
|
Linux - Wegweiser zur Installation & Konfiguration, 3. Auflage
Online-Version
Copyright © 2000 by O'Reilly Verlag GmbH & Co.KG
Bitte denken Sie daran: Sie dürfen zwar die Online-Version
ausdrucken, aber diesen Druck nicht fotokopieren oder verkaufen.
Das Werk einschließlich aller seiner Teile ist urheberrechtlich
geschützt. Alle Rechte vorbehalten einschließlich der
Vervielfältigung, Übersetzung, Mikroverfilmung sowie
Einspeicherung und Verarbeitung in elektronischen Systemen.
Wünschen Sie mehr Informationen zu der gedruckten
Version des Buches Linux - Wegweiser zur Installation &
Konfiguration
oder wollen Sie es bestellen, dann klicken Sie bitte
hier.
|
Das World Wide Web
Das World Wide Web (WWW; weltweites Netz oder Gespinst; kurz: Web) ist relativ neu in der Informationshierarchie des Internet. Ziel dieses Projekts ist es, die vielen verschiedenen Dienste, die es im Internet gibt, zu einem einzigen weltweiten, multimedialen Hypertext-Raum zusammenzufassen. In diesem Abschnitt werden wir Ihnen zeigen, wie Sie sich mit Ihrem Linux-System in das WWW begeben. Wir demonstrieren auch, wie Sie Ihren eigenen WWW-Server konfigurieren und im Web Dokumente anbieten können.
Das Projekt World Wide Web wurde 1989 von Tim Berners-Lee am European Center for Particle Physics (CERN) ins Leben gerufen. Das Ziel war ursprünglich, der Gemeinde der Forscher in der Teilchenphysik den Zugriff auf vielfältige Informationen durch eine einzelne, homogene Schnittstelle zu ermöglichen.
Bevor das Web entstand, wurde jeder Typ von Informationen, der im Internet zu finden war, von einem einzigartigen Client/Server-Paar bereitgestellt. Wenn man beispielsweise per FTP Dateien übertragen wollte, benutzte man dazu den ftp-Client, der eine Verbindung zum ftpd-Dämon auf dem Server herstellte. Gopher (ein altes hierarchisches Dokumentsystem, das vor dem Erscheinen des Webs als ziemlich modern galt), Usenet-News, die finger-Informationen usw. erforderten alle einen besonderen Client. Die Unterschiede zwischen Betriebssystemen und Rechnerarchitekturen vervielfältigten das Problem - eigentlich sollten solche Details vor dem Benutzer verborgen werden, der Zugriff zu den Informationen sucht.
Das Web abstrahiert die vielen Informationstypen im Internet zu einem einzigen Typ. Man benutzt nur einen Web-»Client« - etwa Netscape Navigator oder Lynx - für den Zugriff auf das Web. Im Web werden Informationen in Form von Dokumenten dargestellt (auch »Seiten« genannt), wobei jedes Dokument Verweise (Links) auf andere Dokumente enthalten kann. Die Dokumente können auf einem beliebigen Rechner im Internet gespeichert sein, der für den Webzugang konfiguriert ist. Die Präsentation von Informationen in dieser Form bezeichnet man allgemein als »Hypertext« - dies ist ein sehr wichtiges Konzept, auf dem das gesamte Web basiert.
Ein Beispiel: Das »Linux Documentation Project« (LDP) verbreitet verschiedene Dokumente, die Linux betreffen, über das Web. Die »Leitseite« (Home-Page) des LDP, die auf http://www.linuxdoc.org
liegt, enthält Links zu einer Reihe von anderen Linux-bezogenen Seiten irgendwo auf der Welt. Abbildung 16-1 zeigt die Home-Page des LDP.
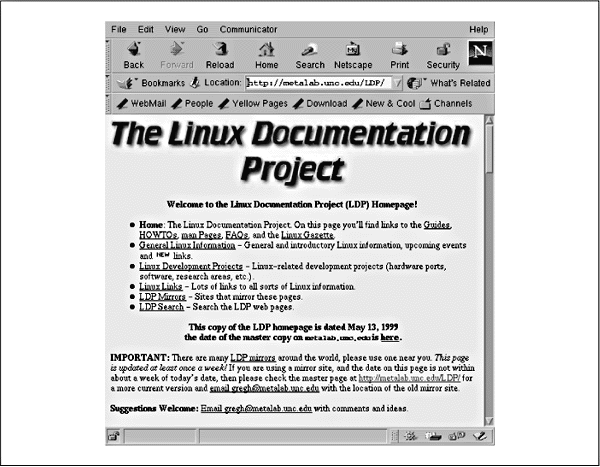
Abbildung 16-1: Die Home-Page des »Linux Documentation Project« (LDP) im WWW
Die hervorgehobenen Textstellen im Dokument sind Links. Wenn der Benutzer einen Link auswählt (zum Beispiel, indem er mit der Maus auf den Text klickt), wird das Dokument übertragen, auf das dieser Link verweist. Die Dokumente können auf praktisch jedem beliebigen System im Internet liegen; die tatsächlichen »Standorte« von Webdokumenten werden vor dem Benutzer verborgen.
Viele der Dokumente, die im Web angeboten werden, sind multimediale Hypertextseiten (siehe Abbildung 16-1). Diese Seiten können Verweise auf Grafiken, Sounddaten, MPEG-Videos, PostScript-Dokumente und einiges mehr enthalten. Diese Multimedia-Informationen werden mit dem »HyperText Transfer Protocol« (HTTP) übertragen. Das Web ist außerdem in der Lage, auf FTP- und Gopher-Dokumente, Usenet-News usw. zuzugreifen.
Wenn Sie beispielsweise via HTTP auf ein Dokument zugreifen, werden Sie wahrscheinlich eine Seite ähnlich der in Abbildung 16-1 zu sehen bekommen - mit eingebetteter Grafik, Verweisen auf andere Seiten usw. Wenn Sie per FTP auf ein Dokument zugreifen, blicken Sie vielleicht auf das Verzeichnis-Listing eines FTP-Servers (siehe Abbildung 16-2). Mit einem Klick auf einen der Verweise in diesem FTP-Dokument übertragen Sie entweder die gewählte Datei, oder Sie listen den Inhalt eines Unterverzeichnisses auf.

Abbildung 16-2: Ein FTP-Verzeichnis, das mit dem Webbrowser Netscape Navigator angezeigt wird
Bei diesem Grad an Abstraktion brauchen wir eine Methode, einzelne Dokumente im Web zu bezeichnen. »Universal Resource Locators« (URLs) sind die Antwort auf dieses Problem. Ein URL ist einfach ein Pfadname, der ein Webdokument eindeutig bezeichnet - dazu gehören der Rechner, auf dem das Dokument zu finden ist, der Dateiname des Dokuments sowie das Zugriffsprotokoll (FTP, HTTP usw.). Ein Beispiel: Die Home-Page des Linux Documentation Project erreichen Sie unter dem URL:
http://metalab.unc.edu/LDP/index.html
Lassen Sie uns das genauer untersuchen. Der erste Teil des URLs, http:, bezeichnet das Zugriffsprotokoll für das Dokument, in diesem Fall HTTP. Der zweite Teil des URLs, //metalab.unc.edu, ideiziert den Rechner, auf dem das Dokument gespeichert ist. Der Rest des URLs, /LDP/linux.html, ist der logische Pfadname zu dem Dokument auf metalab.unc.edu. Dieser ist so ähnlich wie ein Unix-Pfadname - er bezeichnet die Datei index.html im Verzeichnis LDP. Wenn Sie also die Home-Page des LDP aufrufen wollen, starten Sie einfach Ihren Web-Client und weisen Sie ihn an, auf den URL http://metalab.unc.edu/LDP/index.html
zuzugreifen - nichts einfacher als das!
Die Konventionen der Webserver machen die Sache sogar noch einfacher. Wenn Sie als letztes Element des Pfads ein Verzeichnis angeben, dann versteht der Server, daß Sie gern die Datei index.html in diesem Verzeichnis sehen möchten. Sie können also die Home-Page des LDP auch mit folgendem kürzeren URL erreichen: http://metalab.unc.edu/LDP/
Für den Zugriff auf eine Datei per anonymem FTP können wir etwa folgenden URL benutzen: ftp://tsx-11.mit.edu/pub/linux/docs/ INFO-SHEET
Mit diesem URL holen Sie einen einführenden Text zu Linux von tsx-11.mit.edu. Die Benutzung dieses URLs in Ihrem Browser ist dasselbe wie die Übertragung der Datei von Hand, also unter Benutzung des ftp-Clients.
Der beste Weg zum Verständnis des Web ist die Erkundung desselben. Im folgenden Abschnitt besprechen wir, wie Sie mit einem Browser umgehen. Später in diesem Kapitel erklären wir, wie Sie Ihr eigenes System als Webserver konfigurieren, um dem Rest des World Wide Web Dokumente anbieten zu können.
Natürlich brauchen Sie für den Zugriff auf das Web einen Rechner mit direktem Anschluß an das Internet (per Ethernet oder SLIP). In den folgenden Abschnitten setzen wir voraus, daß Sie auf Ihrem System TCP/IP bereits konfiguriert haben und daß Sie in der Lage sind, mit Clients wie telnet und ftp zu arbeiten.
Netscape Navigator
Netscape Navigator ist einer der beliebtesten Browser. Es gibt Versionen für den Macintosh, Microsoft Windows und natürlich das X Window System auf Unix-Rechnern. Selbstverständlich gibt es eine Binärversion für Linux, die Sie auf Netscapes FTP-Archiven wie ftp://ftp.netscape.com
finden.
Netscape Navigator existiert in zwei Varianten: Zunächst gibt es das von Netscape Communications Inc. entwickelte und vertriebene Produkt, das nur in Binärform erhältlich ist, inzwischen aber (im Gegensatz zu früher) frei verteilt werden darf. Zum anderen gibt es Mozilla, gewissermaßen die »Open Source«-Version des Netscape Navigator. Netscape hat den Quellcode für die Allgemeinheit zur Verfügung gestellt, damit jeder sich unter einer der GPL ähnlichen Lizenz an der Weiterentwicklung versuchen kann, aber natürlich übernimmt Netscape für diese Version keinerlei Verantwortung. Wir werden in diesem Buch nur die »offizielle« Version von Netscape behandeln, aber Sie können alle Informationen zur Open Source-Version unter http://www.mozilla.org
finden.
