

|
|
|
Das Interface ObjectOutput erweitert die Klasse DataOutput um das Schreiben von Objekten. Mit DataOutput können Primitive geschrieben werden, und dieses Interface definiert die Methoden: write(byte[]), write(byte[], int, int), write(int), writeBoolean(boolean), writeByte(int), writeBytes(String), writeChar(int), writeChars(String), writeDouble(double), writeFloat(float), writeInt(int), writeLong(long), writeShort(int) und writeUTF(String). Nun erweitert ObjectOutput die Klasse DataOutput, um Methoden, Attribute, Strings und Objekte zu speichern. Natürlich können wir wegen der Vererbung in ObjectOutput wieder primitive Daten speichern. In der folgenden Aufzählung sind die Methoden aufgeführt. Allerdings finden sich unter den Funktionen keine, die Objekte vom Typ Class schreiben. Hier müssen ebenso Sonderbehandlungen vorgenommen werden wie bei Strings oder Arrays.
Alle diese Methoden können eine IOException genau dann werfen, wenn Fehler beim Auslesen der Attribute oder beim grundlegenden Schreiben auf dem Datei- beziehungsweise Netzwerksystem auftreten. Objekte über das Netzwerk schickenEs ist natürlich wieder feines OOD, dass es der Methode writeObject() egal ist, wohin das Objekt geschoben wird. Dazu wird ja einfach dem Konstruktor von ObjectOutputStream ein OutputStream übergeben, und writeObject() delegiert dann das Senden der entsprechenden Einträge an die passenden Methoden der Output-Klasse. Im oberen Beispiel benutzten wir ein FileOutputStream. Es sind aber auch noch eine ganze Menge anderer Klassen, die OutputStream erweitern. So können die Objekte auch in einer Datenbank abgelegt werden beziehungsweise über das Netzwerk verschickt werden. Wie dies funktioniert, zeigen die nächsten Zeilen: Socket s = new Socket( "host", port ); OutputStream os = s.getOutputStream(); ObjectOutputStream oos = new ObjectOutputStream( os ); oos.writeObject( object ); Über s.getOutputStream() gelangen wir an den Datenstrom. Dann sieht alles wie bekannt aus. Da wir allerdings auf der Empfängerseite noch ein Protokoll ausmachen müssen, werden wir diesen Weg der Objektversendung nicht weiterverfolgen und uns später vielmehr auf eine Technik verlassen, die sich RMI nennt. Objekte in ein Bytefeld schreibenDie Klassen ObjectOutputStream und ByteArrayOutputStream sind zusammen zwei gute Partner, wenn es darum geht, eine Repräsentation eines Objekts im Speicher zu erzeugen und die Größe eines Objekts herauszufinden. Object o = ...; ByteArrayOutputStream baos = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream( baos ); oos.writeObject( o ); oos.close(); byte array[] = baos.toByteArray(); Nun steht das Objekt im Bytefeld. Wenn wir die Größe erfragen wollten, müssten wir das Attribut length des Felds auslesen. Dies gibt eine ganz grobe Vorstellung über den Platzbedarf im Speicher.  12.14.2 Objekte über die Standard-Serialisierung lesen
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
interface java.io. ObjectInput extends DataInput |
| Object readObject() throws ClassNotFoundException, IOException Liest ein Object und gibt es zurück. Die Klasse, die readObject() implementiert, muss natürlich wissen, wie es gelesen wird. ClassNotFoundException wird dann ausgelöst, wenn das Objekt zu einer Klasse gehört, die nicht gefunden werden kann. |
| int read() throws IOException Liest ein Byte aus dem Datenstrom. Dieses ist 1, wenn das Ende erreicht ist. |
| int read( byte b[] ) throws IOException Liest ein Array in den Puffer. Auch hier zeigt 1 das Ende an. |
| int read( byte b[], int off, int len ) throws IOException Liest in ein Array von Bytes in den Puffer b an der Stelle off genau len Bytes. |
| long skip( long n ) throws IOException Überspringt n Bytes im Eingabestrom. Die Anzahl der tatsächlich übersprungenen Zeichen wird zurückgegeben. |
| int available() throws IOException Gibt die Anzahl der Zeichen zurück, die ohne Blockade gelesen werden können. |
| void close() throws IOException Schließt den Eingabestrom. |
Bisher haben wir immer angenommen, dass eine Klasse weiß, wie sie geschrieben wird. Das funktioniert wie selbstverständlich bei vielen vordefinierten Klassen, und so müssen wir uns bei writeObject(new Date()) keine Gedanken darüber machen, wie sich das Datum schreibt. Jedoch sind nicht alle Objekte serialisierbar. Zu den Klassen, die sich nicht serialisieren lassen, gehören zum Beispiel Thread, Socket oder viele Klassen aus dem java.io-Paket. Das liegt daran, dass nicht klar ist, wie denn zum Beispiel ein Wiederaufbau aussehen sollte. Wenn ein Thread geschrieben wird, soll er dann beim Einlesen wieder sofort laufen und dort weitermachen, wo er aufgehört hat?
