24.6 String-Matching
Textverarbeitungsprogramme verwenden für die Bearbeitung von Texten Zeichenkettenfolgen in Form von einzelnen Buchstaben, Nummern oder Sonderzeichen.
Wenn Sie einen Texteditor oder Ähnliches entwickeln wollen, werden Sie auch Funktionen wie das Suchen von Strings oder Teilstrings benötigen; oder etwa die Syntaxhervorhebung einer bestimmten Programmiersprache. Eine weitere Möglichkeit ist das Pattern Matching, das Sie vielleicht aus Perl oder Shell von Linux kennen.
Für solche und weitere Anwendungsmöglichkeiten werden String-Matching-Algorithmen genutzt. Sie funktionieren nach folgendem Prinzip: In einer Textzeichenfolge, wie etwa dem Text in diesem Buch, soll mit einem Suchmuster die Häufigkeit der enthaltenen N-Zeichen und M-Zeichen verglichen werden.
Das Ziel des Kapitels ist es nicht, die Algorithmen anhand mathematischer Formeln zu erklären, sondern eher, die Algorithmen so zu erklären, dass ihr Prinzip, nach dem sie funktionieren, verstanden wird. Auf der Suche nach genaueren Beschreibungen werden Sie im Anhang dieses Buches unter Weiterführende Literatur fündig.
Als Schnittstelle zu diesen Beispielen soll eine Struktur verwendet werden, welche die Daten von der Kommandozeile entnimmt und für eventuelle Auswertungen speichert.
struct datei{
char name[LEN]; /* Name der Datei */
int gefunden; /* Anzahl gefunden */
};
typedef struct datei DATEI;
Sie können diese Struktur gern um weitere Informationen wie die Position der Fundstelle erweitern. In den Beispielen wird jeweils ein Array von Strukturen verwendet. In der Praxis können Sie auch verkettete Listen einsetzen.
Der Aufruf der Programme lautet hierbei immer:
programmname suchstring datei1 ... bis datei_n
Bei all den Zusätzen sollten Sie dennoch das Hauptaugenmerk auf die einzelnen Algorithmen richten. Alle Matching-Algorithmen suchen nach einer bestimmten Textfolge. Sofern Sie an ganzen Wörtern interessiert sind, können Sie den Algorithmus entsprechend anpassen. Dabei sollten Sie darauf achten, dass vor und nach dem Suchstring alle Whitespace-Zeichen beachtet werden (Newline, Tabulator und Space).
24.6.1 Brute-Force-Algorithmus
Der einfachste Algorithmus liegt auf der Hand. Es werden alle infrage kommenden Positionen des Musters in einem Text überprüft, bis das Muster mit dem Text übereinstimmt oder das Ende des Texts gekommen ist. Das komplette Muster wird also beim Vergleich des Texts um eine Position nach vorn gezählt. Dies ist ein Brute-Force-Algorithmus (oder auch grober Algorithmus oder naiver Algorithmus). Hier das simple Beispiel:
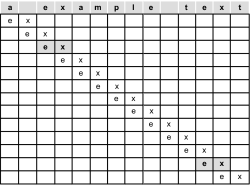
Hier klicken, um das Bild zu Vergrößern
Abbildung 24.30
Ablauf des Brute-Force-Algorithmus
Jetzt der Quellcode zu diesem einfachen String-Matching-Algorithmus:
/* bruteforce.c */
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define LEN 255
#define MAX_DAT 10
#define MAX_LINE 4096
#define LINE "---------------------------------------\n"
struct datei{
char name[LEN]; /* Name der Datei */
int gefunden; /* Anzahl gefunden */
};
typedef struct datei DATEI;
/* int i = der Textzählerstand
* int j = der Musterzählerstand */
int BruteForce(char *muster, char *text) {
int i = 0, j, cnt = 0;
int m=strlen(muster); /* Länge Muster */
int n=strlen(text); /* Länge Text */
while (i<=n-m) { /* Solange i kleiner als n-m zum Ende */
/* Solang Muster und Text gleich j++ */
for(j=0; j<m && muster[j]==text[i+j]; j++);
if(j==m) { /* Ist die Länge von j gleich der vom Muster? */
printf("Pos. %3d, ",i);
cnt++;
}
i++; /* Im Text eine Position weiter */
}
return cnt;
}
int main(int argc, char **argv) {
DATEI suche[MAX_DAT];
char suchstring[LEN];
char read_line[MAX_LINE];
FILE *f;
int i, j , ret, zeile;
if(argc < 3) {
fprintf(stderr, "Verwendung: %s suchstring datei1"
" <datei2> <datei%d>\n",argv[0],MAX_DAT);
return EXIT_FAILURE;
}
strncpy(suchstring, argv[1], LEN);
/* Kommandozeilen-Argumente auswerten */
for(i=2,j=0; j < MAX_DAT && i < argc; i++,j++) {
strncpy(suche[j].name, argv[i], LEN);
suche[j].gefunden = 0;
}
for(i = 0; i < argc-2; i++) {
f = fopen(suche[i].name, "r");
if(f == NULL) {
perror(NULL);
continue;
}
zeile = 0;
printf("\nDatei \"%s\": \n",suche[i].name);
while( fgets(read_line, MAX_LINE, f) != NULL) {
zeile++;
ret = BruteForce(suchstring, read_line);
if(ret != 0) {
suche[i].gefunden+=ret;
printf(" in Zeile %d\n",zeile);
ret = 0;
}
}
printf("Suchergebnisse in \"%s\": %d\n",
suche[i].name, suche[i].gefunden);
printf(LINE);
fclose(f);
}
return EXIT_SUCCESS;
}
Um als Beispiel den Suchstring "ex" und als Muster "a example text" zu verwenden: Die innere for-Schleife wird dabei nur dreimal inkrementiert, und zwar bei jedem Vorkommen des Buchstabens 'e'. Zweimal wird davon ein Ergebnis gefunden. Die Laufzeit des Algorithmus ist natürlich abhängig vom Suchmuster, aber im Durchschnitt hat der Brute-Force-Algorithmus immer ein lineares Zeitverhalten.