Außerdem gibt es noch zwei verschiedene Versionen der von Netscape vertriebenen Software. Zunächst gibt es den Navigator, den Webbrowser allein. Außerdem gibt es Netscape Communicator, eine ganze Ansammlung von Programmen, darunter den Navigator, einen E-Mail- und einen News-Client und eine Reihe weiterer, seltener benutzter Programme. Wenn Sie nur den Webbrowser verwenden wollen, dann reicht es, sich nur das Navigator-Paket zu besorgen. Wollen Sie auch die anderen Programme benutzen, holen Sie sich das vollständige Communicator-Paket. Wir gehen im folgenden davon aus, daß Sie Communicator haben, weil dieses Paket auf den meisten Linux-Distributionen schon mitgeliefert wird. Wenn Sie Navigator haben, sollte sich aber nicht viel ändern, außer daß Sie keinen E-Mail- und News-Client haben.
Wir setzen hier voraus, daß Sie ein vernetztes Linux-System unter X benutzen und daß Sie sich eine Kopie von Netscape Navigator besorgt haben. Wir haben bereits darauf hingewiesen, daß Sie TCP/IP konfiguriert haben müssen und daß Sie in der Lage sein sollten, Clients wie telnet und ftp zu benutzen.
Der Aufruf von Netscape Navigator ist einfach; geben Sie ein:
Dabei ist url die vollständige Webadresse (oder der URL) des gewünschten Dokuments. Wenn Sie keinen URL angeben, sollte Netscape die Home-Page von Netscape anzeigen, wie in Abbildung 16-3 gezeigt, aber Sie können auch eine andere Seite bestimmen, die beim Programmstart geladen werden soll, oder einfach eine leere Seite verwenden.
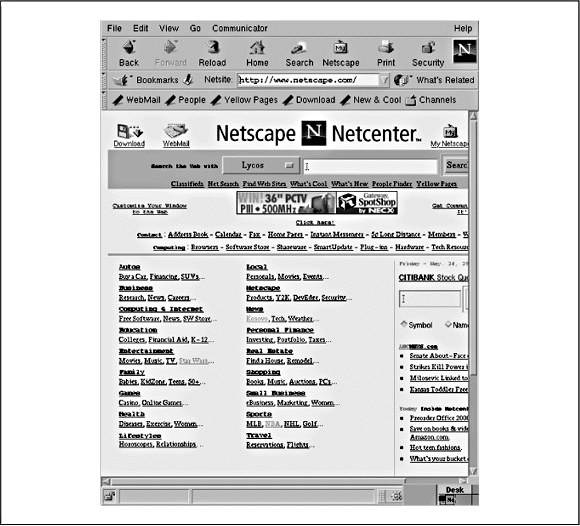
Abbildung 16-3: Die Home-Page von Netscape
Die Home-Page von Netscape ist ein guter Ausgangspunkt für eine Erkundung des World Wide Web. Sie enthält Verweise auf Informationen zu Netscape selbst sowie Demo-Dokumente, die zeigen, was das Web kann. (Im nächsten Abschnitt finden Sie ausführliche Informationen zur Navigation durch das Web.)
Während Sie Netscape Navigator benutzen, können Sie sich mit der Laufleiste am Rand des Fensters nach oben und unten durch das Dokument bewegen. Sie haben auch die Möglichkeit, mit den Tasten SPACE und DELETE seitenweise vor- und zurückzublättern; mit den Pfeiltasten scrollen Sie in kleineren Schritten durch das Dokument.
Die Links werden hervorgehoben dargestellt (auf Farbmonitoren meist in blau, auf Schwarzweißmonitoren unterstrichen). Um einem Verweis zu folgen, klicken Sie einfach mit der Maus darauf. Netscape merkt sich die Links, denen Sie schon einmal gefolgt sind; danach werden diese in einer dunkleren Farbe bzw. mit einer gepunkteten Linie unterstrichen dargestellt.
Denken Sie daran, daß die Übertragung von Dokumenten im Web manchmal sehr langsam sein kann. Das hängt von der Geschwindigkeit der Verbindung zwischen Ihrem Rechner und dem Server ebenso ab wie von der Auslastung des Netzes zum Zeitpunkt des Zugriffs. Es kann passieren, daß Webserver so überlastet sind, daß sie keine weiteren Verbindungen akzeptieren; Netscape zeigt dann eine entsprechende Fehlermeldung an. Unten im Netscape-Fenster wird der Status der Übertragung angezeigt, und solange noch Daten übertragen werden, bewegt sich das Netscape-Logo oben rechts im Fenster. Mit einem Klick auf dieses Logo kommen Sie zurück zur Home-Page von Netscape.
Wenn Sie mit Netscape Navigator den Verweisen folgen, merkt sich das Programm jedes besuchte Dokument in der »Window History«, die Sie über das Menü Go erreichen. Ein Klick auf die Schaltfläche Back am unteren Rand des Netscape-Fensters bringt Sie zu bereits besuchten Dokumenten aus der Window-History zurück; mit einem Klick auf Forward bewegen Sie sich vorwärts durch die History.
Sie können häufig besuchte Webseiten (oder URLs) in der »Bookmarks-Datei« von Netscape ablegen. Jedesmal, wenn Sie ein Dokument sehen, das Sie vielleicht später noch einmal besuchen möchten, sollten Sie den Punkt Add Bookmark aus dem Menü Bookmarks wählen. Sie können sich Ihre Bookmarks durch Öffnen des Bookmarks-Menüs anzeigen lassen. Durch Auswahl eines der Einträge laden Sie das entsprechende Dokument aus dem Web herunter.
Wir haben bereits erwähnt, daß Sie neue URLs besuchen können, indem Sie Netscape mit dem URL als Argument aufrufen. Ein anderer Weg dorthin führt über den Punkt Open Page... aus dem Menü File. Geben Sie einfach den URL in das Textfenster ein, drücken Sie ENTER, und das entsprechende Dokument wird übertragen.
Wie Sie sehen, ist Netscape Navigator eine umfangreiche Anwendung mit vielen Optionen. Es gibt zahlreiche Möglichkeiten, das Verhalten von Netscape zu beeinflussen - einige Methoden der individuellen Anpassung ändern sich allerdings von einer Version zur nächsten. Glücklicherweise stellt Netscape die komplette Netscape-Dokumentation online zur Verfügung - natürlich im Web, wo sonst? Diese Dokumentation ist über Netscapes Home-Page http://www.netscape.com
erreichbar. Neuere Versionen von Navigator enthalten die Dokumentation auch als lokale Kopie.
Netscape ist nicht der einzige Browser für Webdokumente. Das »National Center for Supercomputing Applications« (NCSA), das den ersten modernen Webbrowser, Mosaic, entwickelt hat, hat kürzlich einen modernen Nachfolger namens Vosaic herausgebracht.
|

Kapitel 11
|
Ein weiterer Browser für das X Window System, der derzeit noch nicht alle Funktionen hat, über die der Netscape Navigator verfügt, aber der schnell und einfach zu benutzen ist, ist kfm aus dem KDE-Projekt (siehe Das K Desktop Environment in Kapitel 16, Das World Wide Web und E-Mail). Mit der für Anfang 2000 angekündigten neuen Version wird kfm allerdings anderen Browsern in nichts mehr nachstehen. Noch ein anderer vielseitiger Browser ist Lynx. Es handelt sich um einen textbasierten Browser - bei der Benutzung gehen also Grafiken verloren. Dafür ist Lynx schnell und kommt Ihnen damit vielleicht entgegen. Lynx können Sie auch ohne das X Window System benutzen. Und schließlich gibt es für diejenigen, die am liebsten nie ihren geliebten Emacs verlassen, mit Emacs/W3 auch einen vollständigen Browser für GNU Emacs und XEmacs.
|
Im Web navigieren
Das Web wächst mit einer unglaublichen Geschwindigkeit. Es kann sogar sein, daß es bereits völlig anders aussieht als hier beschrieben, wenn Sie dieses Buch lesen. Seit der Einrichtung des Webs sind Hunderttausende von Webservern ans Netz gegangen.
Mit dem Anwachsen des Web auf unzählige Server in der ganzen Welt wird es immer schwieriger, die vorhandenen Informationen zu finden. Wie können Sie Informationen zu einem bestimmten Thema aufspüren, wenn Sie nicht zufälligerweise auf einen interessanten URL oder Hyperlink stoßen?
Glücklicherweise ist im Web eine Reihe von Diensten entstanden, die diese Aufgabe vereinfachen. Keiner dieser Dienste bietet eine komplette Liste aller Webserver, aber der hohe Grad der Verknüpfung innerhalb des Web trägt dazu bei, daß Sie das, was es zu finden gibt, auch wirklich finden werden.
Denken Sie immer daran, daß das Web ein dynamischer Ort ist. Wir haben uns große Mühe gegeben, nur aktuelle Informationen zu bieten, aber wenn Sie dieses Buch in Händen halten, kann es durchaus sein, daß einige dieser Links verlegt wurden oder gar nicht mehr existieren.
Ein beliebter Index von Websites ist Yahoo!, das Sie unter http://www.yahoo.com
finden, aber es gibt viele solche sogenannten »Portale«, die interessante Websites aufführen.
Eine der größten Suchmaschinen ist: http://www.altavista.com
Dort werden Millionen von Websites indiziert. Auch http://www.dejanews.com
ist interessant; hier werden News-Artikel indiziert und können durchsucht werden.
Einen eigenen Webserver einrichten
Nachdem Sie jetzt wissen, was das Web zu bieten hat, können Sie Ihre eigene Tankstelle an der Datenautobahn eröffnen. Es ist nicht schwierig, einen eigenen Webserver zu betreiben. Zwei Dinge müssen Sie tun: den httpd-Dämon konfigurieren und die Dokumente schreiben, die Sie auf dem Server anbieten möchten.
httpd ist der Dämon, der auf Ihrem System die HTTP-Anfragen bedient. Jedes Dokument, das unter einem http:-URL angesprochen wird, wird mit Hilfe des httpd bereitgestellt. Genauso werden ftp:-URLs von ftpd bearbeitet, gopher:-URLs von gopherd usw. Es gibt keinen eigentlichen Webdämon; die verschiedenen URLs benutzen verschiedene Dämonen, um beim Server Informationen anzufordern.
Es gibt verschiedene HTTP-Server. Wir besprechen hier den httpd namens Apache, der einfach zu konfigurieren und sehr flexibel ist. In diesem Abschnitt befassen wir uns mit der Installation und Konfiguration der grundlegenden Aspekte dieser httpd-Version. Später in diesem Kapitel gehen wir darauf ein, wie Sie Ihre eigenen Dokumente in HTML schreiben (der Formatierungssprache für Webseiten), und behandeln fortgeschrittene Aspekte der Server-Konfiguration wie zum Beispiel das Erstellen von interaktiven Formularen.