Damit Objekte serialisiert werden können, müssen die Klasse die Schnittstelle Serializable implementieren. Diese Schnittstelle enthält keine Methoden und ist nur eine Markierungsschnittstelle. Implementiert eine Klasse diese Schnittstelle nicht, folgt beim Serialisierungsversuch eine NotSerializableException. Eine Klasse wie java.util.Date implementiert somit Serializable, Thread jedoch nicht. Der Serialisierer lässt damit alle Klassen »durch«, die instanceof Serializable sind. Daraus folgt, dass alle Unterklassen einer Klasse, die serialisierbar ist, selbst auch serialisierbar sind. So implementiert java.lang.Number die Basisklasse der Wrapper-Klassen die Schnittstelle Serializable und die konkreten Wrapper-Klassen wie Integer, BigDecimal sind so auch serialisierbar.
Ob Objekte, die sensible Daten tragen, serialisierbar sein sollen, ist gut zu überlegen. Denn werden die Zustände serialisiert und es werden auch private Attribute serialisiert, an denen so erst einmal nicht heranzukommen ist öffnet sich die Kapselung. Aus dem Datenstrom lassen sich die internen Belegungen ablesen und auch manipulieren.
| Hinweis Feld-Objekte sind standardmäßig serialisierbar sie implementieren versteckt die Schnittstelle Serializable. |
Wir wollen nun eine Klasse TestSer schreib- und lesefähig machen. Dazu benötigen wir folgendes Gerüst:
Listing 12.34 TestSer.java
import java.io.Serializable; public class TestSer implements Serializable { int a; double d; static int u; }
Erzeugen wir ein TestSer-Objekt, nennen wir es ts und rufen writeObject(ts) auf, so schiebt es all seine Variablen (hier a und d) in den Datenstrom.
Statische Variablen werden mit dem Standardserialisierungsmechanismus nicht gesichert. Dies kann auch nicht sein, denn verschiedene Objekte teilen sich ja eine statische Variable. Wenn zwei Objekte wieder deserialisiert werden, könnte es sonst passieren, dass beide unterschiedliche Werte haben. Was sollte dann passieren?
Es gibt eine Reihe von Objekttypen, die sich nicht serialisieren lassen technisch gesprochen implementieren diese Klassen die Schnittstelle Serializable nicht. Aber warum sollte es überhaupt Objekte geben, die nicht persistent gemacht werden sollen? Ein Punkt ist die Sicherheit. Ein Objekt, welches etwa Passwörter speichert, soll nicht einfach geschrieben werden. Da reicht es nicht, dass die Attribute privat sind, denn auch sie werden geschrieben. Der andere Punkt ist, dass sich nicht alle Zustände beim Deserialisieren wieder herstellen lassen. Was ist, wenn ein FileInputStream serialisiert wird. Soll dann bei der Deserialisierung eine Datei geöffnet werden? Was ist, wenn die Datei nicht da ist? Was ist mit einem Socket oder einem ServerSocket? Da all diese Fragen ungeklärt sind, ist es das Einfachste, diese Klasse nicht die Schnittstelle Serializable implementieren zu lassen.
Doch wenn das so ist, haben wir spätestens dann ein Problem, wenn ein Objekt geschrieben wird, das intern auf ein nicht serialisierbares Objekt verweist etwa auf einen Thread.
