 |
Linux - Wegweiser für Netzwerker
Online-Version
Copyright © 2001
by O'Reilly Verlag GmbH & Co.KG
Bitte denken Sie daran:
Sie dürfen zwar die
Online-Version ausdrucken, aber diesen Druck nicht fotokopieren
oder verkaufen. Das Werk einschließlich aller seiner Teile ist
urheberrechtlich geschützt. Alle Rechte vorbehalten
einschließlich der Vervielfältigung, Übersetzung,
Mikroverfilmung sowie Einspeicherung und Verarbeitung in
elektronischen Systemen.
Wünschen Sie mehr
Informationen zu der gedruckten Version
des Buches Linux - Wegweiser für Netzwerker oder wollen Sie es
bestellen, dann klicken
Sie bitte hier.
|
IP-Routing
Wir greifen nun noch einmal die Frage auf, wie der Host, an den Pakete geschickt werden sollen, anhand der IP-Adresse gefunden wird. Verschiedene Teile der Adresse werden auf unterschiedliche Weise gehandhabt; es ist Ihre Aufgabe, entsprechende Dateien einzurichten, die angeben, wie die unterschiedlichen Teile zu handhaben sind.
IP-Netzwerke
Wenn Sie einen Brief an jemanden schreiben, versehen Sie den Briefumschlag üblicherweise mit der kompletten Adresse (Land, Postleitzahl, Straße etc.). Dann werfen Sie ihn in den Briefkasten, und die Post liefert ihn ans Ziel, d.h., er wird in das angegebene Land geschickt, wo die nationale Post ihn an die angegebene Adresse zustellt. Der Vorteil dieses hierarchischen Schemas ist offensichtlich: An welchem Ort auch immer Sie den Brief aufgeben, der lokale Postangestellte weiß ungefähr, in welche Richtung er den Brief weiterleiten soll, muß sich aber nicht darum kümmern, welchen Weg der Brief nimmt, wenn dieser erstmal das Zielland erreicht hat.
IP-Netzwerke sind auf dieselbe Art und Weise strukturiert. Das gesamte Internet besteht aus einer Reihe von Netzwerken, die als autonome Systeme bezeichnet werden. Jedes System führt das Routing zwischen den teilnehmenden Hosts intern durch, d.h., die Aufgabe der Auslieferung eines Datagramms wird auf die Suche nach einem Pfad zum Netzwerk des Zielhosts reduziert. Sobald ein Datagramm an einen beliebigen Host innerhalb eines Netzwerks übergeben ist, wird die weitere Verarbeitung ausschließlich von diesem Netz übernommen.
Subnetze
Diese Struktur spiegelt sich darin wieder, daß IP-Adressen, wie oben erwähnt, in einen Host- und einen Netzwerkteil aufgeteilt werden. Per Voreinstellung wird das Zielnetzwerk aus dem Netzwerkteil der IP-Adresse gewonnen. Hosts mit identischen IP-Netzwerknummern sollten innerhalb desselben Netzwerks zu finden sein, und alle Hosts innerhalb eines Netzwerks sollten dieselbe Netzwerknummer besitzen.1
Es macht Sinn, innerhalb des Netzwerks dasselbe Schema zu verwenden, weil es selbst wieder aus Hunderten kleinerer Netzwerke bestehen kann, bei denen die kleinsten Einheiten physische Netzwerke wie Ethernets sind. Aus diesem Grund erlaubt IP die Unterteilung eines IP-Netzwerks in mehrere Subnetze.
Ein Subnetz übernimmt die Verantwortung für die Übertragung von Datagrammen innerhalb eines bestimmten Bereichs von IP-Adressen des IP-Netzes, dem es angehört. Genau wie bei den Klassen A, B und C wird es über den Netzwerkteil der IP-Adressen identifiziert. Allerdings wird der Netzwerkteil etwas erweitert und enthält nun einige Bits aus dem Hostteil. Die Anzahl der Bits, die als Subnetznummer interpretiert werden, wird durch die sogenannte Subnetzmaske, oder kurz Netzmaske, bestimmt. Diese ist ebenfalls eine 32-Bit-Zahl, die die Bitmaske für den Netzwerkteil der IP-Adresse festlegt.