Der erste Schritt besteht natürlich darin, daß Sie sich eine ausführbare Datei eines httpd für Linux besorgen; eventuell ist in Ihrer Linux-Distribution bereits eine enthalten. Vergewissern Sie sich aber, daß es sich dabei wirklich um den Apache-httpd handelt und nicht um eine der älteren Versionen. Wenn Apache nicht in Ihrer Distribution enthalten ist, können Sie sich die Quellen von http://www.apache.org
herunterladen und ihn selbst kompilieren. Unter dieser Adresse finden Sie auch die vollständige Dokumentation zu Apache.
|
[40]
|
Apache - Das umfassende Referenzwerk von Ben Laurie und Peter Laurie behandelt alles, was Sie über Apache wissen müssen, darunter auch fortgeschrittene Konfigurationsmöglichkeiten.
|
Wohin die einzelnen Dateien einer Apache-Installation gehören, hängt von Ihrer Distribution oder dem installierten Paket ab, aber die folgende Liste gibt eine recht gängige Konfiguration wieder. Suchen Sie zunächst die einzelnen Bestandteile in Ihrem System, bevor Sie weitermachen:
-
/usr/sbin/httpd
-
Die ausführbare Binärdatei, also der Server selbst. Auf Debian-Systemen finden Sie diese Datei statt dessen unter /usr/sbin/apache.
-
/etc/httpd
-
Enthält die Konfigurationsdateien für httpd, insbesondere httpd.conf. Wir werden gleich besprechen, wie diese Dateien anzupassen sind. Auf Debian-Systemen finden Sie diese Dateien in /etc/apache.
-
/usr/local/httpd
-
Enthält die HTML-Skripten, die an die Clients dieses Servers übermittelt werden sollen. Dieses Verzeichnis und die darunterliegenden, gewissermaßen der Web Space, sind für jeden im Web erreichbar und stellen damit ein schwerwiegendes Sicherheitsrisiko dar, wenn sie für irgend etwas anderes als öffentliche Daten verwendet werden.
-
/var/log/httpd
-
Enthält Protokolldateien des Servers.
Unsere Aufgabe besteht jetzt darin, die Konfigurationsdateien im Konfigurations-Unterverzeichnis anzupassen. Sie sollten mindestens die folgenden vier Dateien in diesem Verzeichnis haben: access.conf-dist, httpd.conf-dist, mime.types und srm.conf-dist. Kopieren Sie die Dateien, deren Namen auf -dist enden, und passen Sie diese an Ihr eigenes System an. Ein Beispiel: Kopieren Sie access.conf-dist auf access.conf, und editieren Sie die Datei.
Die neueste Apache-Version konfiguriert sich weitestgehend selbst, aber wir zeigen Ihnen hier trotzdem, wie man den Apache manuell konfiguriert, so daß Sie sich selbst helfen können, wenn irgend etwas schiefgeht.
Unter http://www.apache.org
finden Sie die komplette Dokumentation dazu, wie httpd konfiguriert wird. Hier zeigen wir Ihnen beispielhafte Konfigurationsdateien, die zu einem in der Praxis tatsächlich so existierenden httpd gehören.
httpd.conf
Die Datei httpd.conf ist die Konfigurationsdatei des eigentlichen Servers. Kopieren Sie zuerst httpd.conf-dist nach httpd.conf, und editieren Sie die Datei. Im folgenden finden Sie ein Beispiel für eine httpd.conf-Datei mit Kommentaren zu jedem Feld.
-
# This is the main server configuration file.
# See URL http://www.apache.org for instructions.
# Do NOT simply read the instructions in here without understanding
# what they do, if you are unsure consult the online docs. You have been
# warned.
# Originally by Rob McCool. Copyright (c) 1995-1999 The Apache Group.
# All rights reserved. See http://www.apache.org/LICENSE.txt for license.
# ServerType is either inetd, or standalone.
ServerType standalone
# If you are running from inetd, go to "ServerAdmin".
# Port: The port the standalone listens to. For ports < 1023, you will
# need httpd to be run as root initially.
Port 80
# HostnameLookups: Log the names of clients or just their IP numbers
# e.g. www.apache.org (on) or 204.62.129.132 (off)
# You should probably turn this off unless you are going to actually
# use the information in your logs, or with a CGI. Leaving this on
# can slow down access to your site.
HostnameLookups on
# If you wish httpd to run as a different user or group, you must run
# httpd as root initially and it will switch.
# User/Group: The name (or #number) of the user/group to run httpd as.
# On SCO (ODT 3) use User nouser and Group nogroup
# On HPUX you may not be able to use shared memory as nobody, and the
# suggested workaround is to create a user www and use that user.
User wwwrun
Group #-2
# The following directive disables keepalives and HTTP header flushes for
# Netscape 2.x and browsers which spoof it. There are known problems with
# these
BrowserMatch Mozilla/2 nokeepalive
# ServerAdmin: Your address, where problems with the server should be
# e-mailed.
ServerAdmin mdw@zucchini.veggie.org
# ServerRoot: The directory the server's config, error, and log files
# are kept in
ServerRoot /usr/local/httpd
# BindAddress: You can support virtual hosts with this option. This
# option is used to tell the server which IP address to listen to.
# It can either contain "*", an IP address, or a fully qualified
# Internet domain name. See also the VirtualHost directive.
#BindAddress *
# ErrorLog: The location of the error log file. If this does not start
# with /, ServerRoot is prepended to it.
ErrorLog /var/log/httpd.error_log
# TransferLog: The location of the transfer log file. If this does not
# start with /, ServerRoot is prepended to it.
TransferLog /var/log/httpd.access_log
# PidFile: The file the server should log its pid to
PidFile /var/run/httpd.pid
# ScoreBoardFile: File used to store internal server process information.
# Not all architectures require this. But if yours does (you'll know
# because this file is created when you run Apache) then you *must*
# ensure that no two invocations of Apache share the same scoreboard file.
ScoreBoardFile /var/log/apache_status
# ServerName allows you to set a host name which is sent back to clients
# for your server if it's different than the one the program would get
# (i.e. use "www" instead of the host's real name).
#
# Note: You cannot just invent host names and hope they work. The name you
# define here must be a valid DNS name for your host. If you don't
# understand this, ask your network administrator.
#ServerName www.veggie.org
# CacheNegotiatedDocs: By default, Apache sends Pragma: no-cache with each
# document that was negotiated on the basis of content. This asks proxy
# servers not to cache the document. Uncommenting the following line
# disables this behavior, and proxies will be allowed to cache the
# documents.
#CacheNegotiatedDocs
# Timeout: The number of seconds before receives and sends time out
Timeout 300
# KeepAlive: Whether or not to allow persistent connections (more than
# one request per connection). Set to "Off" to deactivate.
KeepAlive On
# MaxKeepAliveRequests: The maximum number of requests to allow
# during a persistent connection. Set to 0 to allow an unlimited amount.
# We recommend you leave this number high, for maximum performance.
MaxKeepAliveRequests 100
# KeepAliveTimeout: Number of seconds to wait for the next request
KeepAliveTimeout 15
# Server-pool size regulation. Rather than making you guess how many
# server processes you need, Apache dynamically adapts to the load it
# sees --- that is, it tries to maintain enough server processes to
# handle the current load, plus a few spare servers to handle transient
# load spikes (e.g., multiple simultaneous requests from a single
# Netscape browser).
# It does this by periodically checking how many servers are waiting
# for a request. If there are fewer than MinSpareServers, it creates
# a new spare. If there are more than MaxSpareServers, some of the
# spares die off. These values are probably OK for most sites ---
MinSpareServers 5
MaxSpareServers 10
# Number of servers to start --- should be a reasonable ballpark figure.
StartServers 5
# Limit on total number of servers running, i.e., limit on the number
# of clients who can simultaneously connect --- if this limit is ever
# reached, clients will be LOCKED OUT, so it should NOT BE SET TOO LOW.
# It is intended mainly as a brake to keep a runaway server from taking
# Unix with it as it spirals down...
MaxClients 150
# MaxRequestsPerChild: the number of requests each child process is
# allowed to process before the child dies.
# The child will exit so as to avoid problems after prolonged use when
# Apache (and maybe the libraries it uses) leak. On most systems, this
# isn't really needed, but a few (such as Solaris) do have notable leaks
# in the libraries.
MaxRequestsPerChild 30
# Proxy Server directives. Uncomment the following line to
# enable the proxy server:
#ProxyRequests On
# To enable the cache as well, edit and uncomment the following lines:
#CacheRoot /usr/local/etc/httpd/proxy
#CacheSize 5
#CacheGcInterval 4
#CacheMaxExpire 24
#CacheLastModifiedFactor 0.1
#CacheDefaultExpire 1
#NoCache a_domain.com another_domain.edu joes.garage_sale.com
# Listen: Allows you to bind Apache to specific IP addresses and/or
# ports, in addition to the default. See also the VirtualHost command
#Listen 3000
#Listen 12.34.56.78:80
#
# Read config files from /etc/httpsd
#
esourceConfig /etc/httpd/srm.conf
AccessConfig /etc/httpd/access.conf
TypesConfig /etc/httpd/mime.types
Die Anweisung ServerType bestimmt, wie der Server betrieben werden soll - entweder als eigenständiger Dämon (wie in diesem Beispiel) oder von inetd aufgerufen. Aus verschiedenen Gründen empfiehlt es sich, httpd als eigenständigen Dämon zu starten; andernfalls müßte inetd für jede eingehende Verbindung einen neuen httpd starten.
Eine trickreiche Stelle ist die Angabe der Portnummer. Vielleicht möchten Sie httpd nicht als root, sondern unter der eigenen Benutzer-ID laufen lassen (wenn Sie keinen Root-Zugang zu dem betreffenden Rechner haben). In diesem Fall müssen Sie eine Portnummer oberhalb von 1024 benutzen. Wenn wir beispielsweise angeben:
können wir httpd als normaler Benutzer betreiben. In diesem Fall müssen die HTTP-URLs für dieses System folgendermaßen aussehen:
http://www.veggie.org:2112/...
Wenn im URL keine Portnummer angegeben wird (wie das meistens der Fall ist), gilt Port 80 als Voreinstellung.
srm.conf
srm.conf ist die »Server Resource Map«-Datei. Hier wird eine Reihe von Gegebenheiten konfiguriert, die den Server betreffen - etwa das Verzeichnis, in dem auf Ihrem System die HTML-Dokumente stehen, oder das Verzeichnis für die verschiedenen CGI-Binaries. Lassen Sie uns ein Beispiel für eine srm.conf Schritt für Schritt durchgehen:
-
# The directory where HTML documents will be held.
DocumentRoot /usr/local/httpd/htdocs
# Personal directory for each user where HTML documents will be held.
UserDir public_html
Hier bestimmen wir das Verzeichnis DocumentRoot, in dem die Dokumente stehen, die per HTTP angeboten werden. Diese Dokumente sind in der »HyperText Markup Language« (HTML) geschrieben. Wir besprechen diese Formatierungssprache im Abschnitt »HTML-Dokumente schreiben«.