Hier klicken, um das Bild zu Vergrößern
Beispiel Die Serialisierung der folgenden Klasse bringt einen Laufzeitfehler ein:
public class SerializeTransient { public static void main( String args[] ) throws Exception { ByteArrayOutputStream bytearray = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream( bytearray ); class NotTransientNotSerializable implements Serializable { Thread t = new Thread(); String s = "Fremde sind Freunde, die man nur noch nicht kennengelernt hat."; } oos.writeObject( new NotTransientNotSerializable() ); oos.close(); System.out.println( bytearray.toString() ); } } |
Der Fehler wird eine NotSerializableException sein:
java.io.NotSerializableException: java.lang.Thread at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1054) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1330) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1302) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1245) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1052) at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:278) at SerializeTransient.main(SerializeTransient.java:18) Exception in thread "main"
Die Begründung dafür ist einfach: Ein Thread kann nicht serialisiert werden. Falls wir aber ein Objekt vom Typ NotTransientNotSerializable ohne Thread serialisieren wollen, müssen wir dem Serialisierungsmechanismus mitteilen: »Nimm so weit alle Objekte, aber den Thread nicht!« Dazu existiert in Java ein spezielles Schlüsselwort: transient. Es markiert alle Attribute, die nicht persistent sein sollen. Damit lassen wir die nicht serialisierbaren Kandidaten also außen vor und speichern alles das, was geht.
Um das Beispiel damit zu Ende zu bringen, setzen wir den Modifizierer transient vor den Variablentyp, und das Beispiel ist ablauffähig.
transient Thread t = new Thread();
Es kann nun passieren, dass es beim Serialisieren nicht ausreicht, die normalen Attribute zu sichern. Für diesen Fall müssen spezielle Methoden implementiert werden. Beide müssen die nachstehenden Signaturen besitzen:
private synchronized void writeObject( java.io.ObjectOutputStream s ) throws IOException
und
private synchronized void readObject( java.io.ObjectInputStream s ) throws IOException, ClassNotFoundException
Die Methode writeObject() ist für das Schreiben verantwortlich. Ist der Rumpf leer, so gelangen keine Informationen in den Strom und das Objekt wird folglich nicht gesichert.
Mit diesen Funktionen können wir also die Serialisierung selbst in die Hand nehmen. Wir können Attribute so speichern, wie wir es für sinnvoll halten, und es lässt sich eine Kompatibilität erzwingen. Eine kleine Versionsnummer im Datenstrom könnte eine Verzweigung provozieren, in der die Daten der Version 1 oder andere Daten der Version 2 gelesen werden. Auch können auf diese Weise statische Attribute in den Datenstrom kommen.
Beim Lesen können komplette Objekte wieder aufgebaut werden, und es lassen sich zum Beispiel nicht transiente Objekte wieder beleben. Stellen wir uns einen Thread vor, dessen Zustände beim Schreiben persistent gemacht werden, und beim Lesen wird ein Thread-Objekt wieder erzeugt und zum Leben erweckt.
Wird eine Klasse serialisiert, so wird auch automatisch die Oberklasse serialisiert. Dabei gilt, dass wie beim Konstruktur erst die Attribute der Oberklasse in den Datenstrom geschrieben werden und anschließend die Attribute der Unterklasse. Insbesondere heißt dass, das die Unterklasse nicht noch einmal die Attribute der Oberklasse speichern sollte. Das folgende Programm zeigt den Effekt:
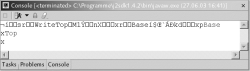
Listing 12.35 WriteTop.java
import java.io.*; class Base implements Serializable { private void writeObject( ObjectOutputStream oos ) { System.err.println( "Base" ); } } public class WriteTop extends Base implements Serializable { public static void main( String args[] ) throws IOException { ObjectOutputStream oos = new ObjectOutputStream( System.out ); oos.writeObject( new WriteTop() ); } private void writeObject( ObjectOutputStream oos ) { System.err.println( "Top" ); } }
In der Ausgabe von Eclipse ist anderfarbig die Ausgabe »Base« und »Top« zu erkennen.
Hier klicken, um das Bild zu Vergrößern
Die Funktionen read/writeObject() sind Alles-oder-nichts-Funktionen. Erkennt der Serialisierer, dass die Schnittstelle Serializable implementiert wird, fragt er die Klasse, ob sie die Methoden implementiert. Macht sie es nicht, so beginnt bei der Serialisierung der Serialisierungsmechanismus eigenständig die Attribute auszulesen und in den Datenstrom zu schreiben. Gibt es die read/writeObject()-Methoden, so wird der Serialisierer diese aufrufen und nicht selbst die Objekte nach den Werten fragen oder die Objekte mit Werten füllen.