Das Netzwerk an der Groucho-Marx-Universität ist ein Beispiel für ein solches Netzwerk. Es verwendet die Klasse-B-Netzwerknummer 149.76.0.0, und die Netzmaske lautet somit 255.255.0.0.
Intern besteht das Universitätsnetz aus verschiedenen kleineren Netzwerken, wie beispielsweise den LANs der verschiedenen Institute. Also werden die IP-Adressen noch einmal in 254 Subnetze, von 149.76.1.0 bis 149.76.254.0, unterteilt. Dem Institut für theoretische Physik wurde beispielsweise die Nummer 149.76.12.0 zugeteilt. Der Universitäts-Backbone ist ein eigenständiges Netzwerk und besitzt die Nummer 149.76.1.0. Diese Subnetze verwenden dieselbe IP-Netzwerknummer, während gleichzeitig das dritte Oktett verwendet wird, um sie unterscheiden zu können. Sie verwenden also die Subnetzmaske 255.255.255.0.
Abbildung 2.1 zeigt, wie 149.76.12.4, die Adresse von quark, verschieden interpretiert wird, wenn ein normales Klasse-B-Netzwerk vorliegt bzw. Subnetze verwendet werden.
Abbildung
2.1:
Subnetz bei Klasse-B-Netzwerk
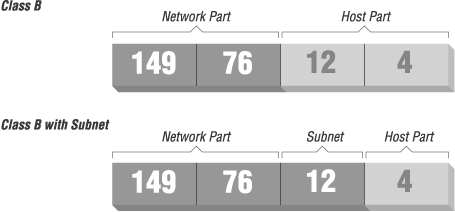
Es ist wichtig, festzuhalten, daß die Unterteilung in Subnetze nur eine interne Aufteilung des Netzwerks ist. Subnetze werden vom Besitzer (oder Administrator) des Netzwerks aufgebaut. Häufig werden Subnetze gebildet, um bestehende Grenzen widerzuspiegeln. Diese Grenzen können physischer (zwei Ethernet-Netze), administrativer (zwei Institute) oder geographischer Natur sein. Die Verantwortung für ein Subnetz wird an eine Kontaktperson delegiert. Diese Struktur wirkt sich allerdings nur auf das interne Verhalten des Netzwerks aus und ist nach außen hin völlig unsichtbar.
Gateways
Das Anlegen von Subnetzen ist nicht nur organisatorisch von Vorteil, es ist häufig auch die natürliche Konsequenz aus bestehenden Hardwaregrenzen. Die Sichtweise eines Hosts in einem bestehenden Netzwerk, beispielsweise einem Ethernet, ist sehr eingeschränkt: Die einzigen Hosts, mit denen er sich unterhalten kann, sind die Hosts, die sich in dem gleichen Netz befinden wie er selbst. Alle anderen Hosts können nur über sogenannte Gateways erreicht werden. Ein Gateway ist ein Host, der an zwei oder mehr physische Netze gleichzeitig angeschlossen ist. Er ist so konfiguriert, daß er Pakete zwischen diesen Netzen übertragen kann.
Abbildung 2.2 zeigt einen Ausschnitt der Netzwerk-Topologie an der Groucho-Marx-Universität (GMU). Hosts, die auf zwei Subnetzen zur gleichen Zeit präsent sind, sind mit beiden Adressen aufgeführt.