Wenn beispielsweise jemand auf den URL http://www.veggie.org/fruits.html zugreift, wird tatsächlich die Datei /usr/local/httpd/htdocs/fruits.html angesprochen.
Die Anweisung UserDir benennt ein Verzeichnis, das jeder Benutzer in seinem Home-Verzeichnis anlegen kann, um dort öffentlich zugängliche HTML-Dateien abzulegen. Ein Beispiel: Wenn wir den URL http://www.veggie.org/~mdw/linux-info.html benutzen, wird tatsächlich auf die Datei ~mdw/public_html/linux-info.html zugegriffen.
-
# Wenn ein URL mit einem Verzeichnis, aber ohne Dateinamen eingeht, biete
# diese Datei (falls vorhanden) als Index an.
DirectoryIndex index.html
# 'Aufgepeppte' Indizes ermöglichen.
FancyIndexing on
Hier schalten wir die Indizierungsfähigkeiten von httpd ein. Dieses Beispiel bewirkt folgendes: Wenn ein Browser versucht, einen Verzeichnis-URL anzusprechen, bekommt er die Datei index.html aus diesem Verzeichnis zurück (falls vorhanden). Andernfalls wird httpd einen »aufgepeppten« Index erstellen, in dem Icons verschiedene Dateitypen symbolisieren. Abbildung 16-2 zeigt einen solchen Index.
Die Icons werden mit der Anweisung AddIcon zugeordnet, so wie hier:
-
# Auswahl der verschiedenen Icons für getürkte Indizes per Dateiname.
# Beispiel: Wir benutzen DocumentRoot/icons/movie.xbm für Dateien mit
# der Endung .mpg.
AddIcon /icons/movie.xbm .mpg
AddIcon /icons/back.xbm ..
AddIcon /icons/menu.xbm ^^DIRECTORY^^
AddIcon /icons/blank.xbm ^^BLANKICON^^
DefaultIcon /icons/unknown.xbm
Die Dateinamen der Icons (etwa /icons/movie.xbm) sind per Voreinstellung relativ zu DocumentRoot. (Es gibt andere Möglichkeiten, die Pfadnamen zu Dokumenten und Icons anzugeben - zum Beispiel mit Hilfe von Aliasnamen. Wir besprechen das später.) Sie können außerdem mit der Anweisung AddIconByType einem Dokument ein Icon abhängig vom MIME-Typ des Dokuments zuordnen und mit AddIconByEncoding ein Icon für ein Dokument auf der Basis seiner Encodierung (also ob und wie dieses komprimiert ist) angeben. Diese Encodierungen werden im Abschnitt »Ein Exkurs: MIME-Typen« besprochen.
Außerdem können Sie ein Icon angeben, das verwendet wird, wenn keine der obigen Bedingungen zutrifft. Dies geschieht mit der Anweisung DefaultIcon.
Die optionalen Anweisungen ReadmeName und HeaderName geben die Namen von Dateien an, die in den Index aufgenommen werden sollen, den httpd erzeugt.
-
ReadmeName README
HeaderName HEADER
Damit bewirken Sie, daß die Datei README.html (falls im aktuellen Verzeichnis vorhanden) an den Index angehängt wird. Wenn es diese Datei nicht gibt, wird statt dessen README angehängt. Ebenso wird eine der Dateien HEADER.html oder HEADER dem von httpd erzeugten Index vorangestellt. Sie können diese Dateien benutzen, um den Inhalt eines bestimmten Verzeichnisses zu beschreiben, wenn ein Browser einen Index anfordert.
-
# Lokale Zugriffsdatei
AccessFileName .htaccess
# Standard-MIME-Typ für Dokumente
DefaultType text/plain
Die Anweisung AccessFileName bestimmt den Namen der Datei, die den lokalen Zugriff für jedes einzelne Verzeichnis regelt. (Wir beschreiben diesen Punkt weiter unten zusammen mit der Datei access.conf.) Mit der Anweisung DefaultType bestimmen Sie den MIME-Typ für Dokumente, die nicht in mime.types aufgelistet sind. Wir gehen im Abschnitt »Ein Exkurs: MIME-Typen« genauer darauf ein.
-
# Speicherort der Icons
Alias /icons/ /usr/local/html/icons/
# Speicherort der CGI-Binaries
ScriptAlias /cgi-bin/ /usr/local/httpd/cgi-bin/
Mit der Anweisung Alias vergeben Sie einen Alias-Pfadnamen für beliebige Dokumente, die in srm.conf stehen oder per URL angesprochen werden. Weiter oben haben wir mit der Anweisung AddIcon Icon-Namen vergeben, indem wir Pfadnamen wie /icons/movie.xbm benutzt haben. Hier legen wir fest, daß der Pfadname /icons/ zu /usr/local/html/icons/ übersetzt werden soll. Die verschiedenen Icon-Dateien sollten deshalb im zuletzt genannten Verzeichnis abgelegt werden. Mit Alias können Sie auch andere Pfadnamen einstellen.
Die Anweisung ScriptAlias funktioniert ähnlich, allerdings für die aktuellen Standorte der CGI-Skripten auf dem System. In unserem Beispiel möchten wir die Skripten im Verzeichnis /usr/local/httpd/cgi-bin/ ablegen. Jedesmal, wenn ein URL benutzt wird, dessen Verzeichnisname mit /cgi-bin/ beginnt, wird dieser URL in den tatsächlichen Verzeichnisnamen übersetzt. Im Abschnitt »Ein CGI-Skript schreiben« finden Sie weitere Informationen zu CGI und Skripten.
access.conf
Die letzte Konfigurationsdatei, der Sie sich sofort zuwenden sollten, ist access.conf - das ist die übergeordnete Konfigurationsdatei für httpd-Zugriffe. Hier wird festgelegt, auf welche Dateien in welcher Weise zugegriffen werden darf. Wenn Sie diesen Punkt genauer bestimmen möchten, haben Sie auch die Möglichkeit, für jedes Verzeichnis eine lokale Zugriff-Konfigurationsdatei anzulegen. (Erinnern Sie sich, daß wir in srm.conf die Anweisung AccessFileName benutzt haben, um die lokale Zugriffsdatei für jedes Verzeichnis auf .htaccess zu setzen.)
Hier zeigen wir ein Beispiel für eine access.conf-Datei. Sie besteht aus einer Reihe von <Directory>-Punkten, von denen jeder die Optionen und Attribute für ein bestimmtes Verzeichnis festlegt:
-
# Optionen für das cgi-bin-Skript-Verzeichnis setzen.
<Directory /usr/local/html/cgi-bin>
Options Indexes FollowSymLinks
</Directory>
Hiermit bestimmen wir, daß das CGI-Skript-Verzeichnis mit den Zugriffsoptionen Indexes und FollowSymLinks versehen werden soll. Es gibt eine ganze Reihe von Zugriffsoptionen, darunter auch:
-
FollowSymLinks
-
Symbolischen Links in diesem Verzeichnis soll nachgegangen werden, um die Dokumente darzustellen, auf die die Links verweisen.
-
ExecCGI
-
Die Ausführung von CGI-Skripten aus diesem Verzeichnis heraus soll gestattet sein.
-
Indexes
-
In diesem Verzeichnis dürfen Indizes erstellt werden.
-
None
-
Alle Optionen sollen für dieses Verzeichnis abgeschaltet werden.
-
All
-
Alle Optionen sollen für dieses Verzeichnis eingeschaltet werden.
Es gibt noch weitere Optionen; schlagen Sie Details in der Dokumentation zu httpd nach.
Als nächstes schalten wir verschiedene Optionen und andere Attribute für /usr/local/httpd/htdocs ein, das Verzeichnis, in dem unsere HTML-Dokumente stehen:
-
<Directory /usr/local/httpd/htdocs>
Options Indexes FollowSymLinks
# Die lokale Zugriffsdatei .htaccess darf alle hier aufgelisteten
# Attribute außer Kraft setzen
AllowOverride All
# Zugriffsbeschränkungen für Dokumente in diesem Verzeichnis
<Limit GET>
order allow,deny
allow from all
</Limit>
</Directory>
Wir schalten hiermit die Optionen Indexes und FollowSymLinks für dieses Verzeichnis ein. Die Option AllowOverride macht es möglich, daß die lokale Zugriffsdatei in den einzelnen Verzeichnissen (.htaccess, wie in srm.conf definiert) die hier gesetzten Optionen überschreibt. Die Datei .htaccess hat dasselbe Format wie die globale Datei access.conf, bezieht sich aber nur auf das Verzeichnis, in dem sie steht. Auf diese Weise können wir die Attribute für ein bestimmtes Verzeichnis setzen, indem wir in diesem Verzeichnis eine Datei .htaccess anlegen, statt die Attribute in der globalen Datei aufzulisten.
Die lokalen Zugriffsdateien werden in erster Linie benötigt, um einzelnen Benutzern die Möglichkeit zu geben, die Zugriffsrechte für persönliche HTML-Verzeichnisse (etwa ~/public_html ) selbst zu vergeben, ohne daß der Systemverwalter die globale Zugriffsdatei ändern muß. Allerdings spielt hier die Systemsicherheit mit hinein. So könnte ein Benutzer beispielsweise die Zugriffsrechte in seinem Verzeichnis so setzen, daß beliebige Browser teure CGI-Skripten auf dem Server aufrufen können. Wenn Sie die Option AllowOverride ausschalten, haben die Benutzer keine Möglichkeit mehr, die Zugriffsattribute in der globalen Datei access.conf außer Kraft zu setzen. Sie erreichen dies mit:
was dem Ausschalten der lokalen .htaccess-Dateien gleichkommt.
Das Feld <Limit GET> wird benutzt, um Zugriffsregeln für die Browser aufzustellen, die von diesem Server Dokumente abholen möchten. In diesem Beispiel bestimmen wir order allow,deny - das bedeutet, daß allow-Regeln vor deny-Regeln ausgewertet werden sollen (Erlaubnisregeln vor Verbotsregeln). Wir stellen dann die Regel allow from all auf, die einfach besagt, daß beliebige Systeme auf die Dokumente dieses Servers zugreifen dürfen. Wenn Sie den Zugriff durch einen bestimmten Rechner oder eine bestimmte Domain verhindern möchten, sollten Sie eine Zeile wie
-
deny from .nuts.com biffnet.biffs-house.us
einfügen. Der erste Eintrag verhindert den Zugriff durch alle Rechner in der Domain nuts.com; der zweite schließt den Rechner ftp://biffnet.biffs-house.us
aus.
httpd starten
Jetzt sind Sie soweit, daß Sie httpd starten können, damit Ihr System Anfragen an HTTP-URLs bedienen kann. Wir haben bereits erwähnt, daß Sie httpd von inetd aus oder als eigenständigen Server betreiben können; wir beschreiben hier httpd als eigenständigen Server.