24.6.2 Der Algorithmus von Knuth/Morris/Pratt (KMP)
Der Nachteil des Brute-Force-Algorithmus ist der, dass dieser stur Zeichen für Zeichen, Position um Position vergleicht. Die Programmierer Knuth, Morris und Pratt, nach denen dieser Algorithmus auch benannt ist, haben diesen Algorithmus verbessert (verfeinert). Sie hatten die Idee, die Fehlvergleiche (so genanntes Missmatch) in den weiteren Algorithmus mit einzubeziehen. Als Beispiel sei diese Textfolge gegeben (text):
lu lalalala lule lulalalas
Der Suchstring (suchmuster) lautet alalas. Der Vorgang beginnt wie beim Brute-Force-Algorithmus:
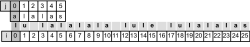
Hier klicken, um das Bild zu Vergrößern
Abbildung 24.31
Auf der Suche nach dem Suchstring »alalas« Start
Hier haben Sie zwischen text[i] und suchmuster[j] keine Übereinstimmung. Daher kann suchmuster um eine Position weitergeschoben werden:

Hier klicken, um das Bild zu Vergrößern
Abbildung 24.32
Keine Übereinstimmung Suchstring eine Postion weiter
Dies wird so lange wiederholt, bis zwei gleiche Zeichen aufeinander treffen:

Hier klicken, um das Bild zu Vergrößern
Abbildung 24.33
Erstes Zeichen stimmt überein
Solange text[i] jetzt gleich mit suchmuster[j] ist, werden i und j inkrementiert:
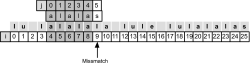
Hier klicken, um das Bild zu Vergrößern
Abbildung 24.34
Nach fünf Zeichen tritt ein Fehlvergleich auf
An Position text[9] und suchmuster[5] tritt hier eine Ungleichheit auf. Beim Brute-Force-Algorithmus würde jetzt das Muster wieder um eine Position nach vorn gesetzt werden. Und genau hier greift der Algorithmus von Knuth, Morris und Pratt ein. Die kleinstmögliche Verschiebung, bei der »alalas« sich mit sich selbst deckt, ist um zwei Stellen:
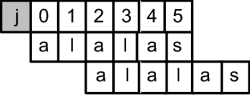
Hier klicken, um das Bild zu Vergrößern
Abbildung 24.35
Kleinstmögliche Verschiebung des Suchstrings selbst
Im nächsten Schritt werden dabei auch zwei Stellen weitergeschoben, da Sie ja nun wissen, dass sich der Anfang nicht überlappt. Genauer gesagt, Sie wissen es jetzt, weil ich es Ihnen gesagt habe, aber nicht wie dies programmtechnisch geschieht. Hierfür ist eine Vorlaufphase erforderlich. Aber dazu gleich mehr.

Hier klicken, um das Bild zu Vergrößern
Abbildung 24.36
Verschiebung um zwei Stellen anstatt um eine
In der Theorie hört sich das alles natürlich recht interessant an. Aber es in die Praxis umzusetzen, ist wesentlich komplizierter. Wie realisieren Sie eine kleinstmögliche Verschiebung um den Suchstring (suchmuster) selbst?