Doch die Arbeit des Serialisierers ist eine große Hilfe. Falls viele Attribute zu speichern sind, fällt viel lästige Arbeit beim Programmieren an, denn für jedes zu speichernde Attribut ist eine eigene write-Funktion nötig und beim Lesen eine entsprechende read-Funktion. Aus diesem Dilemma gibt es einen Ausweg, denn in den read/writeObject()-Methoden kann der Serialisierer auch nachträglich dazu verpflichtet werden, die nicht transienten Attribute zu lesen oder zu schreiben. Die privaten Funktionen readObject() und writeObject() bekommen als Parameter ein ObjectInputStream und ein ObjectOutputStream, die über die entsprechende Funktion verfügen.
| Hinweis Es ist gar nicht so abwegig, nur eine readObject(), aber keine writeObject()-Funktion zu implementieren. In readObject() lässt ein defaultReadObject() alle Eigenschaften initialisieren und danach noch Initialisierungsarbeit ähnlich einem Konstruktor durchführen. Dazu zählt etwa Initialisierung von transienten Attributen, Registrierung von Listenern und Weiteres. |
Die Klasse ObjectOutputStream erweitert java.io.OutputStream unter anderem um die Methode defaultWriteObject(). Sie speichert die Attribute einer Klasse.
class java.io. ObjectOutputStream extends OutputStream implements ObjectOutput, ObjectStreamConstants |
| public final void defaultWriteObject() throws IOException Schreibt alle nicht statischen und nicht transienten Attribute in den Datenstrom. Die Methode kann nur innerhalb einer privaten writeObject()-Funktion aufgerufen werden; andernfalls erhalten wir eine NotActiveException. |
Das Gleiche gilt auch für die Funktion defaultReadObject() in der Klasse ObjectInputStream.
| Beispiel Eine Klasse definiert zwei Attribute: freundin und alter. Da Frauen über ihr Alter nicht sprechen, soll alter nicht serialisert werden; es ist transient. Wir implementieren eigene read/writeObject()-Funktionen, die den Standardserialisierer bemühen, sonst aber nichts Interessantes machen.
Listing 12.36 DefaultReadWriteObject.java import java.io.*; public class DefaultReadWriteObject implements Serializable { public String freundin = "Tatjana"; public transient int alter = 30; private void writeObject( ObjectOutputStream oos ) throws IOException { oos.defaultWriteObject(); // Schreibe freundin, aber nicht alter } |
private void readObject( ObjectInputStream ois ) throws IOException { try { ois.defaultReadObject(); // Lese freundin, aber nicht das alter } catch ( ClassNotFoundException e ) { throw new IOException( "Klasse nicht gefunden. HILFE!!" ); } } } |
Klassen können die clone()-Methode von Object überschreiben und so eine Kopie der Werte liefern. Die Standardimplementierung ist jedoch so angelegt, dass diese Kopie flach ist. Das bedeutet, Referenzen auf Objekte, die von dem zu klonenden Objekt ausgehen, werden beibehalten und diese Objekte nicht extra kopiert. Als Beispiel kann die einfache Datenstruktur eines Felds genügen, das auf Vector-Objekte verweist. Ein Klon dieses Felds ist lediglich ein zweites Feld, dessen Elemente auf die gleichen Vektoren zeigen. Eine Änderung wird also beiden Feldern bewusst.
Möchten wir das Verhalten ändern und eine tiefe Kopie anfertigen, so haben wir mit einem kleinen Trick damit keine Mühe. Die Idee ist, dass wir das zu klonende Objekt einfach serialisieren und dann wieder auspacken. Die zu klonenden Objekte müssen dann nur das Serializable-Interface implementieren.