Sie rufen httpd ganz einfach mit dem Befehl
-
httpd -f Konfigurationsdatei
auf. Dabei ist die Konfigurationsdatei der Pfadname von httpd.conf. Ein Beispiel:
-
/usr/sbin/httpd -f /etc/httpd/httpd.conf
startet httpd mit den Konfigurationsdateien, die in /etc/httpd stehen.
Werfen Sie einen Blick in die Protokolldateien von httpd (deren Standort in httpd.conf steht); dort finden Sie alle Fehlermeldungen, die beim Starten des Servers oder beim Zugriff auf Dokumente erzeugt werden. Denken Sie daran, daß Sie httpd als root betreiben müssen, wenn ein Port mit der Nummer 1023 oder kleiner benutzt werden soll. Sobald der httpd zu Ihrer Zufriedenheit läuft, können Sie ihn beim Booten automatisch starten lassen, indem Sie die entsprechende httpd-Befehlszeile in eine Ihrer rc-Dateien einfügen (etwa /etc/rc.d/rc.local).
Moderne Versionen von Apache enthalten auch ein Hilfsprogramm namens apachectl, mit dem das Starten, Anhalten und Neuladen des httpd-Prozesses gesteuert werden kann.
Bevor Sie auf Ihrem Webserver HTTP-Dokumente anbieten können, müssen Sie diese erstellen. Diesen Schritt beschreiben wir im nächsten Abschnitt.
HTML-Dokumente schreiben
Dokumente, die per HTTP angefordert werden, können verschiedene Formate haben. Dazu gehören Grafiken, PostScript-Dateien, Sounddaten, MPEG-Videos usw. Die Konfigurationsdatei mime.types beschreibt die Dokumenttypen, die httpd handhaben kann.
Der häufigste per HTTP übertragene Dokumententyp ist die »HyperText Markup Language«-Datei (HTML-Datei). HTML-Dokumente können Text, Links zu anderen Dokumenten, eingebettete Grafik usw. enthalten. Die Mehrzahl der Dokumente, die Sie im Web zu sehen bekommen, ist in HTML geschrieben. XML, eine mächtigere Alternative, hat in der letzten Zeit viel Beachtung gefunden, aber seine Stärke liegt mehr darin, spezialisierte Webanwendungen - wie beispielsweise in mehreren Sprachen gepflegte Dokumente oder jedermanns Lieblingsschlagwort Electronic Commerce - zu unterstützen. Für traditionelle, alleinstehende Seiten ist HTML völlig ausreichend.
HTML läßt sich erstaunlich einfach erlernen. Mit Hilfe unserer Anleitung sollten Sie in weniger als einer Stunde in der Lage sein, HTML-Dokumente zu schreiben und im Web anzubieten.
Es gibt viele Tools für die Konvertierung von anderen Formatierungssprachen (z.B. , Microsoft RTF usw.) nach HTML und umgekehrt. Falls Sie besonders lange Dokumente in einer anderen Formatierungssprache vorliegen haben, die Sie im Netz anbieten möchten, ist die automatische Konvertierung nach HTML vielleicht einfacher; alternativ dazu könnten Sie die Dokumente im PostScript- oder DVI-Format anbieten.
HTML-Grundlagen
Wenn Sie bereits mit anderen Formatierungssprachen wie vertraut sind, wird HTML Ihnen im Vergleich dazu relativ einfach vorkommen. So könnte ein kleines HTML-Dokument aussehen (das - unter uns gesagt - eigentlich kein korrektes HTML ist, aber alle Browser verstehen es):
-
<html>
<head>
<title>Einführung in HTML</title>
</head>
<body>
<h1>HTML - Vergnügen und Verdienst</h1>
Obwohl das Schreiben von HTML-Dokumenten noch nicht zu den gängigen
Einnahmequellen gehört, verdienen doch viele
<em>Autoren</em> ihren Zweiturlaub damit.
<p> Und der Vorteil? Es ist soooo einfach...
</body>
</html>
Innerhalb von HTML-Dokumenten werden einzelne Elemente mit einer <markierung> eingeleitet und mit </markierung> abgeschlossen (<tag>...</tag>). Fußnoten 1
Wie Sie sehen, fängt unser Dokument mit einem Header an, der die Zeile
-
<title>Einführung in HTML</title>
enthält. Damit geben wir diesem Dokument einen Titel. Direkt danach steht ein <h1>-Element, das eine Überschrift der obersten Ebene definiert. Unter Netscape Navigator für X erscheint der Titel immer im Fenster Document Title, während die Überschrift im Dokument selbst steht.
Alle HTML-Dokumente sollten einen Titel haben, aber die Überschriften sind natürlich optional. Für HTML ist eine Überschrift einfach ein Textabschnitt, der in einer größeren und/oder fetteren Schrift gesetzt wird; sie hat keinen Einfluß auf die Struktur des Dokuments.
HTML kennt sechs Ebenen für Überschriften:
-
<h1>Überschrift der ersten Ebene</h1>
<h2>Überschrift der zweiten Ebene</h2>
...
<h6>Überschrift der sechsten Ebene</h6>
Im Anschluß an die Überschrift folgt der Textkörper des Dokuments. Wie Sie sehen, benutzen wir die Markierung <em>, um Text hervorzuheben:
-
...<em>Autoren</em> ihren Zweiturlaub damit...
Absätze werden mit der Markierung <p> eingeleitet. HTML ignoriert Leerzeilen und Einrückungen in den Dokumenten. Deshalb müssen Sie <p> benutzen, wenn Sie eine Leerzeile einfügen und mit einem neuen Absatz fortfahren möchten (anders als z.B. in , wo eine Leerzeile einen neuen Absatz einleitet).
Das Dokument betrachten
Bevor wir tiefer in HTML eintauchen, wollen wir Ihnen zeigen, wie Sie Ihr erstes Hypertext-Kunstwerk betrachten können. Die meisten Webbrowser verfügen über eine Funktion zum Betrachten lokaler Dokumente. In Netscape beispielsweise können Sie unter dem Punkt Open Page im Menü File, gefolgt von Klicken auf Choose File..., eine HTML-Datei anschauen. Andere Browser, etwa Lynx, kennen ähnliche Funktionen. Sie sollten Ihr HTML-Dokument zuerst abspeichern (z.B. in der Datei beispiel.html), bevor Sie es mit Ihrem Webbrowser betrachten.
Wenn wir unser Beispieldokument mit Netscape Navigator betrachten, sieht das Ergebnis aus wie Abbildung 16-4. Wie Sie sehen, erledigt Netscape die eigentliche »Textformatierung« für Sie - Sie müssen das Dokument nur erstellen und in Ihren Webbrowser laden.
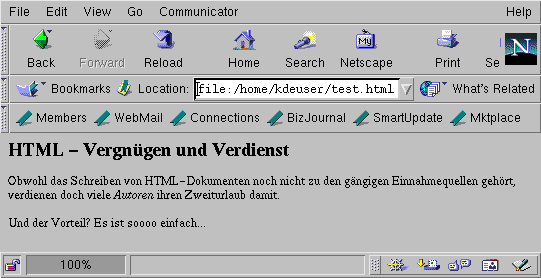
Abbildung 16-4: Beispiel-HTML-Dokument, wie es von Netscape angezeigt wird
Es ist nicht weiter schwierig, Ihre neuen HTML-Dokumente über das Web anzubieten. Wir gehen davon aus, daß Sie httpd so konfiguriert haben, wie wir das im vorhergehenden Abschnitt beschrieben haben. Legen Sie die HTML-Dateien dann im httpd-Verzeichnis DocumentRoot ab (in unserem Beispiel haben wir /usr/local/ httpd/htdocs benutzt).
Wenn Sie das Dokument als /usr/local/httpd/htdocs/beispiel.html abgelegt und auf Ihrem System den httpd gestartet haben, kann anschließend jedermann auf dieses Dokument zugreifen, indem er in seinem Webbrowser den URL
http://www.gemuese.org/beispiel.html
aufruft. (Natürlich mit dem Namen Ihres eigenen Rechners statt www.gemuese.org.)
Beachten Sie, daß Sie innerhalb des DocumentRoot-Verzeichnisses auch Unterverzeichnisse einrichten und symbolische Links anlegen können. Alle an Ihr System adressierten HTTP-URLs greifen auf Dateinamen zu, die relativ zu DocumentRoot gesucht werden. Wenn wir also das Verzeichnis /usr/local/httpd/htdocs/my-docs einrichten und beispiel.html dort ablegen, lautet der entsprechende URL: http://www.gemuese.org/my-docs/beispiel.html
Links
Damit Sie auf andere Dokumente oder andere Abschnitte desselben Dokuments verweisen können, enthalten die HTML-Quelltexte Links (Verknüpfungen, Verweise). Ein Beispiel:
-
<p> Weitere Informationen zu HTML finden Sie
<a href="http://www.w3.org/MarkUp/"> hier </a>.
Innerhalb von Netscape Navigator wird dieser Satz aussehen, wie in Abbildung 16-5 gezeigt.
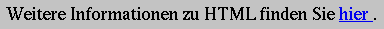
Abbildung 16-5: Anzeige eines Links in Netscape
Das Wort »hier« ist hervorgehoben, weil es ein Link ist. Nach einem Mausklick auf diesen Link wird Netscape das Dokument darstellen, auf das der URL http://www.w3.org/MarkUp/
verweist. Das Element <a> bezeichnet man als Anker - das ist ein Link, der an eine bestimmte Textstelle gebunden ist (in diesem Fall das Wort »hier«).
Man bezeichnet das oben verwendete <a>-Element als absoluten Link, weil der URL den kompletten Rechner- und Pfadnamen enthält. Für Dokumente auf demselben Rechner sollten Sie relative Links benutzen, etwa:
-
<p> Außerdem steht Ihnen die <a
href="gaertnern.html">Hobby-Gärtner-Home Page</a> zur Verfügung.
Die URLs in relativen Links werden relativ zu dem Verzeichnis verstanden, in dem das aktuelle HTML-Dokument steht. Es wird angenommen, daß der URL-Typ (z.B. http, ftp usw.) derselbe ist wie der URL-Typ des aktuellen Dokuments. Wenn der oben angeführte Text also im Dokument http://www.gemuese.org/my-docs/beispiel.html steht, verweist der Link auf den URL: http://www.gemuese.org/my-docs/gaertnern.html
Wenn der Dateiname in einem relativen Link mit einem Schrägstrich beginnt (/) wie in:
-
Klicken Sie <a href="/info/gemuese.html">here</a>, um
weitere Informationen zu erhalten.
dann wird der URL relativ zum Verzeichnis DocumentRoot aufgefaßt. In diesem Beispiel entspricht der URL also: http://www.gemuese.org/info/gemuese.html
Relative Links können auch auf das übergeordnete Verzeichnis verweisen:
-
<a href="../plants/plants.html">Hier</a> finden Sie noch
mehr über Pflanzen.
