolgte. Nach der Zuordnung einiger weiterer Objekte sieht der Heapspeicher wie in Abbildung 32.6 dargestellt aus.
|
Wieder vergeht einige Zeit, und die aktiven Objekte lauten nun D, G und L. Die nächste Speicherbereinigung erfolgt für die Generationen 0 und 1 und führt zum in Abbildung 32.7 dargestellten Speicherstatus.
|
Die Speicherbereinigung unterstützt ein Konzept, das als Finalisierung bezeichnet wird und in gewisser Form den Zerstörungsroutinen in C++ ähnelt. In C# werden diese ebenfalls als Zerstörungsroutinen bezeichnet und mit der gleichen Syntax wie C++-Destruktoren deklariert, von der Laufzeitperspektive aus werden sie als Finalisierungsroutinen bezeichnet.
Finalisierungsroutinen ermöglichen die Ausführung einiger »Aufräumarbeiten«, bevor ein Objekt bereinigt wird. Für diese Routinen gelten jedoch erhebliche Einschränkungen, sie sollten daher nicht häufig eingesetzt werden.
Bevor wir zu diesen Einschränkungen kommen, soll die Funktionsweise der Finalisierungsroutinen erläutert werden. Wenn ein Objekt mit einer Finalisierungsroutine zugeordnet wird, fügt das Laufzeitsystem dem Objektverweis eine Liste mit Objekten hinzu, die eine Finalisierung benötigen. Wenn die Speicherbereinigung erfolgt und ein Objekt keine Verweise enthält, jedoch in der Finalisierungsliste aufgeführt ist, wird sie für die Finalisierung gekennzeichnet.
Nach Abschluss der Speicherbereinigung wird der Thread für die Finalisierung aktiviert; er ruft die Finalisierungsroutinen für alle Objekte auf, die für die Finalisierung gekennzeichnet wurden. Nachdem die Finalisierungsroutine für ein Objekt aufgerufen wurde, wird das Objekt aus der Finalisierungsliste entfernt und wird damit für die nächste Speicherbereinigung freigegeben.
Dieses Schema führt im Hinblick auf die Finalisierungsroutinen zu folgenden Einschränkungen:
| Objekte mit Finalisierungsroutinen erzeugen einen größeren Systemoverhead und verbleiben länger im System. |
| Die Finalisierung erfolgt über einen separaten Thread. |
| Für die Finalisierung besteht keine garantierte Ausführungsreihenfolge. Wenn ein Objekt a über einen Verweis auf Objekt b verfügt und beide Objekte Finalisierungsroutinen besitzen, wird die Finalisierungsroutine von Objekt b möglicherweise vor der Finalisierungsroutine von Objekt a ausgeführt. Dies kann dazu führen, dass Objekt a während der Finalisierung über kein gültiges Objekt b verfügt. |
| Finalisierungsroutinen werden bei einer normalen Programmbeendigung nicht aufgerufen, um die Beendigung zu beschleunigen. Dieses Verhalten kann gesteuert werden, hiervon wird jedoch abgeraten. |
Alle diese Einschränkungen zusammen genommen sind der Grund dafür, dass von einer Verwendung der Finalisierungsroutinen abgesehen werden sollte.
Gelegentlich kann es nützlich sein, das Verhalten der Speicherbereinigung zu steuern. Dies sollte in Maßen geschehen; der Zweck einer verwalteten Umgebung besteht zwar darin, die Vorgänge zu steuern, eine zu straffe Steuerung kann jedoch zu Problemen in anderen Bereichen führen.
Mit der Funktion System.GC.Collect() kann eine Bereinigung erzwungen werden. Dies ist nützlich, wenn das Programmverhalten dem Laufzeitsystem nicht bekannt ist. Wenn das Programm beispielsweise vor kurzem eine große Anzahl Operationen abgeschlossen hat und eine Menge Objekte freigesetzt werden, ist das Erzwingen einer Bereinigung sinnvoll.
Wenn es äußerst wichtig ist, bei Beendigung alle Finalisierungsroutinen aufzurufen, kann die Methode System.GC.RequestFinalizeOnShutdown() eingesetzt werden. Dieses Vorgehen kann zu einer Verlangsamung der Anwendungsbeendigung führen.
Wie bereits erwähnt, wird bei der Objekterstellung eine Instanz des Objekts auf die Finalisierungsliste gesetzt. Falls sich herausstellt, dass ein Objekt nicht finalisiert werden muss (beispielsweise, weil die Aufräumfunktion aufgerufen wurde), kann das Objekt über die Funktion System.GC.SupressFinalize() aus der Finalisierungsliste entfernt werden.