Listing 12.37 Dolly.java, deepCopy()
public static Object deepCopy( Object o ) throws Exception { ByteArrayOutputStream baos = new ByteArrayOutputStream(); new ObjectOutputStream( baos ).writeObject( o ); ByteArrayInputStream bais = new ByteArrayInputStream( baos.toByteArray() ); return new ObjectInputStream(bais).readObject(); }
Das Einzige, was wir zum Gelingen der Methode deepCopy() machen müssen, ist, das Objekt in einem Bytefeld zu serialisieren, es wieder auszulesen und zu einem Objekt zu konvertieren. Den Einsatz eines ByteArrayOutputStream haben wir schon gesehen, als wir die Länge eines Objekts herausfinden wollten. Nur fügen wir nun das Feld wieder zu einem ByteArrayInputStream hinzu, aus dessen Daten dann ObjectInputStream wieder das Objekt rekreieren kann.
Überzeugen wir uns anhand eines kleinen Programms, dass die tiefe Kopie tatsächlich etwas anderes als ein clone() ist.
Listing 12.38 Dolly.java, main()
public static void main( String args[] ) throws Exception { Map<String,String> map = new HashMap<String,String>(); map.put( "Cul de Paris", "hinten unter dem Kleid getragenes Gestell oder Polster" ); LinkedList<Map> l1 = new LinkedList<Map>(); l1.add( map ); List l2 = (List) l1.clone(); List l3 = (List) deepCopy( l1 ); map.clear(); System.out.println( l1 ); // [{}] System.out.println( l2 ); // [{}] System.out.println( l3 ); // [{Cul de Paris=hinten unter dem Kleid ...}] }
Zunächst erstellen wir eine Map, die wir anschließend in eine Liste packen. Die Map enthält ein Pärchen. Klonen wir mit clone() die Liste, so wird zwar die Liste selbst kopiert, aber nicht die Map. Die tiefe Kopie kopiert neben der Liste auch gleich die Map mit. Das sehen wir dann, wenn wir den Eintrag aus der Map löschen. Dann ergibt l1 genauso wie l2 eine leere Liste, da l2 nur die Verweise auf die Map gespeichert hat, die dann aber geleert ist. Anders ist dies bei l3, der tiefen Kopie; hier ist das Paar noch vorhandenAn diesem Beispiel sehen wir, wie wunderbar die Stream-Klassen zusammenarbeiten. Einzige Voraussetzung zum Gelingen ist die Implementierung der Schnittstelle Serializable. Da aber die zu klonenden Klassen auch clone() implementieren müssen, gilt in der Regel, dass sie serialisierbar sind. Daher stehen in der implements-Zeile die Schnittstellen Clonable und Serializable direkt nebeneinander.
Die erste Version einer Klassenbibliothek ist in der Regel nicht vollständig und nicht beendet. Es kann gut sein, dass Attribute und Methoden nachträglich in die Klasse eingefügt, gelöscht oder modifiziert werden. Das bedeutet aber gleichzeitig, dass die Serialisierung zu einem Problem werden kann. Denn ändert sich der Typ einer Variablen oder kommen Variablen hinzu, dann ist eine gespeicherte Objektserialisierung nicht mehr gültig.
Bei der Serialisierung wird in Java nicht nur der Objektinhalt geschrieben, sondern zusätzlich noch eine eindeutige Kennung der Klasse, die UID. Die UID ist ein Hashcode aus Namen, Attributen, Parametern, Sichtbarkeit und so weiter. Sie wird als long wie ein Attribut gespeichert. Ändert sich der Aufbau einer Klasse, ändert sich der Hashcode und damit die UID. Klassen mit unterschiedlicher UID sind nicht kompatibel. Erkennt der Lesemechanismus in einem Datenstrom eine UID, die nicht zu der Klasse passt, wird eine InvalidClassException ausgelöst. Das bedeutet, dass schon ein einfaches Zufügen von Attributen zu einem Fehler führt.
Wir wollen uns dies einmal an einer einfachen Klasse ansehen. Wir entwickeln eine Klasse SerMe mit einem einfachen Ganzzahlattribut. Später fügen wir dann eine Fließkommazahl hinzu.
Listing 12.39 InvalidSer.java, Teil 1
class SerMe implements Serializable { int i; // double d; // float i; }
Dann benötigen wir noch das Hauptprogramm. Wir bilden ein Exemplar von SerMe und schreiben es in eine Datei. Ohne Änderungen können wir es direkt wieder deserialisieren. Ändern wir jedoch die Klassendefinition, führt dies zu einem Fehler.
