4.6 Zerlegen von Zeichenketten
Die Java-Bibliothek bietet einige Klassen und Funktionen, um große Zeichenketten in kleinere nach bestimmten Mustern zu zerlegen. In diesem Kontext sind die Begriffe Token und Delimiter zu nennen: Ein Token ist ein Teil eines Strings, das durch bestimmte Trennzeichen (engl. delimiter) von anderen Token getrennt wird. Nehmen wir als Beispiel den Satz »Moderne Musik ist Instrumentespielen nach Noten« (Peter Sellers). Wählen wir Leerzeichen als Trennzeichen, lauten die einzelnen Token »Moderne«, »Musik« und so weiter.
4.6.1 StringTokenizer
Die Klasse StringTokenizer hilft uns, eine Zeichenkette in Token zu zerlegen, wobei die Klasse nicht an bestimmte Trenner gebunden ist sie können vielmehr völlig frei gewählt werden. In der Voreinstellung sind Tabulator, Leerzeichen und Zeilentrenner die Delimiter.
| Hinweis In der Implementierung von StringTokenizer können nur einzelne Zeichen als Trenner verwendet werden. Es sind keine Zeichenfolgen wie »:=« denkbar.
|
Hier klicken, um das Bild zu Vergrößern
Beispiel Um einen String mithilfe eines StringTokenizer-Objekts zu zerlegen, wird dem Konstruktor der Klasse der zu unterteilende Text als Argument übergeben:
StringTokenizer tokenizer;
tokenizer = new StringTokenizer( "Schweigen kann die
grausamste Lüge sein." );
|
Sollen andere Zeichen als die voreingestellten Trenner den Satz zerlegen, kann dem Konstruktor als zweiter String eine Liste von Trennern übergeben werden. Jedes Zeichen, das in diesem String vorkommt, fungiert als einzelnes Trennzeichen:
StringTokenizer st;
st = new StringTokenizer( "Blue=0000ff\nGreen:00ff00\n", "=:\n" );
Um den Text abzulaufen, gibt es die Methoden nextToken() und hasMoreTokens().1
Die Methode nextToken() liefert das nächste Token im String. Ist kein Token mehr vorhanden, wird eine NoSuchElementException ausgelöst. Damit wir frei von diesen Überraschungen sind, können wir mit der Methode hasMoreTokens() nachfragen, ob noch weitere Token vorliegen.
Beispiel Das folgende Stück Programmtext zeigt die leichte Benutzung der Klasse:
String s = "Faulheit ist der Hang zur Ruhe ohne vorhergehende Arbeit";
StringTokenizer tokenizer = new StringTokenizer( s );
while ( tokenizer.hasMoreTokens() )
System.out.println( tokenizer.nextToken() );
|
Neben den beiden Konstruktoren existiert noch ein Dritter, der auch die Trennzeichen als eigenständige Bestandteile bei nextToken() übermittelt.
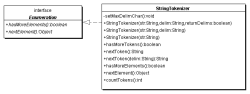
Hier klicken, um das Bild zu Vergrößern
class java.util. StringTokenizer
implements Enumeration<Object>
|

|
StringTokenizer( String str, String delim, boolean returnTokens )
Ein String-Tokenizer für str, wobei jedes Zeichen in delim als Trennzeichen gilt. Ist returnTokens gleich true, so werden die Trennzeichen beim Aufzählen mit zurückgegeben. |
|
|
StringTokenizer( String str, String delim )
Ein String-Tokenizer für str, wobei alle Zeichen in delim als Trennzeichen gelten. Entspricht dem Aufruf von this(str, delim, false); |
|
|
StringTokenizer( String str )
Ein String-Tokenizer für str. Entspricht dem Aufruf von this(str, " \t\n\r\f", false); Die Trennzeichen sind Leerzeichen, Tabulator, Zeilenende und Seitenvorschub. |
|
|
boolean hasMoreTokens()
Testet, ob weitere Token verfügbar sind. |
|
|
String nextToken()
Liefert das nächste Token vom String-Tokenizer. |
|
|
String nextToken( String delim )
Die Delimiter-Zeichen werden erst neu gesetzt, und anschließend wird das nächste Token geholt. |
|
|
boolean hasMoreElements()
Ist gleich dem Aufruf von hasMoreTokens(). Existiert nur, damit das Objekt als Enumeration benutzt werden kann. |
|
|
Object nextElement()
Ist gleich dem Aufruf von nextToken(). Existiert nur, damit das Objekt als Enumeration benutzt werden kann. Der weniger spezifische Ergebnistyp Object macht eine Typumwandlung erforderlich. |
|
|
int countTokens()
Zählt die Anzahl der noch möglichen nextToken()-Methodenaufrufe. Die aktuelle Position wird dadurch nicht berührt. Der Aufruf der Funktion ist nicht billig. |
|
|
nextToken() und nextElement() können eine NoSuchElementException auslösen. |
Beispiel Die countTokens()-Funktion ist hilfreich beim Aufbauen eines Felds, welches Ergebnisse des Parsens aufnehmen soll. Nehmen wir an, wir haben eine Variable ints vom Typ String mit dem Inhalt »0, 1, 4, 6, 13«. Für die Zeichenfolge soll ein Ganzzahl-Feld aufgebaut werden, so dass jedes Zahl auf das Feld abgebildet wird. Der Trenner ist ein Komma, doch auch Leerzeichen und Tabulator sollten Trenner sein.