Die Benutzung von relativen Links ist für zusammengehörende Dokumente äußerst wichtig. Sie haben damit die Möglichkeit, die Verzeichnishierarchie Ihrer HTML-Dateien zu ändern, ohne daß dabei alle Ihre Links ungültig werden. Für den Zugriff auf unverknüpfte Dokumente auf demselben System empfiehlt sich allerdings die Benutzung von absoluten Links; in diesem Fall hängt die Position eines Dokuments nicht von der Position anderer Dokumente auf demselben System ab.
Sie können Links auch auf andere Abschnitte desselben Textes verweisen lassen. Ein Beispiel:
-
<a href="#Gentechnik">Weiter unten</a> finden Sie
Informationen über genetisch veränderte Pflanzen.
Der Link verweist auf eine Stelle in demselben Dokument, die folgendermaßen markiert ist:
-
<a name="Gentechnik">
<h1>Gentechnisch verändertes Gemüse: Unsere Spezialität</h1> </a>
In diesem Fall benutzt der Anker das Attribut name statt href, und der Ankertext enthält eine komplette Überschrift. Es muß nicht sein, daß Sie Überschriften als name-Anker benutzen, aber in der Regel ist das eine gute Idee, wenn Sie auf andere »Abschnitte« desselben Textes verweisen möchten. Wenn ein Benutzer beispielsweise den Link anwählt, der zu diesem Anker gehört, bekommt er am oberen Rand des Dokumentenfensters von Netscape Navigator folgende Abschnittsüberschrift zu sehen:
Gentechnisch verändertes Gemüse: Unsere Spezialität
Links können auch auf bestimmte Stellen in anderen Dokumenten verweisen. Ein Beispiel:
-
<a href="tomaten.html#Gentechnik">Hier</a> finden Sie
nähere Informationen über mutierte Tomaten.
zeigt auf den Abschnitt im Dokument tomaten.html, der mit <a name="Gentechnik"> markiert ist.
Vielleicht haben Sie schon erraten, daß Links nicht nur auf andere HTML-Dokumente verweisen können. Links können außerdem auf Bild- und Sounddateien zeigen und auf PostScript-Dateien, ebenso wie auf andere URL-Typen wie FTP-, Gopher- oder WAIS-Dienste. Kurz gesagt: Jeder gültige URL kann als Link benutzt werden. Ein Beispiel:
-
Klicken Sie <a href="ftp://ftp.gemuese.org/pub/">hier</a>,
um auf unser FTP-Archiv zuzugreifen.
ist ein Verweis auf den angegebenen FTP-URL.
Ein Exkurs: MIME-Typen
MIME steht für Multipurpose Internet Mail Extensions. Wie der Name schon andeutet, wurde MIME ursprünglich für E-Mail entwickelt. Es handelt sich dabei um einen Standard für den Transport von Dokumenten, die andere Daten außer einfachem druckbaren ASCII-Text enthalten. Nähere Informationen zu MIME-Typen finden Sie unter: http://www.w3.org/TR/REC-html40/types.html#h-6.7
Beim Verweis auf Bilder und Sounds hängt es von den Fähigkeiten des Browsers ab, welche Bild- und Soundtypen dargestellt werden können. Wenn Sie beispielsweise auf den URL http://www.gemuese.org/pics/artischocken.gif zugreifen, ist es die Aufgabe des Webbrowsers, ein eigenständiges Programm aufzurufen, das dieses Bild anzeigt. Gleichzeitig muß der Server, der das Bild anbietet, in der Lage sein, auch das Format der Bilddatei an den Browser zu übermitteln. Die Datei mime.types im Konfigurationsverzeichnis von httpd wird für diesen Zweck benutzt. Diese Datei enthält Zeilen wie beispielsweise:
-
image/gif gif
image/jpeg jpeg jpg jpe
audio/basic au snd
application/postscript ai eps ps
text/html html
text/plain txt
Das erste Feld in jeder Zeile enthält den Namen des jeweiligen MIME-Typs. Die restlichen Felder enthalten die Dateinamenssuffixe, die zu dem jeweiligen MIME-Typ passen. In diesem Beispiel werden alle Dateien, deren Name auf .gif endet, wie Dokumente vom Typ image/gif behandelt.
Wenn ein Browser (etwa Netscape Navigator) ein Dokument empfängt, bekommt er vom Server gleichzeitig Informationen über den entsprechenden MIME-Typ. Auf diesem Wege erfährt der Browser, wie er das Dokument handhaben muß. Bei text/html-Dokumenten wird Navigator einfach den HTML-Quelltext formatieren und im Dokumentenfenster anzeigen. Für image/gif-Dokumente verwendet Navigator internen Code zum Anzeigen der Grafik, für image/png wird ein externer Bildbetrachter wie etwa xv aufgerufen. Ähnlich werden Dokumente vom Typ application/postscript auf den meisten Unix-Systemen mit Hilfe von Ghostview angezeigt.
Der Webbrowser bestimmt, wie verschiedene MIME-Typen gehandhabt werden. Navigator enthält eine Option, um festzulegen, mit welchem Programm die Dokumente eines bestimmten Typs bearbeitet werden.
Die Datei srm.conf kann auch eine DefaultType-Anweisung enthalten, die angibt, welcher MIME-Typ verwendet werden soll, wenn alle anderen Typen nicht zutreffen. Wir verwenden:
Wenn der Server nicht in der Lage ist, den Typ eines Dokuments festzustellen, wird er die Voreinstellung text/plain benutzen, die für nichtformatierte Textdateien gedacht ist. Netscape zeigt solche Textdateien mit einem Literal-Font im Dokumentenfenster an.
Eingebettete Grafiken
Eine der interessanten Fähigkeiten von HTML ist das Einbetten von Grafiken direkt im Dokument. Dies wird mit dem Element <img> bewerkstelligt:
-
<img src="pics/cat.gif"> Tristessa, the Best Cat in the Universe
Damit plazieren Sie das Bild, auf das der relative URL pics/cat.gif verweist, im Dokument, wie es Abbildung 16-6 zeigt. Sie können mit <img> auch absolute URLs benutzen.
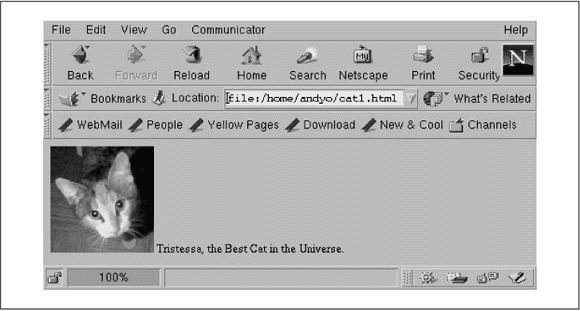
Abbildung 16-6: Eingebettete Grafik in Netscape
Theoretisch kann das Element <img> zum Einbetten von »beliebigen« Dokumenten in das aktuelle Dokument benutzt werden. In der Praxis wird es allerdings meistens für kleine Grafiken benutzt. Es hängt von den verschiedenen Browsern ab, welche Grafikformate dargestellt werden können. Bilder in den Formaten GIF und JPEG scheinen überall akzeptiert zu werden. Beachten Sie aber auch, daß nicht alle Browser in der Lage sind, eingebettete Grafiken darzustellen - in erster Linie gilt dies für textbasierte Browser wie Lynx.
Sie können <img> auch in einem Anker benutzen, etwa so:
-
<a href="cat.html">
<img src="pics/cat.gif"> Tristessa, the Best Cat in the Universe. </a>
Das macht optisch überhaupt keinen Unterschied, aber wenn der Anwender auf das Bild klickt, gelangt er zur Seite cat.html im gleichen Unterverzeichnis wie die aktuelle Seite. Um deutlich zu machen, daß es noch eine weitere Seite gibt, sollten Sie am besten sowohl das Bild als auch den Text in den Anker stellen. Das kann man durch Verschieben des </a>-Tags erreichen:
-
<a href="cat.html">
<img align="center" src="pics/cat.gif" alt="Foto der Katze">
Tristessa, the Best Cat in the Universe
</a>
Als kleine ästhetische Verschönerung (und um Ihnen zu zeigen, daß wir die Anordnung der Elemente beeinflussen können) haben wir den Text neben dem Bild zentriert, indem wir align="center" angegeben haben. Außerdem folgen wir hier Konventionen und geben einen alt-Tag an, der erklärenden Text für Leute anzeigt, die das Bild nicht sehen können - etwa blinde Leser oder Leute, die einen textbasierten Browser verwenden. Die endgültige Version unserer kleinen Seite finden Sie in Abbildung 16-7.
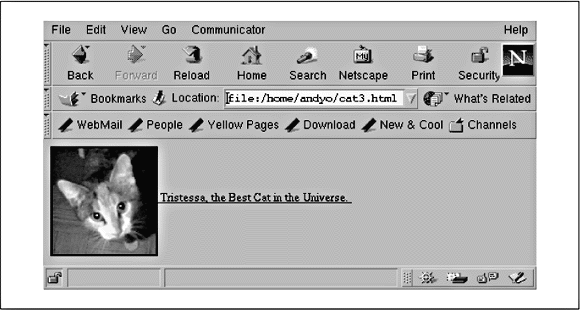
Abbildung 16-7: Bild und Link in Netscape
Weitere Eigenschaften von HTML
Offensichtlich brauchen Sie noch andere Elemente als Überschriften, Links und eingebettete Grafiken, um anspruchsvoll formatierte HTML-Dokumente zu erstellen. HTML bietet viele andere Möglichkeiten der Textformatierung.
Mit dem Element <ol> können Sie eine numerierte Liste anlegen, wobei jedes Listenelement mit <li> gekennzeichnet wird:
-
Zucchini haben folgende angenehme Eigenschaften:
<ol>
<li> Sie sind grün.
<li> Sie sind knackig.
<li> Sie schmecken großartig in Salaten.
</ol>
Nach der Formatierung durch Netscape Navigator wird diese Liste so aussehen, wie in Abbildung 16-8 gezeigt.

Abbildung 16-8: Darstellung einer Liste in Netscape
Eine Liste ohne Numerierung erstellen Sie mit <ul> statt <ol>. In nichtnumerierten Listen sind die einzelnen Listenelemente mit einem graphischen Zeichen statt mit fortlaufenden Zahlen markiert.