Da die Berechnung einer solchen Verschiebung nicht vom Text abhängig ist, in dem die Suche stattfindet, sondern nur vom Suchtext (suchmuster), kann sie schon vor der eigentlichen Suche erstellt werden. Es wird dabei von einer Vorlaufphase (Preprocessing) gesprochen. Hier der Algorithmus, welcher eine Sprungtabelle aus dem Suchstring selbst für den eigentlichen Suchalgorithmus erstellt.
void init_next(char *suchmuster, int m) {
int i, j;
i = 0;
j = next[0] = 1;
/* Solange i kleiner als der Suchstring ist */
while (i < m) {
while (j > 1 && suchmuster[i] != suchmuster[j])
j = next[j];
i++;
j++;
if (suchmuster[i] == suchmuster[j])
next[i] = next[j];
else
next[i] = j;
}
}
Um nochmals zum Szenario zu kommen: Sie verwenden gerade einen Brute-Force-Algorithmus und vergleichen einzelne Zeichen. Findet jetzt ein Missmatch (suchmuster!=text) statt, wird in den bisher gefundenen und übereinstimmenden Zeichen von hinten ein String mit maximaler (L) Länge gesucht, der zugleich Anfang eines weiteren Strings ist. Danach wird das Zeichen mit L+1 (=next[j]) und dem i-ten Zeichen im Text verglichen. Zwei Möglichkeiten gibt es dafür:

|
Das Zeichen next[j] des Suchstrings stimmt nicht mit dem i-ten Zeichen des Texts überein. Somit wird entweder ganz normal wie beim Brute-Force-Algorithmus fortgefahren, bis der ganze String gefunden wurde oder erneut ein Missmatch auftritt. In diesem Fall wird genauso fortgefahren wie beim ersten Missmatch. |
|
|
Das Zeichen next[j] des Suchstrings stimmt nicht mit dem i-ten Zeichen des Texts überein. next[j] wird somit um den Wert 1 reduziert, und der Vergleich geht weiter. Tritt wieder ein Missmatch auf, wird next[j] dekrementiert, bis das erste Zeichen des Suchstrings erreicht wurde. In diesem Fall wird i inkrementiert und das Ganze beginnt von vorne. |
Mit next[i] = j stellen Sie sicher, dass j1 die Länge des größten Endstücks, aber auch das Anfangsstück des Suchstrings ist. Ist suchmuster[i] gleich suchmuster[j], wird mit next[++i]=++j der Wert zugewiesen, da das next-Array immer das nächste Zeichen beinhaltet. Ist dies nicht der Fall, wird der Anfangsteil und das längste Endteil mit dem Muster verglichen, bis es zu einem positiven Vergleich zwischen muster[i] und muster[j] kommt.
Nun noch der eigentliche Algorithmus mit dem Suchstring und dem Textbeispiel, welches eben verwendet wurde (alalas).
/* kmp.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX 4096
void init_next(char *, int);
void kmpSearch(char *, char *);
int next[MAX];
/* i = Position im Text */
/* j = Position im Muster */
void kmpSearch(char *muster, char *text) {
int i=0, j=0;
int m=strlen(muster); /* Länge Muster */
int n=strlen(text); /* Länge Text */
init_next(muster, m); /* Tabelle für next berechnen */
while (i<n) { /*Solange wir nicht am Ende vom Text sind*/
while (j>=0 && text[i]!=muster[j])j=next[j];
i++; j++;
if (j==m) {
printf("Gefunden an Pos. %d\n", i-j);
j = next[j];
}
}
}
void init_next(char *muster, int m) {
int i, j;
i = 0;
j = next[0] = 1;
/* Solange i kleiner als der Suchstring ist */
while (i < m) {
while (j > 1 && muster[i] != muster[j])
j = next[j];
i++;
j++;
(muster[i] == muster[j]) ? (next[i]=next[j]) : (next[i]=j);
}
}
int main(void) {
kmpSearch("alalas", "lu lalalala lule lulalalas");
return EXIT_SUCCESS;
}
Das vollständige Listing des »Brute-Force-Algorithmus« umgeschrieben auf das Programmbeispiel:
/* kmpsearch.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define LEN 255
#define MAX_DAT 10
#define MAX_LINE 4096
#define MAX 255
#define LINE "_______________________________________\n"
struct datei{
char name[LEN]; /* Name der Datei */
int gefunden; /* Anzahl gefunden */
};
typedef struct datei DATEI;
int next[MAX];
int kmp_Search(char *, char *);
void init_next(char *, int);
int kmp_Search(char *muster, char *text) {