StringTokenizer tokenizer = new StringTokenizer( ints, ", \t" );
int numbers[] = new int[tokenizer.countTokens()];
for ( int i = 0; tokenizer.hasMoreTokens(); ++i )
numbers[i] = Integer.parseInt( tokenizer.nextToken() );
}
|
4.6.2 Splitten von Zeichenketten mit split() aus Pattern
Mit der Funktion split() aus Pattern oder String kann eine Trennfolge definiert werden, die eine Zeichenkette in Teilzeichenketten zerlegt, ähnlich wie es der StringTokenizer macht. Der StringTokenizer ist jedoch beschränkt auf einzelne Zeichen als Trennsymbole, während die Methode split() einen regulären Ausdruck zur Beschreibung der Trennsymbole verwendet:
final class java.util.regex.Pattern
implements Serializable
|
|
|
String[] split( CharSequence input )
Zerlegt die Zeichenfolge input in Teilzeichenketten, wie es das aktuelle Pattern-Objekt befiehlt. |
|
|
String[] split( CharSequence input, int limit )
Wie split(CharSequence), nur durch limit begrenzt viele Teilzeichenketten. |
Beispiel Datumsformate sollen in der Reihenfolge Tag, Monat, Jahr eingegeben werden. Die Trennzeichen sollen jedoch entweder Punkt, Minus oder Slash sein. Damit lässt sich ein Pattern aufbauen, das folgendes Format hat:
Pattern p = Pattern.compile( "[/.-]" );
In diesem Fall funktioniert dies auch noch mit new StringTokenizer(...,"/.-"), doch längere Trennsymbole wie := oder :: würden mit StringTokenizer nicht mehr funktionieren.
|
An die split()-Funktion übergeben wir als Argument die Zeichenkette, die zerlegt werden soll. Werfen wir einen Blick auf ein Beispiel, welches die Felder in der Methode date() ausgibt:
Listing 4.4
SplitDemo.java
import java.util.regex.*;
public class SplitDemo
{
public static void date( String fields[] )
{
for ( int i = 0; i < fields.length; i++ )
System.out.print( fields[i] + " " );
System.out.println();
}
public static void main( String args[] )
{
Pattern p = Pattern.compile( "[/.-]" );
date( p. split ( "1231973" ) );
date( p. split ( "12.3.1973" ) );
date( p. split ( "12/3/1973" ) );
}
}
4.6.3 split() in String
In der String-Klasse gibt es auch die Funktion split(). Sie ist eine Objektmethode, die die aktuelle Zeichenkette, die das String-Objekt repräsentiert, zerlegt. Diese Methode benötigt jetzt umgekehrt den regulären Ausdruck als Argument. Die Implementierung delegiert jedoch die eigentliche Arbeit an das Pattern-Objekt:
public String[] split( String regex, int limit )
{
return Pattern.compile( regex ).split( this, limit );
}
public String[] split( String regex )
{
return split( regex, 0 );
}
final class java.lang. String
implements CharSequence, Comparable<String>, Serializable
|
|
|
String[] split( String regex )
Zerlegt die aktuelle Zeichenkette mit dem regulären Ausdruck. |
|
|
String[] split( String regex, int limit )
Zerlegt die aktuelle Zeichenkette mit dem regulären Ausdruck, liefert jedoch maximal begrenzt viele Teilzeichenfolgen. |
4.6.4 Die neue Klasse Scanner
Noch flexibler als ein StringTokenizer ist die in Java 5 eingeführte Klasse java.util.Scanner. Die Klasse gibt wie StringTokenizer auch Token für Token, aber der Delimiter kann ein regulärer Ausdruck sein. Zusätzlich lässt sich mit findInLine() eine Zeile suchen, die auf einen Ausdruck passt.