Die Beispiele im Abschnitt zu den Attributen haben gezeigt, wie die Reflektion zum Ermitteln der einer Klasse angehängten Attribute eingesetzt werden kann. Die Reflektion kann auch dazu verwendet werden, alle Typen in einer Assemblierung zu ermitteln oder die Funktionen in einer Assemblierung dynamisch zu ermitteln und aufzurufen. Mit der Reflektion kann sogar nach Bedarf die .NET-Zwischensprache ausgegeben werden, um direkt ausführbaren Code zu erzeugen.
Die Dokumentation der .NET Common Language Runtime enthält eine detailliertere Ausführung zur Verwendung der Reflektion.
In diesem Beispiel wird eine Assemblierung durchlaufen, um sämtliche der verwendeten Typen zu ermitteln.
using System; using System.Reflection; enum MyEnum { Val1, Val2, Val3 } class MyClass { } struct MyStruct { } class Test { public static void Main(String[] args) { // Alle Typen der Assemblierung auflisten, die als // Parameter übergeben werden Assembly a = Assembly.LoadFrom (args[0]); Type[] types = a.GetTypes(); // Jeden Typ durchsehen, und einige Informationen zum // jeweiligen Typ ausgeben. foreach (Type t in types) { Console.WriteLine ("Name: {0}", t.FullName); Console.WriteLine ("Namespace: {0}", t.Namespace); Console.WriteLine ("Base Class: {0}", t.BaseType.FullName); } } }
Bei Ausführung dieses Codebeispiels durch Übergeben des Namens der .exe-Datei wird folgende Ausgabe erzeugt:
Name: MyEnum Namespace: Base Class: System.Enum Name: MyClass Namespace: Base Class: System.Object Name: MyStruct Namespace: Base Class: System.ValueType Name: Test Namespace: Base Class: System.Object
In diesem Beispiel werden die Mitglieder eines Typs aufgelistet:
using System; using System.Reflection; enum MyEnum { Val1, Val2, Val3 } class MyClass { MyClass() {} static void Process() { } public int DoThatThing(int i, Decimal d, string[] args) { return(55); } public int value = 0; public float log = 1.0f; public static int value2 = 44; } class Test { public static void Main(String[] args) { // Namen und Werte im enum-Abschnitt abrufen Console.WriteLine("Fields of MyEnum"); Type t = typeof (MyEnum); // Instanz der Auflistung erstellen object en = Activator.CreateInstance(t); foreach (FieldInfo f in t.GetFields(BindingFlags.LookupAll)) { object o = f.GetValue(en); Console.WriteLine("{0}={1}", f, o); } // Jetzt Felder der Klasse durchlaufen Console.WriteLine("Fields of MyClass"); t = typeof (MyClass); foreach (MemberInfo m in t.GetFields(BindingFlags.LookupAll)) { Console.WriteLine("{0}", m); } // Jetzt Methoden der Klasse durchlaufen Console.WriteLine("Methods of MyClass"); foreach (MethodInfo m in t.GetMethods(BindingFlags.LookupAll)) { Console.WriteLine("{0}", m); foreach (ParameterInfo p in m.GetParameters()) { Console.WriteLine(" Param: {0} {1}", p.ParameterType, p.Name); } } } }
Dieser Code erzeugt die folgende Ausgabe:
Fields of MyEnum Int32 value__=0 MyEnum Val1=0 MyEnum Val2=1 MyEnum Val3=2 Fields of MyClass Int32 value Single log Int32 value2 Methods of MyClass Void Finalize () Int32 GetHashCode () Boolean Equals (System.Object) Param: System.Object obj System.String ToString () Void Process () Int32 DoThatThing (Int32, System.Decimal, System.String[]) Param: Int32 i Param: System.Decimal d Param: System.String[] args System.Type GetType () System.Object MemberwiseClone ()
Um die Werte der Felder in einer Aufzählung zu erhalten, muss eine Instanz der Aufzählung vorhanden sein. Obwohl die Aufzählung mit Hilfe einer einfachen new-Anweisung erstellt werden kann, wurde hier die Activator-Klasse eingesetzt, um das Erstellen einer Instanz nach Bedarf zu verdeutlichen.
Beim Durchlaufen der Methoden von MyClass werden die Standardmethoden von object ebenfalls angezeigt.
In diesem Beispiel wird die Reflektion dazu eingesetzt, alle Assemblierungen von der Befehlszeile aus zu öffnen, nach den Klassen zu suchen, mit denen eine bestimmte Assemblierung implementiert wird und anschließend eine Instanz dieser Klassen zu erstellen und eine Funktion für die Assemblierung aufzurufen.
Dieses Vorgehen ist nützlich, um eine Architektur mit sehr später Bindung bereitzustellen, bei der eine Komponente in andere Komponentenlaufzeiten integriert werden kann.