Sie können Listen auch verschachteln. Wenn nichtnumerierte Listen verschachtelt werden, erscheint in der Regel auf jeder neuen Ebene ein anderes graphisches Zeichen, wie in Abbildung 16-9 zu sehen ist. Der Quelltext zu dieser Liste sieht so aus:
-
Hier ist ein Beispiel für eine eingerückte Liste.
<ul>
<li> Der erste Punkt.
<li> Der zweite Punkt.
<ul>
<li> Der erste eingerückte Punkt.
<li> Noch ein Punkt.
<ul>
<li> Die nächste Stufe des Einrückens.
</ul>
</ul>
</ul>
Der Text ist hier nur eingerückt, um den Quelltext übersichtlicher zu gestalten. Benutzen Sie die Art der Einrückung, die Ihnen am meisten zusagt.

Abbildung 16-9: Verschachtelte Listen in Netscape
Es gibt verschiedene Methoden, Text hervorzuheben. Wir haben <em> bereits kennengelernt, mit dem Texte normalerweise kursiv dargestellt werden. Beachten Sie, daß es allein vom Browser abhängt, wie diese Formatierungen dargestellt werden. Die am häufigsten gebrauchten Markierungen für hervorgehobenen Text sind:
-
<em>
-
Hervorgehobener Text, meistens kursiv dargestellt.
-
<code>
-
Programmquellcode, meistens in einer Sperrschrift dargestellt.
-
<samp>
-
Beispiele für Programmausgaben, meist ebenfalls in Sperrschrift.
-
<kbd>
-
Benutzereingaben über die Tastatur.
-
<strong>
-
Starke Hervorhebung, meistens in Fettdruck dargestellt.
Hier ein Beispiel, in dem mehrere dieser Elemente benutzt werden:
-
<p> <em>Interessant</em>, dachte sie. Der
<kbd>find</kbd>-Befehl kann für fast <strong>alles</strong> verwendet werden!
Abbildung 16-10 zeigt, wie Navigator das darstellt.
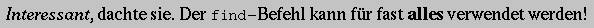
Abbildung 16-10: Fonts, wie sie von Netscape dargestellt werden
Beachten Sie, daß <code>, <samp> und <kbd> normalerweise in einer Sperrschrift (Schreibmaschinenschrift) angezeigt werden. Es ist allerdings wichtig, zwischen den verschiedenen logischen Typen der Hervorhebung in Dokumenten zu unterscheiden. So können wir nämlich den Schrifttyp ändern, mit dem <kbd>-Texte dargestellt werden (beispielsweise auf einen kursiven Schrifttyp), ohne daß gleichzeitig <code> und <samp> geändert werden müssen.
Für den Fall, daß Sie den Schrifttyp direkt bestimmen möchten, kennt HTML auch die Markierungen <b>, <i> und <tt>, um Fettdruck, kursive Schrift bzw. Literalschrift einzuschalten.
Mit dem Element <pre> haben Sie die Möglichkeit, »vorformatierten« oder »1:1«-formatierten Text in einem HTML-Dokument unterzubringen. Ein Beispiel:
-
So sieht der Quellcode von <code>hello.c</code> aus.
<pre>
#include <stdio.h>
void main() {
printf("Hallo Welt!");
}
</pre>
Dieser Text wird so dargestellt, wie in Abbildung 16-11 gezeigt.
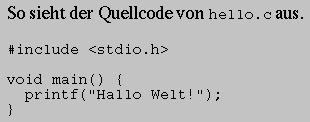
Abbildung 16-11: Vorformatierter Text in Netscape
Beachten Sie die Verwendung von < und >, um < und > darstellen zu lassen. Sie müssen diese Codes so eingeben, weil die Zeichen < und > innerhalb von HTML-Dokumenten eine besondere Bedeutung haben; dies gilt auch innerhalb von <pre>-Elementen.
Weitere Codes mit besonderer Bedeutung sind:
-
"
-
Erzeugt das doppelte Anführungszeichen: "
-
&
-
Erzeugt das Kaufmanns-Und: &
-
é
-
Erzeugt das e mit Accent aigu: é
-
ö
-
Erzeugt ein o mit Umlaut: ö;
In der kompletten HTML-Spezifikation unter http://www.w3.org/TR/REC-html40/
sind alle vorhandenen Codes aufgelistet.
Sie werden in HTML-Dokumenten häufig eine waagerechte Linie sehen, die die Seite optisch gliedert. Diese Linie ziehen Sie mit dem Element <hr>, etwa so:
-
He, Fremder, wage es nicht, diese Linie zu überschreiten: <p><hr>
<p> Nun gut, Fremder, aber wage es nicht, diese zu überschreiten: <p><hr>
Schließlich wird am Ende von HTML-Dokumenten häufig das Element <address> benutzt, um den Namen und die Adresse der Person zu hinterlegen, die für diese Seite verantwortlich ist. Ein Beispiel:
-
<p><hr><p>
<address>Mr. K. Kopf, kohl@gemuese.org</address>
Viele Leute verknüpfen den Namen innerhalb der Adresse mit ihrer persönlichen Home-Page.
Wo Sie weitere Informationen finden
Innerhalb von Netscape Navigator können Sie den HTML-Quelltext beliebiger Webdokumente betrachten. Wählen Sie im Menü View den Punkt Document Source, während Sie das betreffende Dokument lesen. Damit erhalten Sie einen Einblick, wie diese Seite erstellt wurde. Der Browser Lynx kennt eine ähnliche Option, die Sie mit dem Backslash-Befehl (\) aktivieren.
Interaktive Formulare erstellen
Wir haben bereits erwähnt, daß Netscape und der Apache-httpd auch interaktive Formulare unterstützen; diese Formulare ermöglichen Eingaben von Seiten des Benutzers (in Form von Texteingabefeldern, Schaltflächen, Menüs usw.) an ein Skript, das vom Server ausgeführt wird. Ein Beispiel: Ein interaktives Formular könnte ein Textfeld enthalten, in das der Benutzername eingegeben werden soll. Wenn dieses Formular abgeschickt wird, ruft der Server ein finger-Skript auf und präsentiert das Ergebnis als HTML-Dokument.
Es hängt von den Fähigkeiten sowohl des Webbrowsers als auch des httpd-Servers ab, ob Formulare benutzt werden können. Nicht alle Browser können Formulare darstellen, die meisten heutzutage aber schon. Außerdem können nicht alle Implementierungen des httpd mit Formularen umgehen. Wir empfehlen den Apache-httpd, den wir weiter oben in diesem Kapitel besprochen haben; darin finden Sie umfangreiche Unterstützung für Formulare.
Das Paradebeispiel für ein interaktives Formular ist eines, mit dem ein Benutzer E-Mail an den Urheber des Formulars schicken kann. In diesem Abschnitt wollen wir genau dieses Beispiel benutzen, um zu zeigen, wie man Formulare erstellt und wie die Server-Skripten aussehen, die von den Formularen ausgeführt werden. Natürlich würde es bei einem Browser, der einen eigenen E-Mail-Client enthält, ausreichen, mailto:email_adresse in die HTML-Seite zu schreiben. Aber so ein Formular könnte auch ein Bestandteil einer größeren Applikation sein. Beispielsweise wollen Sie vielleicht nicht nur Feedback per E-Mail senden, sondern auch Waren in einer Online-Shopping-Anwendung verkaufen können.
Das HTML-Formular
Der erste Schritt auf dem Weg zu einem Formular ist die Erstellung eines HTML-Dokuments, das genau wie das Formular aussieht. In solchen HTML-Seiten sind <form>-Elemente enthalten, die wiederum verschiedene andere Elemente in Form von Schaltflächen, Texteingabefeldern usw. enthalten.
Hier wollen wir einen Ausschnitt dessen darstellen, was Formulare leisten können. Ein ausführliches Beispiel für die Benutzung von Formularen findet sich unter: http://us.imdb.com/
Sie finden dort eine umfassende Datenbank mit Informationen zu mehr als 30 000 Filmen vor und können nach Titeln, Sparten, Schauspielern, Regisseuren usw. suchen.
Hier zeigen wir das HTML-Dokument für unser einfaches E-Mail-Formular:
-
1 <title>Ein triviales Mail-Formular</title>
2 <h1>Schicken Sie mir E-Mail</h1>
3 <p>Sie können dazu dieses Formular verwenden.
4
5 <p><hr><p>
6 <form method="POST" action="/cgi-bin/mailer.pl">
7 <input name="from"> Ihre E-Mail-Adresse<p>
8 <input name="subject"> Betreff<p>
9 <input type=hidden name="to" value="mdw@gemuese.org">
10 <hr>
11 Geben Sie hier den Text der E-Mail ein:<br>
12 <hr>
13 <textarea name="body" cols=60 rows=12></textarea><p>
14 <hr>
15 <input type=submit value="E-Mail abschicken"><p>
16 </form>
Wenn wir uns dieses Formular mit Netscape Navigator anschauen, sieht es aus wie Abbildung 16-12.
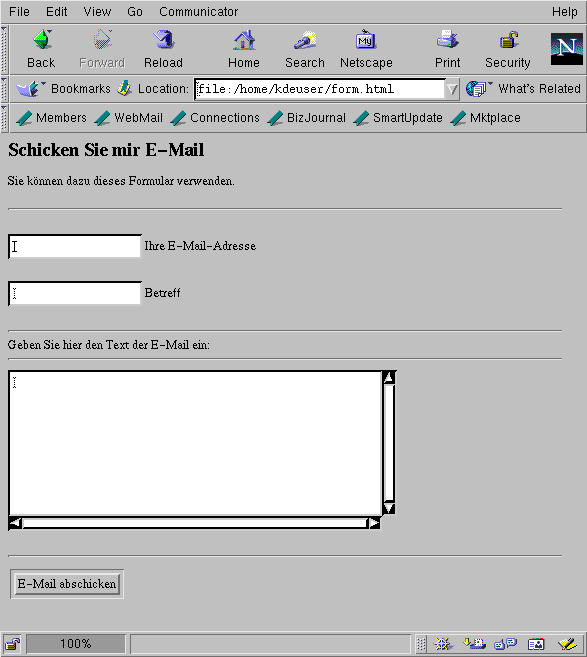
Abbildung 16-12: Formular, wie es von Netscape dargestellt wird
Wie Sie sehen, haben wir in diesem Formular einige der zusätzlichen Möglichkeiten von HTML benutzt. Lassen Sie uns die Datei Schritt für Schritt untersuchen und die Neuheiten besprechen.
In Zeile 6 steht das Element <form>, das das ganze Formular umschließt. Es gibt verschiedene Optionen und Attribute zu <form>.
Das Attribut method bestimmt, auf welche Weise Informationen aus dem Formular an das Server-Skript geschickt werden. Gültige Werte für die Methode sind GET und POST. Mit GET übergeben Sie Informationen an das Skript in Form von Befehlszeilenargumenten; mit POST richten Sie die Informationen an die Standardeingabe des Skripts. Diese Option wirkt sich lediglich darauf aus, wie Sie das Server-Skript schreiben. Aus verschiedenen Gründen empfehlen wir dringend, die Methode POST zu benutzen.