Listing 12.40 InvalidSer.java, Teil 2
import java.io.*; public class InvalidSer { public static void main( String args[] ) throws Exception { das String filename = "c:/test.ser"; // Teil 1: Schreiben ObjectOutputStream oo = new ObjectOutputStream( new FileOutputStream( filename ) ); oo.writeObject( new SerMe() ); oo.close(); // Teil 2: Klasse SerMe ändern und zu lesen versuchen ObjectInputStream oi = new ObjectInputStream( new FileInputStream( filename ) ); SerMe o = (SerMe) oi.readObject(); oi.close(); } }
Fügen wir der Klasse SerMe das Attribut double d zu oder ändern wir den Typ der Ganzzahlvariablen auf float, folgt eine lange Fehlerliste:
java.io.InvalidClassException: SerMe; Local class not compatible: stream classdesc serialVersionUID=9027745268614067035 local class serialVersionUID=-3271853622578609637 at java.io.ObjectStreamClass.validateLocalClass(ObjectStreamClass.java:523) at java.io.ObjectStreamClass.setClass(ObjectStreamClass.java:567) at ujava.io.ObjectInputStream.inputClassDescriptor(ObjectInputStream.java:936) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:366) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:236) at java.io.ObjectInputStream.inputObject(ObjectInputStream.java:1186) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:386) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:236) at InvalidSer.main(InvalidSer.java:28)
Aus dem oberen Fehlerauszug erkennen wir, dass der Serialisierungsmechanismus die SUID selbst berechnet. Das Attribut ist als statische, finale Variable mit dem Namen serialVersionUID in der Klasse abgelegt. Ändern sich die Klassenattribute, ist es günstig, eine eigene SUID einzutragen, denn der Mechanismus zum Deserialisieren kann dann etwas gutmütiger mit den Daten umgehen. Denn beim Einlesen gibt es Informationen, die nicht hinderlich sind. Wir sprechen in diesem Zusammenhang auch von Stream-kompatibel. Dazu gehören zwei Bereiche.
Befinden sich in der neuen Klasse Attribute, die im Datenstrom nicht benannt sind, so werden diese Attribute mit 0 oder null initialisiert.
Befinden sich im Datenstrom Attribute, die in der neuen Klasse nicht vorkommen, so werden sie einfach ignoriert.
Die SUID lässt sich mit einem kleinen Dienstprogramm serialver berechnen. Dadurch erreichen wir eine Stream-kompatible Serialisierung.
Beispiel Dies wollen wir für unsere Klasse SerMe mit dem Dienstprogramm testen:
$ serialver SerMe SerMe: static final long serialVersionUID = 9027745268614067035L; |
Diese letze Zeile können wir in unsere Klasse SerMe kopieren. Nehmen wir jetzt noch eine Fließkommazahl d hinzu, dann wird die InvalidClassException nicht mehr auftreten, da mit der Hinzunahme eines Attributs die Stream-Kompatibilität gewährleistet ist.
class SerMe implements Serializable { int i; double d; static final long serialVersionUID = 9027745268614067035L; }
Am Beispiel einer java.util.ArrayList lässt sich sehr schön beobachten, wie sich die Funktionen writeObject() und readObject() nutzen lassen. Eine ArrayList beinhaltet eine Reihe von Elementen. Zur Speicherung nutzt die Datenstruktur ein internes Feld. Das Feld kann größer als die Anzahl der Elemente sein, damit bei jedem add() nicht immer das Feld neu vergrößert werden muss. Nehmen wir an, die ArrayList würde eine Standardserialisierung nutzen. Was passiert? Dann könnte das Problem entstehen, dass bei nur einem Objektverweis in der Liste und einer internen Feldgröße von 1000 Elementen leider 999 null-Verweise gespeichert würden. Das wäre aber Verschwendung! Besser ist, eine angepasste Serialisierung zu verwenden.