Dieses Beispiel umfasst vier Dateien. Die erste Datei definiert die IProcess-Schnittstelle, die durchsucht wird. Die zweite und die dritte Datei enthalten Klassen, mit denen diese Schnittstelle implemetiert wird. Jede dieser Dateien wird in einer separaten Assemblierung kompiliert. Die letzte Datei ist die Treiberdatei. Mit ihr werden die an der Befehlszeile übergebenen Assemblierungen geöffnet und nach Klassen durchsucht, mit denen IProcess implementiert wird. Wird eine solche Klasse ermittelt, wird eine Instanz der Klasse erzeugt und die Funktion Process() aufgerufen.
IProcess definiert die gesuchte Schnittstelle.
// Datei=IProcess.cs namespace MamaSoft { interface IProcess { string Process(int param); } }
// Datei=process1.cs // Kompilieren mit: csc /target:library process1.cs iprocess.cs using System; namespace MamaSoft { class Processor1: IProcess { Processor1() {} public string Process(int param) { Console.WriteLine("In Processor1.Process(): {0}", param); return("Raise the mainsail! "); } } }
Dieser Code sollte kompiliert werden mit
csc /target:library process1.cs iprocess.cs
// Datei=process2.cs // Kompilieren mit: csc /target:library process2.cs iprocess.cs using System; namespace MamaSoft { class Processor2: IProcess { Processor2() {} public string Process(int param) { Console.WriteLine("In Processor2.Process(): {0}", param); return("Shiver me timbers! "); } } class Unrelated { } }
Dieser Code sollte kompiliert werden mit
csc /target:library process2.cs iprocess.cs
// Datei=driver.cs // Kompilieren mit: csc driver.cs iprocess.cs using System; using System.Reflection; using MamaSoft; class Test { public static void ProcessAssembly(string aname) { Console.WriteLine("Loading: {0}", aname); Assembly a = Assembly.LoadFrom (aname); // Jeden Typ in der Assemblierung durchlaufen foreach (Type t in a.GetTypes()) { // Handelt es sich um eine Klasse, ist dies vielleicht die gesuchte Klasse if (t.IsClass) { Console.WriteLine(" Found Class: {0}", t.FullName); // Prüfen, ob IProcess implementiert wird if (t.GetInterface("IProcess") == null) continue; // IProcess wird implementiert. Instanz // des Objekts erstellen. object o = Activator.CreateInstance(t); // Parameterliste erstellen, aufrufen // und Rückgabewert ausgeben. Console.WriteLine(" Calling Process() on {0}", t.FullName); object[] args = new object[] {55}; object result; result = t.InvokeMember("Process", BindingFlags.Default | BindingFlags.InvokeMethod, null, o, args); Console.WriteLine(" Result: {0}", result); } } } public static void Main(String[] args) { foreach (string arg in args) ProcessAssembly(arg); } }
Nach der Kompilierung kann dieses Beispiel mit folgender DLL ausgeführt werden:
process process1.dll process2.dll
Auf diese Weise wird folgende Ausgabe erzeugt:
Loading: process1.dll Found Class: MamaSoft.Processor1 Calling Process() on MamaSoft.Processor1 In Processor1.Process(): 55 Result: Raise the mainsail! Loading: process2.dll Found Class: MamaSoft.Processor2 Calling Process() on MamaSoft.Processor2 In Processor2.Process(): 55 Result: Shiver me timbers! Found Class: MamaSoft.Unrelated
Bei Verwendung des /optimize+-Flags führt der C#-Compiler folgende Optimierungen durch:
| Nie gelesene lokale Variablen werden gelöscht, auch wenn sie zugeordnet sind. |
| Nicht erreichbarer Code (Code nach einem return beispielsweise) wird entfernt. |
| Ein try-catch mit leerem try-Block wird entfernt. |
| Ein try-finally mit leerem try-Block wird in normalen Code konvertiert. |
| Ein try-finally mit leerem finally-Block wird in normalen Code konvertiert. |
| Es wird eine Zweigoptimierung durchgeführt (Entfernen redundanter Sprünge in der IL). |
| << zurück |
| |||||
| |||||
| |||||
| |||||
| |||||
| |||||
| |||||
Copyright © Galileo Press GmbH 2001 - 2002
Für Ihren privaten Gebrauch dürfen Sie die Online-Version natürlich ausdrucken. Ansonsten unterliegt das <openbook> denselben Bestimmungen, wie die gebundene Ausgabe: Das Werk einschließlich aller seiner Teile ist urheberrechtlich geschützt. Alle Rechte vorbehalten einschließlich der Vervielfältigung, Übersetzung, Mikroverfilmung sowie Einspeicherung und Verarbeitung in elektronischen Systemen.





 bestellen
bestellen