Mit dem Attribut action geben Sie den URL des Skripts an, das dieses Formular auf dem Server aufrufen wird. CGI-Skripten werden in der Regel in einem Verzeichnis namens cgi-bin, das in der ScriptAlias-Direktive in der Datei srm.conf angegeben werden muß, abgelegt.
In diesem Beispiel lassen wir das Skript
ausführen, wenn das Formular abgeschickt wird. Im nächsten Abschnitt beschreiben wir, wie dieses Skript aussehen muß.
In den Zeilen 7 bis 9 benutzen wir das Element <input>. Dies ist das Element, das in Formularen am häufigsten auftaucht - es bezeichnet eine Möglichkeit der Eingabe, wie z.B. ein Textfeld, eine Schaltfläche oder eine Checkbox. Es gibt verschiedene Attribute zu <input>.
Das Attribut name ist eine eindeutige Zeichenfolge, die dieses Element gegenüber dem Server-Skript ideiziert. Das Attribut type bezeichnet den Typ des Eingabeelements. Hier sind die gültigen Werte text, radio, checkbox, password, submit, reset oder hidden. Wenn kein type angegeben wird (wie in den Zeilen 7 und 8), wird die Voreinstellung text benutzt. Das Attribut value bestimmt den Wert, der für diese Eingabe voreingestellt werden soll.
input kennt noch verschiedene andere Attribute; damit bestimmen Sie beispielsweise die maximale Länge der Eingabe in einem Textfeld usw.
Die Zeilen 7 und 8 definieren Eingabefelder mit den Titeln from und subject, beide vom Typ text. In diese Felder werden die E-Mail-Adresse des Absenders und der Betreff der Nachricht eingetragen.
In Zeile 9 definieren wir das Element hidden mit dem Namen to; damit bestimmen wir die E-Mail-Adresse, an die diese Mail geschickt werden soll. Mit diesem Trick können wir innerhalb des HTML-Formulars selbst die E-Mail-Adresse des Empfängers angeben. Anderenfalls müßten wir die Empfängeradresse innerhalb des Server-Skripts (mailer.pl) definieren; dann müßte jeder Benutzer, der das Mail-Formular benutzen möchte, eine eigene Kopie des Skripts haben. Auf diese Weise erreichen wir, daß alle Benutzer des Systems mit diesem Skript arbeiten können, solange sie die eigene E-Mail-Adresse im Feld to angeben. Die Gründe dafür werden wir im nächsten Abschnitt darlegen, wenn wir das Skript mailer.pl selbst besprechen.
In Zeile 13 benutzen wir das Element <textarea>. Dieses Element bezeichnet ein mehrzeiliges Texteingabefeld mit Laufleisten am rechten und unteren Rand. Wie bei <input> haben wir auch hier das Attribut name benutzt, um dem Element einen Namen zuzuweisen. Mit den Attributen cols und rows legen wir die Größe dieses Textbereichs fest.
Beachten Sie, daß <textarea> im Gegensatz zu <input> auch die entsprechende Endmarkierung </textarea> in derselben Zeile benutzt. Jeglicher Text, der zwischen <textarea> und </textarea> steht, wird als festgelegter Inhalt dieses Eingabefelds betrachtet.
In Zeile 15 benutzen wir ein weiteres <input>-Element, diesmal vom Typ submit. Damit definieren wir eine Schaltfläche, die nach dem Anklicken das Formular abschickt und das zugehörige Server-Skript aufruft. Das Attribut value bezeichnet den Text, der auf der Schaltfläche angezeigt wird; in diesem Beispiel "Send mail".
In Zeile 16 schließlich beenden wir das Formular mit der Endmarkierung </form>.
|
[32]
|
Ein HTML-Dokument kann mehrere Formulare enthalten, aber die Formulare können nicht ineinander verschachtelt werden. Ein gutes Buch über HTML und HTML-Formulare ist HTML: Das umfassende Referenzwerk von Chuck Musciano und Bill Kennedy.
|
Ein CGI-Skript schreiben
Die Skripten, die von Formularen ausgeführt werden, benutzen das Common Gateway Interface (CGI), in dem festgelegt ist, wie Daten aus dem Formular an das Skript übergeben werden. Es ist an dieser Stelle nicht wichtig, daß Sie die Details der CGI-Spezifikation kennen; Sie sollten aber wissen, daß die Daten in Form von Name/Wert-Paaren an das Skript übergeben werden. Zur Demonstration: Wir gehen von unserem Beispielformular aus und nehmen an, daß der Benutzer die Adresse
in das <input>-Feld mit dem Namen from eingetragen hat. Der Wert bsmarks@norelco.com wird dann bei der Übergabe an das Skript mit dem Namen from verknüpft.
Wir haben bereits erwähnt, daß es von der Formularmethode abhängt, auf welche Weise diese Name/Wert-Paare an das Server-Skript übergeben werden (GET oder POST). Ganz allgemein werden die Name/Wert-Paare in folgender Form codiert:
-
action?name=val&name=val&...
und entweder auf der Befehlszeile (bei Formularen mit der Methode GET) oder als Standardeingabe (bei Formularen mit der Methode POST) an das Server-Skript übergeben. Außerdem müssen bestimmte Zeichen (etwa =, & usw.) mit Escape-Codes versehen werden, und verschiedene Umgebungsvariablen übergeben bestimmte Werte an das Skript.
Server-Skripten können in praktisch jeder Sprache geschrieben werden, etwa C, Perl oder sogar als Shell-Skripten. Da die Decodierung der Name/Wert-Paare in einem C-Programm ziemlich qualvoll werden kann, zeigen wir statt dessen, wie ein solches Skript in Perl geschrieben wird, dessen Fähigkeiten zur Textbearbeitung für diese Aufgabe besser geeignet sind.
Das folgende Beispiel zeigt das Perl-Skript mailer.pl. Stellen Sie dieses Skript in das Verzeichnis, das Sie bei der Konfigurierung des Systems für CGI-Skripten vorgesehen haben.
-
#!/usr/bin/perl
use CGI qw(:standard);
print header(), start_html( "E-Mail-Formular" ),\
h1( "E-Mail-Formular" );
my $to = parse( "to" );
my $from = parse( "from" );
my $subject = parse( "subject" );
my $body = parse( "body" );
open (MAIL,"|/usr/lib/sendmail $to") ||
die "<p>Error: Konnte sendmail nicht ausführen.\n";
print MAIL "To: $to\n";
print MAIL "From: $from\n";
print MAIL "subject: $subject\n\n";
print MAIL "$body\n";
close MAIL;
print p( "Alles klar, folgendes wurde an <tt>$to</tt> geschickt:" );
print p( "<pre>\nTo: $to\nFrom: $from\nsubject:\
$subject\n\n$body\n</pre>" );
print end_html();
|
Kapitel 13
|
Falls Sie Perl-Neuling sind, schauen Sie sich die Einführung in Kapitel 13 an. Sie müssen aber kein absoluter Perl-Freak sein, um diesen Code zu verstehen.
|
Dieses Skript lädt zunächst das Modul CGI.pm, das seit Perl 5.004 in der Perl-Distribution enthalten ist und Ihnen sehr dabei helfen wird, wenn es darum geht, CGI-Skripten zu schreiben. Wir verwenden daraus zunächst die Methoden header(), start_html() und h1(), um den Header zu schreiben, der die wichtige Zeile
enthält, mit der der Server informiert wird, was für einen MIME-Typ die Daten aus diesem Skript haben, und die ihn anweist, den HTML-Code zu beginnen. Mit CGI.pm müssen Sie sich nicht einmal über die HTML-Syntax Gedanken machen.
Nach der Ausgabe dieser ersten Zeilen verwenden wir die Routine parse() aus CGI.pm, die die an das CGI-Skript übergebenen Parameter parst. Das klingt jetzt nicht nach besonders viel, aber tatsächlich ist es reichlich schwierig, diese Parameter zu parsen, weil so viele Sonderfälle beachtet werden müssen. An parse müssen Sie einfach nur den Namen des Parameters übergeben und sich den Wert zurückholen.
Das Skript öffnet anschließend eine Pipe nach /usr/lib/sendmail, das die Mail verschicken soll. (Falls Sie auf Ihrem System ein anderes Mail-Programm als sendmail benutzen, muß diese Stelle angepaßt werden.) Wir leiten die Nachricht dann an sendmail, nachdem wir einen Header vorangestellt haben, der die Felder To:, From: und Subject: enthält, die wir aus dem Formular gewonnen haben.
Beachten Sie, daß hier ein Sicherheitsrisiko entsteht, wenn sendmail wie gezeigt verwendet wird, weil Sie nicht wissen, was in der Variablen $to steht. Außerdem ist diese Technik nicht besonders portabel. In einem System, das tatsächlich in Betrieb ist, würden Sie vermutlich das Perl-Modul Mail::Mailer verwenden, um die E-Mail zu verschicken, aber weil das nichts mit CGI-Skripten zu tun hat, gehen wir darauf nicht weiter ein.
Nachdem wir die Pipe zu sendmail geschlossen haben, geben wir die gerade übertragene Nachricht noch auf die Standardausgabe - als Hinweis für den Benutzer, daß die Nachricht korrekt verschickt wurde. Wieder verwenden wir die Methode p() aus CGI.pm, um den HTML-Code auszugeben. Schließlich benutzen wir end_html(), um die HTML-Tags korrekt zu schließen.
Denken Sie immer daran, daß bei der Benutzung von HTML-Formularen auch die Systemsicherheit eine Rolle spielt. Stellen Sie sicher, daß Ihre Skripten nicht benutzt werden können, um auf Ihrem System nichtautorisierte Prozesse zu starten. Wenn Ihre Server-Skripten die CPU stark beanspruchen, sollten Sie den Zugriff vielleicht einschränken, um das System nicht zu überlasten. Ganz allgemein gesagt: Sie sollten wissen, was Sie tun, wenn Sie auf Ihrem Webserver Formulare anbieten.
Fußnoten 1
-
HTML ist eigentlich eine »Document Type Definition« in der »Standard Generalized Markup Language« (SGML). SGML definiert die Regeln für die <markierung>...</markierung>-Paare.
Weitere Informationen zum Linux - Wegweiser zur Installation & Konfiguration
Weitere Online-Bücher & Probekapitel finden Sie in
unserem Online Book Center
O'Reilly Home |
O'Reilly-Partnerbuchhandlungen |
Bestellinformationen |
Kontaktieren Sie uns
International |
Über O'Reilly |
Tochterfirmen
© 2000, O'Reilly Verlag