Damit IP feststellen kann, ob ein Host in einem lokalen Netzwerk präsent ist, müssen verschiedene physikalische Netzwerke verschiedenen IP-Netzwerken angehören. Beispielsweise ist die Netzwerknummer 149.76.4.0 für die Hosts des LANs des mathematischen Instituts reserviert. Wird ein Datagramm an quark geschickt, erkennt die Netzwerksoftware auf erdos sofort anhand der IP-Adresse 149.76.12.4, daß der Zielhost sich in einem anderen physikalischen Netzwerk befindet und daher nur durch ein Gateway erreicht werden kann (sophus per Voreinstellung).
sophus selbst ist mit zwei verschiedenen Subnetzen verbunden: mit dem des mathematischen Instituts und dem des Universitäts-Backbones. Jedes wird über ein eigenes Interface (eth0 bzw. fddi0) erreicht. Nun, welche IP-Adresse sollen wir ihm zuweisen? Sollen wir ihm eine auf dem Subnetz 149.76.1.0 oder auf 149.76.4.0 zuweisen?
Abbildung
2.2:
Ausschnitt der Netzwerk-Topologie an der Groucho-Marx-Universität
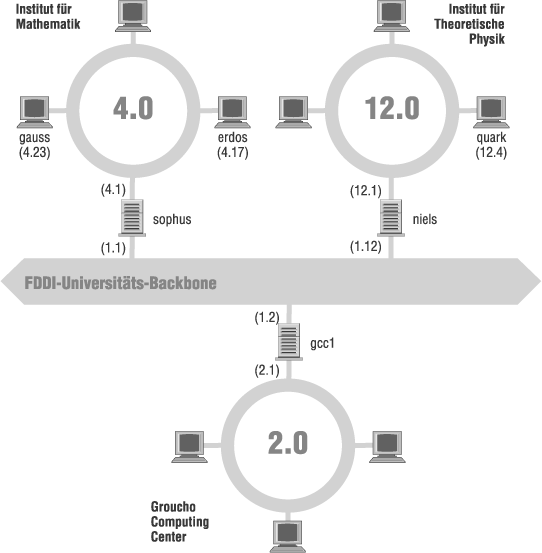
Die Antwort lautet: auf beiden. sophus wurde die Adresse 149.76.1.1 für das Netzwerk 149.76.1.0 und die Adresse 149.76.4.1 für das Netzwerk 149.76.4.0 zugewiesen. Einem Gateway wird also für jedes Netzwerk, dem es angehört, eine IP-Adresse zugewiesen. Diese Adressen — zusammen mit der entsprechenden Netzmaske — ergeben gemeinsam die Schnittstelle, über die auf das Subnetz zugegriffen wird. Die Abbildung von Schnittstellen auf Adressen für sophus würde also wie folgt aussehen:
|
Schnittstelle
|
Adresse
|
Netzmaske
|
|
eth0
|
149.76.4.1
|
255.255.255.0
|
|
fddi0
|
149.76.1.1
|
255.255.255.0
|
|
lo
|
127.0.0.1
|
255.0.0.0
|
Der letzte Eintrag beschreibt das Loopback-Interface lo, das bereits vorgestellt wurde.
Im allgemeinen können Sie den feinen Unterschied zwischen der Zuweisung einer Adresse an einen Host oder an sein Interface ignorieren. Bei Hosts wie erdos, die nur zu einem Netz gehören, spricht man im allgemeinen immer von dem Host mit dieser oder jener IP-Adresse, obwohl es genaugenommen die Ethernet-Schnittstelle ist, der diese IP-Adresse zugewiesen wurde. Andererseits ist diese Unterscheidung nur bei Gateways wirklich von Bedeutung.
Die Routing-Tabelle
Wir richten nun unsere Aufmerksamkeit darauf, wie IP ein Gateway auswählt, wenn es ein Datagramm an ein entferntes Netzwerk ausliefert.
Wir haben bereits gesehen, daß erdos bei einem Datagramm für quark die Zieladresse überprüft und entdeckt, daß sich diese nicht im lokalen Netz befindet. Aus diesem Grund sendet erdos das Datagramm an das Default-Gateway (sophus), das sich nun vor die gleiche Aufgabe gestellt sieht. sophus erkennt, daß sich quark nicht in einem der Netzwerke befindet, mit denen es direkt verbunden ist. Es muß also ein weiteres Gateway finden, an das es das Datagramm weiterleiten kann. Die richtige Wahl wäre niels, das Gateway des physikalischen Instituts. Daher benötigt sophus einige Informationen, um zu wissen, welche Zielnetze über welche Gateways zu erreichen sind.