Einen sichtbaren Konstruktor hat die Klasse Scanner nicht. Vielmehr gibt es eine Fabrik-Funktion create(), der unterschiedliche Quellen übergeben werden, etwa einem String, einen Datenstrom beim Einlesen von der Kommandozeile wird das System.in sein , einem File-Objekt oder diverse NIO-Objekte.
Nach dem Erzeugen bieten sich unterschiedliche nextXXX()-Funktionen an, die das nächste Token einlesen und in ein gewünschtes Format konvertiert, etwa in ein double bei nextDouble(). Über gleich viele hasNextXXX()-Funktionen lässt sich erfragen, ob noch ein Token folgt.
|
Beispiel Von der Standardeingabe soll ein int gelesen werden.
Scanner scanner = Scanner.create( System.in );
int i = scanner.nextInt();
Der String s enthält eine Zeile wie a := b. Uns interessiert linker und rechter Teil.
Scanner scanner = Scanner.create( "12,34" ).useLocale( Locale.GERMAN );
System.out.println( scanner.nextDouble() ); // 12.34
Das klingt logisch, funktioniert aber auch ohne useLocale(Locale.GERMAN)! Der Grund ist einfach: Der Scanner setzt die Locale vorher standardmäßig auf Locale.getDefault(). Das bedeutet aber wiederum, dass eine übliche Zahl wie 12.34 nicht erkannt wird und als java.util.InputMismatchException gemeldet wird.
4.6.5 Der BreakIterator als Wort- und Satztrenner
Zeichenketten werden von Benutzern aus ganz unterschiedlichen Gründen durchlaufen. Einige wollen jedes Zeichen bearbeiten, andere wiederum suchen in der Zeichenkette nach Wort- oder Satztrennern. Sun sieht für diese Aufgabe im Java-Paket java.text die Klasse BreakIterator vor. Dieser Iterator lässt sich mit statischen Funktionen erzeugen, die optional auch nach einer Sprache trennen. Keine übergebene Sprache bedeutet automatisch die gefundene Standardsprache.
abstract class java.text. BreakIterator
implements Cloneable
|
|
|
static BreakIterator getCharacterInstance()
static BreakIterator getCharacterInstance( Locale where )
Trennt nach Zeichen. Entspricht einer Iteration über charAt(). |
|
|
static BreakIterator getLineInstance()
static BreakIterator getLineInstance( Locale where )
Trennt nach Zeilen. |
|
|
static BreakIterator getSentenceInstance()
static BreakIterator getSentenceInstance( Locale where )
Trennt nach Sätzen. |
|
|
static BreakIterator getWordInstance()
static BreakIterator getWordInstance( Locale where )
Trennt nach Wörtern. Trenner wie Leerzeichen und Satzzeichen gelten ebenfalls als Wörter. |
Das nächste Beispiel zeigt, wie ohne großen Aufwand durch Zeichenketten gewandert werden kann. Die Verwendung eines StringTokenizers ist nicht nötig. Einmal sollen die Wörter und einmal die Sätze ausgegeben werden. Die Hilfsfunktion out() gibt die Abschnitte der Zeichenkette bezüglich eines Iterators aus.

Hier klicken, um das Bild zu Vergrößern
Listing 4.5
StringVerpfluecker.java
import java.text.BreakIterator;
import java.util.Locale;
public class StringVerpfluecker
{
static void out( String s, BreakIterator iter )
{
int last = iter.first();
int next = iter.next(); // erstes Wort einlesen.
for ( ; next != BreakIterator.DONE; next = iter.next() )
{
System.out.println( s.subSequence( last, next ) );
last = next;
}
}
public static void main( String args[] )
{
String helmutKohl = "Ich weiß, dass ich 1945 fünfzehn war und
1953 achtzehn.";
BreakIterator iterator = BreakIterator.getWordInstance();
iterator.setText( helmutKohl );
out( helmutKohl, iterator );
helmutKohl = "Das deutsche Volk hat nun mal beschlossen,
weniger Kinder zu zeugen. "+
"Das ist eine Sache, die wir nicht einmal den Sozialdemokraten
anhängen können.";
iterator = BreakIterator.getSentenceInstance( Locale.GERMAN );
iterator.setText( helmutKohl );
out( helmutKohl, iterator );
}
}
1 Die Methode hasMoreElemente() ruft direkt hasMoreTokens() auf und wurde nur implementiert, da ein StringTokenizer die Schnittstelle Enumeration implementiert.
|
|