int i=0, j=0, cnt=0;
int m=strlen(muster); /* Länge Muster */
int n=strlen(text); /* Länge Text */
init_next(muster, m); /* Tabelle für next berechnen */
while (i<n) { /* Solange wir nicht am Ende vom Text sind */
while (j>=0 && text[i]!=muster[j])j=next[j];
i++; j++;
if (j==m) {
printf("Gefunden an Pos. %d\n", i-j);
cnt++;
j=next[j];
}
}
return cnt;
}
void init_next(char *muster, int m) {
int i, j;
i = 0;
j = next[0] = 1;
/* Solange i kleiner als der Suchstring ist */
while (i < m) {
while (j > 1 && muster[i] != muster[j])
j = next[j];
i++;
j++;
(muster[i]==muster[j]) ? (next[i]=next[j]) : (next[i]=j);
}
}
int main(int argc, char **argv) {
DATEI suche[MAX_DAT];
char suchstring[LEN];
char read_line[MAX_LINE];
FILE *f;
int i, j , ret, zeile;
if(argc < 3) {
fprintf(stderr, "Verwendung: %s suchstring datei1 "
"<datei2> ... <datei%d>\n",argv[0],MAX_DAT);
return EXIT_FAILURE;
}
strncpy(suchstring, argv[1], LEN);
/* Kommandozeilen-Argumente auswerten */
for(i=2,j=0; j < MAX_DAT && i < argc; i++,j++) {
strncpy(suche[j].name, argv[i], LEN);
suche[j].gefunden = 0;
}
for(i = 0; i < argc-2; i++) {
f = fopen(suche[i].name, "r");
if(f == NULL) {
perror(NULL);
continue;
}
zeile = 0;
printf("\nDatei \"%s\": \n",suche[i].name);
while( fgets(read_line, MAX_LINE, f) != NULL) {
zeile++;
ret = kmp_Search(suchstring, read_line);
if(ret != 0) {
suche[i].gefunden+=ret;
printf(" in Zeile %d\n",zeile);
ret=0;
}
}
printf("Suchergebnisse in \"%s\": %d\n",
suche[i].name, suche[i].gefunden);
printf(LINE);
fclose(f);
}
return EXIT_SUCCESS;
}
Der eine oder andere wird mir jetzt entgegnen, dass Kapitel sei viel zu schwer für ein Einsteiger-Buch. Im Prinzip muss ich dem zustimmen. Allerdings möchte ich zum Knuth-Morris-Pratt-Algorithmus sagen, dass hierbei versucht wurde, diesen Algorithmus möglichst einfach zu erklären, ohne viele technische Begriffe aus der Welt der Mathematik und Informatik. Für Hardcore-Programmierer, die mehr Details benötigen, sei auf die weiterführenden Links und die Literatur im Anhang verwiesen.
Außerdem soll nicht unerwähnt bleiben, dass der Knuth-Morris-Pratt-Algorithmus immer noch einer der leichteren String-Matching-Algorithmen ist.
24.6.3 Weitere String-Matching-Algorithmen
Boyer Moore
Der Boyer-Moore-Algorithmus ähnelt dem Brute-Force und ist eine weitere Verbesserung gegenüber dem Knuth-Morris-Pratt-Algorithmus. Auch mit diesem Algorithmus werden Verschiebungen vorgenommen, und nicht mehr infrage kommende Verschiebungen werden übersprungen. Hierfür sind gleich zwei Vorlaufphasen (Preprocessing) notwendig. Genauer gesagt zwei Heuristiken, welche die Schrittweite bei der nächsten Verschiebung vorschlagen:
|
|
Schlechter-Buchstabe-Heuristik Dabei wird untersucht, ob ein Zeichen im Text, welches nicht mehr mit dem Pattern übereinstimmt, an einer anderen Stelle im Pattern vorkommt, und dann wird eine entsprechende Schrittweite vorgeschlagen. |
|
|
Gutes-Suffix-Heuristik Dabei wird untersucht, ob das Suffix des Patterns, welches mit dem Text übereinstimmt, an einer anderen Stelle vorkommt, und dann wird auch hier eine entsprechende Schrittweite vorgeschlagen. |
Karp Rabin
Jeder mögliche String des Musters wird in eine Hash-Tabelle eingetragen. Dafür wird eine spezielle Hash-Funktion geschrieben, welche die Eigenschaft hat, dass sie bei dem Text für Startindex i effizient aus dem vorhergehenden Hashwert (Startindex = i-1) berechnet werden kann. Sind dabei zwei Hashwerte gleich, wird wie beim Brute-Force-Algorithmus vorgegangen. Dies funktioniert nach folgendem Pseudocode:
hash_pattern = hash_wert_des_pattern
hash_text = hash_wert_der_ersten_m_Zeichen_im_text
do {
if(hash_pattern == hash_text)
bruteforce_vergleich
hash_text = hash_wert_der_nächsten_m_Zeichen_des_Textes
} while(Text_zu_Ende || bruteforce == wahr);
|





 bestellen
bestellen