Die Routing-Informationen, die IP dabei verwendet, sind in einer Tabelle zu finden, die Netzwerke mit Gateways verbindet, über die sie zu erreichen sind. Ein sogenannter Catch-All-Eintrag (die Default-Route) muß ebenfalls vorhanden sein. Dieses Gateway wird mit dem Netzwerk 0.0.0.0 assoziiert. Alle möglichen Zieladressen stimmen mit diesem Adreßmuster überein, da keines der 32 Bits passen muß. Deshalb werden alle Pakete, die an ein unbekanntes Netzwerk gehen, über dieses Gateway verschickt. Auf sophus würde die Tabelle also wie folgt aussehen:
|
Netzwerk
|
Netzmaske
|
Gateway
|
Schnittstelle
|
|
149.76.1.0
|
255.255.255.0
|
-
|
fddi0
|
|
149.76.2.0
|
255.255.255.0
|
149.76.1.2
|
fddi0
|
|
149.76.3.0
|
255.255.255.0
|
149.76.1.3
|
fddi0
|
|
149.76.4.0
|
255.255.255.0
|
-
|
eth0
|
|
149.76.5.0
|
255.255.255.0
|
149.76.1.5
|
fddi0
|
|
…
|
…
|
…
|
…
|
|
0.0.0.0
|
0.0.0.0
|
149.76.1.2
|
fddi0
|
Routen zu einem Netzwerk, mit dem sophus direkt verbunden ist, benötigen kein Gateway. In der Gateway-Spalte steht an dieser Stelle ein Bindestrich.
Der Test, ob eine bestimmte Zieladresse zu einer gegebenen Route paßt, ist eine mathematische Operation. Der Vorgang ist zwar relativ einfach, erfordert jedoch Grundkenntnisse in binärer Arithmetik und Logik. Zunächst wird aus der Netzadresse und der Netzmaske eine logische UND-Verknüpfung gebildet. Auf dieselbe Weise wird dann eine logische UND-Verknüpfung der Zieladresse mit der Netzmaske vollzogen. Die Route paßt genau dann zur Zieladresse, wenn beide Resultate identisch sind.
Mit anderen Worten: Die Route paßt, wenn diejenigen Bits der Netzadresse, die durch die Netzmaske angegeben werden (beginnend mit dem am weitesten links stehenden Bit, also dem höchstwertigen Bit im ersten Byte der Adresse), mit den gleichen Bits in der Zieladresse übereinstimmen.
Wenn die IP-Implementierung nach der besten Route zu einem Ziel sucht, kann es vorkommen, daß sie mehrere passende Routen findet. Wir wissen z.B., daß die Default-Route zu jeder Zieladresse paßt, während die Adressen von Datagrammen für Netzwerke, an die der Host direkt angeschlossen ist, auch auf lokale Routing-Einträge passen. Wie stellt IP nun fest, welche Route verwendet werden soll? Hier spielt die Netzmaske eine wichtige Rolle. Zwar passen beide Routen zur Zieladresse, jedoch hat die eine Route eine größere Netzmaske als die andere. Wir hatten bereits erwähnt, daß die Netzmaske dazu dient, unseren Adreßraum in kleinere Netzwerke aufzuspalten. Je größer eine Netzmaske ist, desto genauer wird die Zieladresse durch sie bestimmt. Werden Datagramme geroutet, sollte immer die Route mit der größten Netzmaske gewählt werden. Die Netzmaske der Default-Route besteht immer aus Nullbits, während die lokalen Netzwerke in der oben präsentierten Konfiguration eine 24-Bit-Netzmaske haben. Ein Datagramm, das sowohl zu einem lokalen Netzwerk als auch zur Default-Route paßt, wird immer bevorzugt an das zuständige lokale Device weitergeleitet, da eine lokale Netzwerk-Route immer eine größere Netzmaske hat als die Default-Route. Die Datagramme, die über die Default-Route weitergeleitet werden, sind immer diejenigen, die nicht zu den anderen Routen passen.