Wir schauen uns einmal den Quellcode der Methoden aus dem Projekt GNU Classpath an:
private void writeObject(ObjectOutputStream s) throws IOException { // The size field. s.defaultWriteObject(); // We serialize unused list entries to preserve capacity. int len = data.length; s.writeInt(len); // it would be more efficient to just write "size" items, // this need readObject read "size" items too. for (int i = 0; i < size; i++) s.writeObject(data[i]); } private void readObject(ObjectInputStream s) throws IOException, ClassNotFoundException { // the `size field. s.defaultReadObject(); int capacity = s.readInt(); data = new Object[capacity]; for (int i = 0; i < size; i++) data[i] = s.readObject(); }
Der klassische Weg von einem Objekt zu einer persistenten Speicherung führt über den Serialisierungsmechanismus von Java über die Klassen ObjectOutputStream und ObjectInputStream. Die Serialisierung in Binärdaten ist aber nicht ohne Nachteile. Schwierig ist beispielsweise die Weiterverarbeitung von Nicht-Java-Programmen oder die nachträgliche Änderung ohne Einlesen und Wiederaufbauen der Objektverbunde. Wünschenswert ist daher eine Textrepräsentation. Diese hat nicht die oben genannten Nachteile. Insbesondere wenn der Text in einem XML-Format strukturiert ist, finden wir mittlerweile viele Programme, die die Weiterverarbeitung sichern.
Für die Serialisierung in XML gibt es eine ganze Reihe von Bibliotheken. Seit Java 1.4 ist die Serialisierung in XML integriert, doch kann der Mechanismus nur Klassen serialisieren, die nach der Beans-Spezifikation über setXXX() und getXXX()-Methoden verfügen und öffentlich sind, aber Serializable müssen sie nicht implementieren. Weitere XML-Serialisierer beziehungsweise Produkte zur Datenbindung sind:
| Commons Betwixt (http://jakarta.apache.org/commons/betwixt/) |
| XStream (http://xstream.codehaus.org/) |
| Castor (http://www.castor.org/) |
| Zeus (http://zeus.objectweb.org/, http://forge.objectweb.org/projects/zeus/) |
| Java Architecture for XML Binding: JAXB (http://java.sun.com/xml/jaxb/) |
Um in XML zu schreiben und von dort zu laden, werden die Klassen ObjectOutputStream und ObjectInputStream durch die Klassen XMLEncoder und XMLDecoder ersetzt.
Hier klicken, um das Bild zu Vergrößern
Die folgende Klasse ist unserem Programm SerializeAndDeserialize nachempfunden. Ersetzen müssen wir lediglich die Object-Streams. Die Klassen XMLEncoder und XMLDecoder liegen auch nicht in java.io, sondern unter dem Paket java.beans. Interessanterweise muss die Ausnahme ClassNotFoundException nicht mehr aufgefangen werden.
Listing 12.41 SerializeAndDeserializeXML.java
import java.io.*; import java.util.Date; import java.beans.*; public class SerializeAndDeserializeXML { public static void main( String args[] ) throws Exception { String filename = "datum.ser.xml"; // Serialize try { XMLEncoder o = new XMLEncoder( new FileOutputStream(filename) ); o.writeObject( "Today" ); o.writeObject( new Date() ); o.close(); } catch ( IOException e ) { } // Deserialize() try { XMLDecoder o = new XMLDecoder( new FileInputStream(filename) ); String string = (String) o.readObject(); Date date = (Date) o.readObject(); o.close(); System.out.println( string ); System.out.println( date ); } catch ( IOException e ) { } } }
Und so sehen wir nach dem Ablauf des Programms in der Datei datum.ser.xml Folgendes:
<?xml version="1.0" encoding="UTF-8"?> <java version="1.5.0" class="java.beans.XMLDecoder"> <string>Today</string> <object class="java.util.Date"> <long>1090573655328</long> </object> </java>
Bei eigenen Objekten muss immer bedacht sein, dass die XML-Serialisierer von Sun nur Beans schreibt. Eigene Klassen müssen daher immer ihre serialisierbaren Eigenschaften über getXXX()/setXXX()-Methoden bereitstellen.
| << zurück |
Copyright © Galileo Press GmbH 2004
Für Ihren privaten Gebrauch dürfen Sie die Online-Version natürlich ausdrucken. Ansonsten unterliegt das <openbook> denselben Bestimmungen, wie die gebundene Ausgabe: Das Werk einschließlich aller seiner Teile ist urheberrechtlich geschützt. Alle Rechte vorbehalten einschließlich der Vervielfältigung, Übersetzung, Mikroverfilmung sowie Einspeicherung und Verarbeitung in elektronischen Systemen.