Routing-Tabellen können auf unterschiedliche Weise aufgebaut werden. Bei kleineren LANs ist es wahrscheinlich am effektivsten, die Tabelle von Hand zu erstellen und sie dann während der Boot-Phase mit Hilfe des route-Befehls (siehe Kapitel 5 TCP/IP-Konfiguration) an IP zu übergeben. Bei größeren Netzwerken werden sie zur Laufzeit von sogenannten Routing-Dämonen erzeugt und eingerichtet. Diese Dämonen laufen auf zentralen Hosts des Netzwerks und tauschen untereinander Routing-Informationen aus, um die “optimalen” Routen zwischen den teilnehmenden Netzwerken zu berechnen.
Abhängig von der Größe des Netzwerks werden verschiedene Routing-Protokolle verwendet. Für das Routing innerhalb autonomer Systeme (wie der Groucho-Marx-Universität) werden die internen Routing-Protokolle verwendet. Das bekannteste dieser Protokolle ist RIP, oder Routing Information Protocol, das im BSD-routed-Dämon implementiert ist. Das Routing zwischen autonomen Systemen muß durch externe Routing-Protokolle wie EGP (External Gateway Protocol) oder BGP (Border Gateway Protocol) erledigt werden. Diese wurden (ebenso wie RIP) im gated-Dämon der University of Cornell implementiert.
Metrische Werte
Beim auf RIP basierenden dynamischen Routing wird der beste Weg zu einem Zielhost oder -Netzwerk anhand der Anzahl der “Hops” gewählt, d.h. anhand der Anzahl von Gateways, die ein Datagramm passieren muß, bevor es sein Ziel erreicht hat. Je kürzer die Route ist, desto besser wird sie von RIP bewertet. Sehr lange Routen von 16 oder mehr Hops werden als unbrauchbar betrachtet und verworfen.
Soll RIP verwendet werden, um die für Ihr lokales Netzwerk anfallenden Routing-Informationen zu verwalten, muß auf allen Hosts gated laufen. Während des Bootens prüft gated alle aktiven Netzwerk-Interfaces. Existiert mehr als eine aktive Schnittstelle (das Loopback-Interface nicht mitgezählt), nimmt es an, daß der Host als Gateway fungiert, und gated verteilt aktiv Routing-Informationen. Andernfalls verhält es sich passiv und empfängt nur eingehende RIP-Updates, um die lokale Routing-Tabelle zu aktualisieren.
Wenn gated die Daten aus der lokalen Routing-Tabelle verteilt, berechnet es die Länge der Route anhand einer sogenannten Metrik, die Teil des Eintrags in der Routing-Tabelle ist. Dieser Wert wird vom Systemadministrator während der Konfiguration der Route eingetragen und sollte die Kosten bezüglich der Verwendung dieser Route widerspiegeln.2 Die Metrik einer Route zu einem Subnetz, mit dem der Host direkt verbunden ist, sollte also immer null sein, während ein Weg, der über zwei Gateways führt, einen Wert von zwei haben sollte. Andererseits müssen Sie sich um diese Werte keine Gedanken machen, wenn Sie RIP oder gated nicht verwenden.
| 1. |
Autonome Systeme sind noch etwas allgemeiner. Sie können mehr als ein Netzwerk umfassen.
|
| 2. |
Im einfachsten Fall ergeben sich die Kosten z.B. aus der Anzahl der Hops, die bis zum Ziel übersprungen werden müssen. Eine gründliche Kostenanalyse in komplexen Netzwerkarchitekturen ist dagegen schon eine Wissenschaft für sich.
|
Weitere Informationen zum
Linux - Wegweiser für Netzwerker
Weitere Online-Bücher &
Probekapitel finden Sie in unserem Online Book Center
O'Reilly Home|O'Reilly-Partnerbuchhandlungen|Bestellinformationen
Kontakt|Über
O'Reilly|Datenschutz
© 2001,
O'Reilly Verlag



